
[AI 기초수학 2편] 평균·분산·로그 — AI가 데이터를 읽는 법
AI가 데이터를 보는 눈, 평균과 분산으로 시작합니다. 거기에 로그까지 더하면 AI 손실함수의 기초가 완성돼요. 레오파드게코 모프 분류 예시로 직접 돌려봅시다.
시작하며 — AI가 데이터를 보는 눈
지난 편에서 연립방정식을 NumPy로 풀어봤습니다.
이번엔 조금 더 나아가서, AI가 데이터를 어떻게 "읽는지" 함께 알아봅시다.
AI 모델을 학습시킬 때 가장 먼저 하는 일이 뭘까요?
바로 데이터를 요약하는 것입니다.
수백만 개의 숫자를 그대로 볼 순 없으니까요.
그 핵심 도구가 바로 평균·분산이고,
여기에 로그까지 더하면 AI 손실함수의 기초가 완성됩니다.
같이 직접 돌려봅시다!
평균은 왜 중요한가요?
평균은 데이터 전체를 하나의 대표값으로 요약해주는 가장 기본적인 통계량이에요. AI 모델이 데이터를 학습할 때 가장 먼저 파악하는 것이 데이터의 중심이 어디인지인데, 그게 바로 평균입니다. NumPy에서는 np.mean() 한 줄이면 돼요.
평균은 다들 아시죠. 전부 더해서 개수로 나누는 것.
NumPy로는 np.mean() 한 줄이면 됩니다.
도마뱀 체중 기록 데이터로 직접 해봅시다.
import numpy as np
# 도마뱀 체중 기록 (단위: g)
weights = np.array([21, 23, 25, 24, 26, 28, 27, 30, 29, 31])
mean = np.mean(weights)
var = np.var(weights)
std = np.std(weights)
print(f"평균 체중: {mean:.1f}g")
print(f"분산: {var:.2f}")
print(f"표준편차: {std:.2f}g")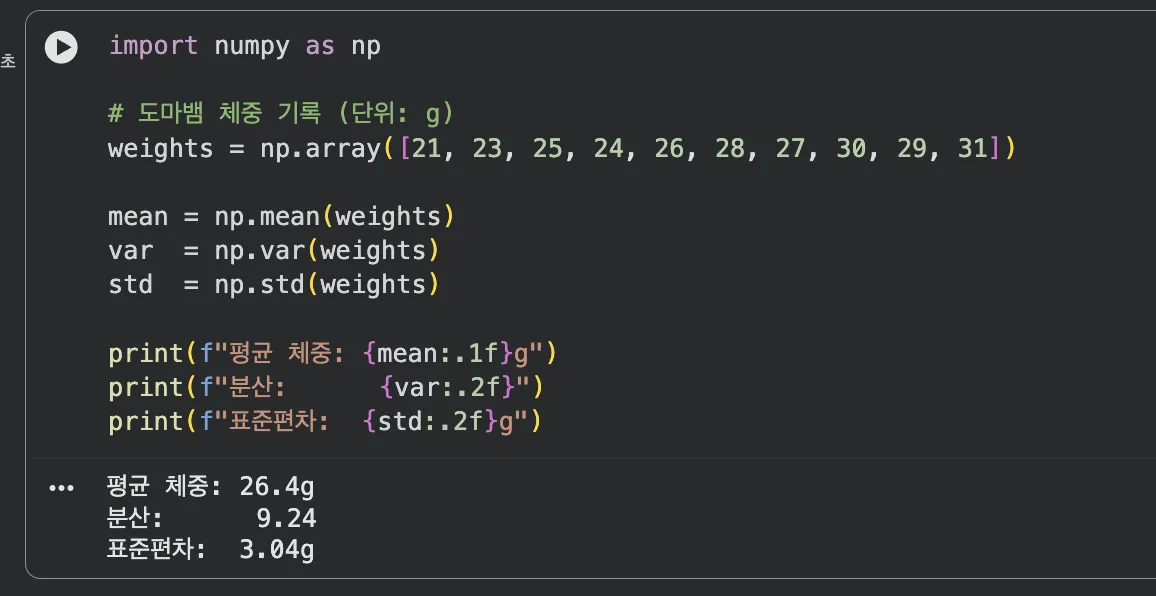
np.mean(), np.var(), np.std() 한 번에 실행한 결과
분산과 표준편차는 뭘 알려주나요?
평균만으로는 부족합니다.
평균이 같아도 데이터의 모양은 완전히 다를 수 있거든요.
예를 들어볼게요. 두 개체의 체중 기록입니다.
# 안정적인 개체 vs 불안정한 개체 비교
stable = np.array([25, 25, 26, 25, 26, 25]) # 꾸준히 크는 개체
unstable = np.array([18, 30, 20, 35, 19, 32]) # 들쭉날쭉한 개체
print("=== 안정적인 개체 ===")
print(f" 평균: {np.mean(stable):.1f}g, 표준편차: {np.std(stable):.2f}g")
print("=== 불안정한 개체 ===")
print(f" 평균: {np.mean(unstable):.1f}g, 표준편차: {np.std(unstable):.2f}g")
print("\n→ 평균은 비슷해도 표준편차가 크면 데이터가 흩어져 있다는 뜻!")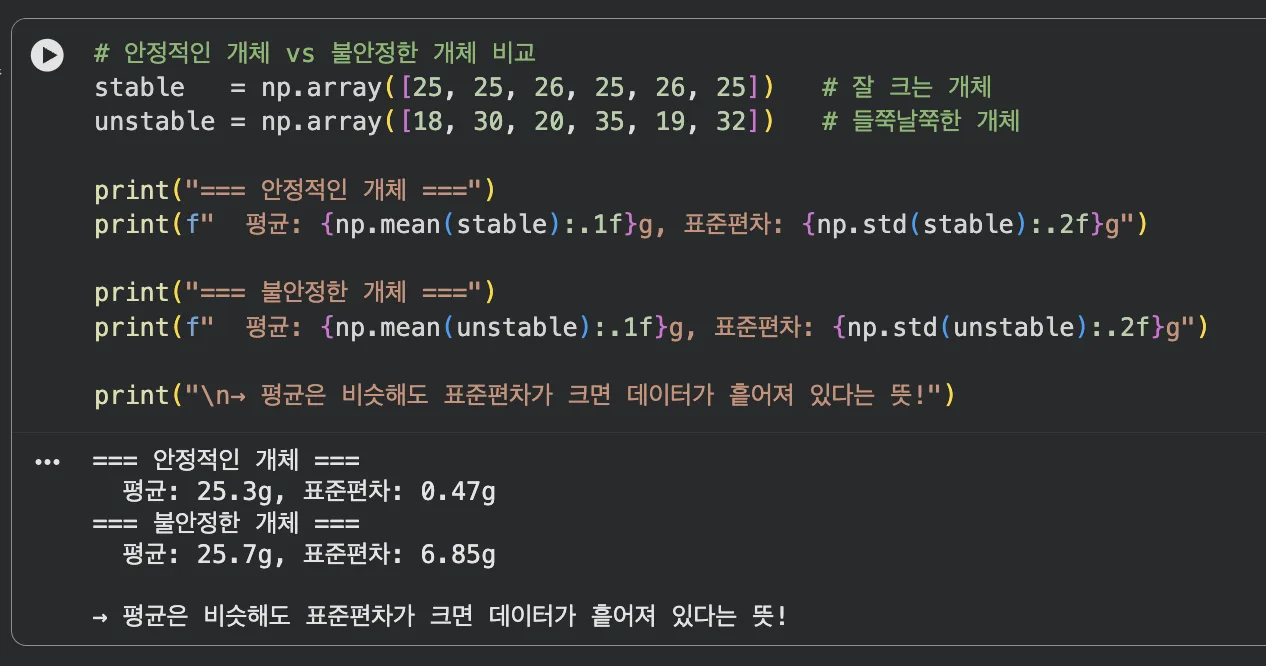
평균은 비슷해도 표준편차가 다르면 데이터의 모양이 전혀 다르다
AI 모델에서도 같습니다.
분산이 크다 = 데이터가 넓게 퍼져 있다 = 모델이 배워야 할 범위가 넓다.
분산이 작다 = 데이터가 몰려 있다 = 더 예측하기 쉽다.
로그는 왜 필요한가요?
갑자기 로그가 왜 나오냐고요? ㅎㅎ
AI에서 로그는 생각보다 훨씬 자주 등장합니다.
이유는 하나입니다. 아주 크거나 아주 작은 숫자를 다루기 편하게 만들기 위해서요.
NumPy로 먼저 기본부터 돌려봅시다.
# numpy.log() 기본 사용 (자연로그, 밑=e)
print(f"log(1) = {np.log(1):.4f}")
print(f"log(e) = {np.log(np.e):.4f}")
print(f"log(10) = {np.log(10):.4f}")
print(f"log2(8) = {np.log2(8):.4f}")
print(f"log10(1000) = {np.log10(1000):.4f}")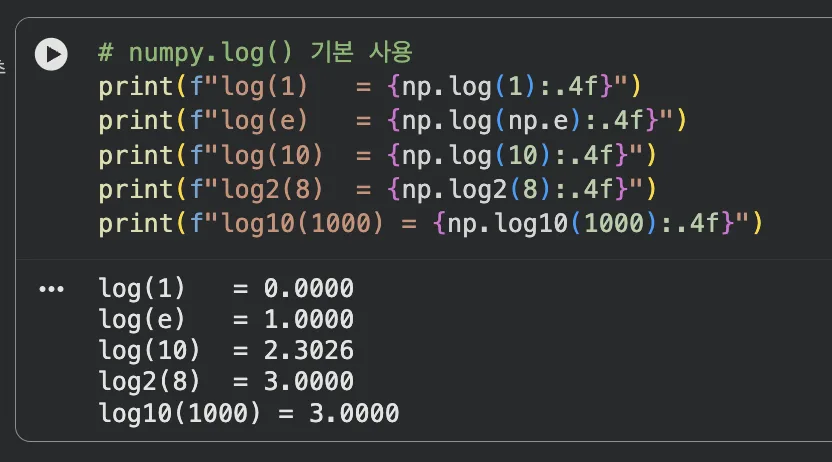
자연로그, log2, log10 각각 실행한 결과
로그의 핵심 성질은 뭔가요?
고등학교 때 배운 로그 성질, 기억하시나요?
코드로 직접 검증해 봅시다.
log(a × b) = log(a) + log(b)
log(a ÷ b) = log(a) − log(b)
a, b = 6, 4
print("=== 로그의 성질 검증 ===")
# 곱의 로그 = 로그의 합
print(f"log(a×b) = {np.log(a*b):.6f}")
print(f"log(a)+log(b) = {np.log(a)+np.log(b):.6f}")
print(f"같음? {np.isclose(np.log(a*b), np.log(a)+np.log(b))}")
print()
# 몫의 로그 = 로그의 차
print(f"log(a/b) = {np.log(a/b):.6f}")
print(f"log(a)-log(b) = {np.log(a)-np.log(b):.6f}")
print(f"같음? {np.isclose(np.log(a/b), np.log(a)-np.log(b))}")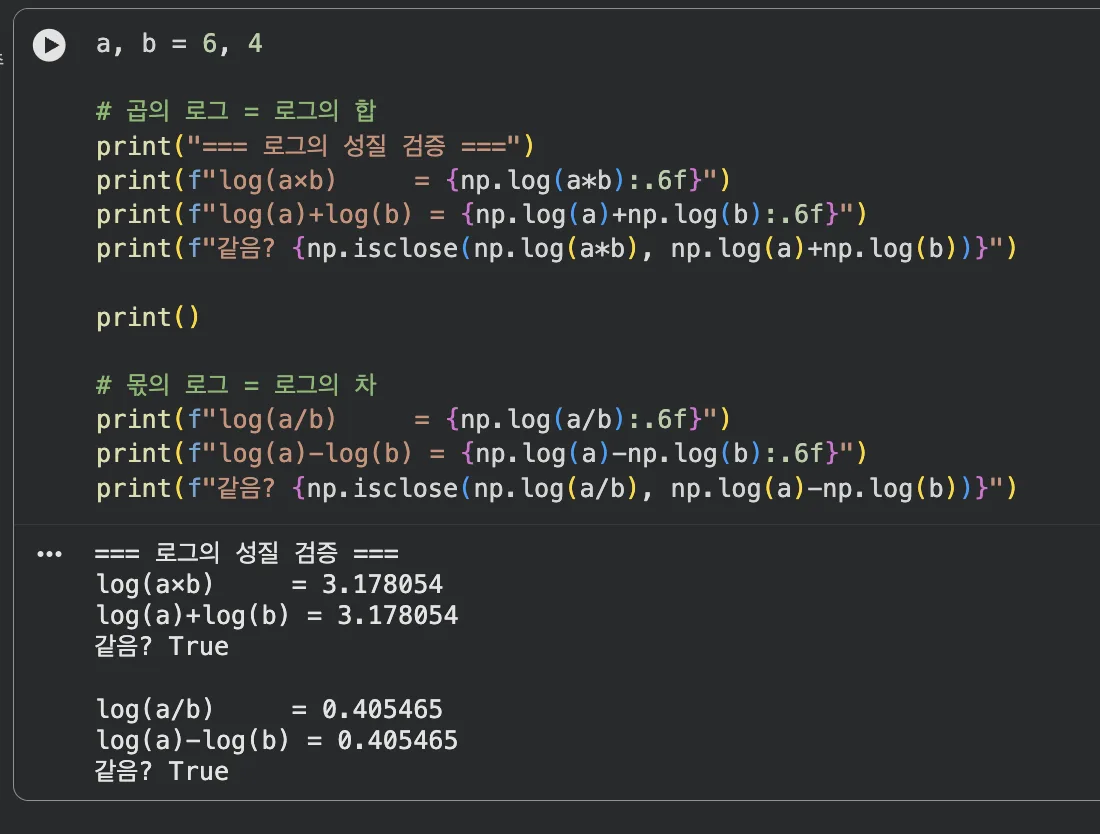
두 계산 모두 True — 로그 성질이 코드로도 성립함을 확인
이 성질이 왜 중요할까요?
AI에서 확률을 수백만 번 곱하다 보면 숫자가 0에 가까워져서 컴퓨터가 처리를 못 합니다.
로그를 쓰면 곱셈이 덧셈으로 바뀌어서 훨씬 안정적으로 계산할 수 있어요.
AI 손실함수에 로그가 왜 들어가나요?
AI 모델이 예측을 틀렸을 때 "얼마나 틀렸는지" 측정하는 게 손실함수입니다.
그 안에 바로 -log(예측 확률)이 들어가 있어요.
레오파드게코 사진을 보고 AI가 모프를 분류하는 상황을 생각해봅시다.
정답은 블랙나이트인데, AI가 각 모프일 확률을 이렇게 예측했다면?
# 레오파드게코 모프 분류 AI — 손실함수 실습
# AI 예측 확률 [블랙나이트, 알비노, 스노우]
predictions = np.array([0.75, 0.15, 0.10])
correct_idx = 0 # 정답은 블랙나이트 (인덱스 0)
# 크로스 엔트로피 손실: -log(정답 클래스 확률)
loss = -np.log(predictions[correct_idx])
print("=== 블랙나이트 분류 손실 계산 ===")
print(f"정답(블랙나이트) 예측 확률: {predictions[correct_idx]}")
print(f"손실값 (-log): {loss:.4f}")
print()
# 예측 확률이 달라지면 손실이 어떻게 바뀌는지 확인
print("예측 확률별 손실값 변화:")
for p in [0.95, 0.75, 0.5, 0.1, 0.01]:
print(f" 블랙나이트 확률 {p:.2f} → 손실 {-np.log(p):.4f}")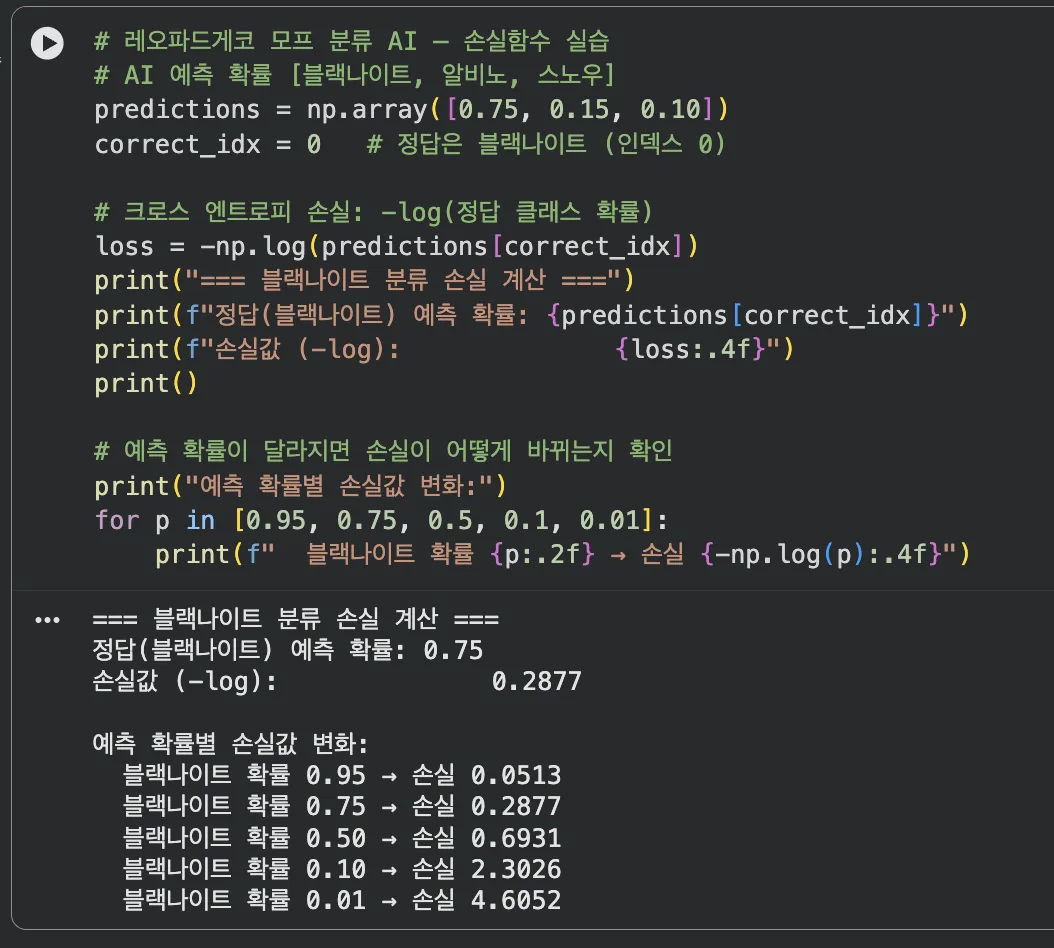
블랙나이트를 맞힐 확률이 낮을수록 손실값이 급격히 커짐을 확인
블랙나이트를 95% 확률로 맞히면 손실이 작고,
1% 확률로 예측하면 손실이 폭발적으로 커집니다.
AI 모델이 틀릴수록 더 강하게 "패널티"를 주는 구조예요.
그게 바로 로그가 손실함수에 있는 이유입니다.
정리
np.mean(),np.var(),np.std()로 데이터를 한 줄에 요약할 수 있습니다- 평균이 같아도 표준편차가 다르면 데이터의 모양은 완전히 다릅니다
- 로그는 큰 숫자·작은 확률을 다루기 쉽게 만들어줍니다
- AI 손실함수의
-log(p)는 "틀릴수록 더 크게 벌준다"는 원리입니다
다음 편에서는 확률 — AI가 예측하는 법을 함께 알아봅니다.
이산 확률부터 정규분포, 조건부 확률까지 NumPy로 직접 돌려볼 거예요. ㅎㅎ