
[AI 기초수학 3편] 확률 — AI가 예측하는 법
AI는 정답을 모릅니다. 대신 가장 확률 높은 답을 고릅니다. 이산 확률부터 정규분포, 조건부 확률, softmax까지 NumPy로 직접 돌려봅시다.
시작하며 — AI는 "확실한 답"을 모릅니다
AI에 대해 흔히 오해하는 게 하나 있습니다.
"AI는 정답을 알고 있다"는 생각이요.
사실 AI는 정답을 모릅니다.
대신 "가장 확률 높은 답"을 고릅니다.
그래서 확률을 이해하면 AI가 어떻게 생각하는지 보이기 시작해요.
이번 편에서는 이산 확률부터 정규분포, 조건부 확률까지
NumPy로 직접 돌려보면서 함께 알아봅시다!
이산 확률과 기댓값이란 뭔가요?
이산 확률은 주사위 눈처럼 딱 떨어지는 경우의 수가 있는 확률이고, 기댓값은 각 경우에 확률을 곱해서 합산한 "평균적으로 기대되는 값"이에요. AI가 예측 결과의 평균 성능을 계산할 때 이 기댓값 개념이 기초가 됩니다.
이산 확률은 딱 떨어지는 경우의 수가 있는 확률입니다.
주사위 눈, 동전 앞뒷면처럼요.
여기서 중요한 개념이 하나 나옵니다. 기댓값.
"평균적으로 기대할 수 있는 값"인데, NumPy로 이렇게 계산합니다.
import numpy as np
# 주사위 1개 던지기 — 각 눈이 나올 확률
faces = np.array([1, 2, 3, 4, 5, 6])
probs = np.array([1/6] * 6)
print("=== 주사위 확률 분포 ===")
for f, p in zip(faces, probs):
print(f" {f}이 나올 확률: {p:.4f}")
# 기댓값 (각 값 × 확률을 모두 더함)
expected = np.sum(faces * probs)
print(f"\n기댓값(평균): {expected:.4f}")
# 동전 앞면 확률
coin = np.array([0, 1])
coin_probs = np.array([0.5, 0.5])
print(f"\n동전 앞면 기댓값: {np.sum(coin * coin_probs):.1f}")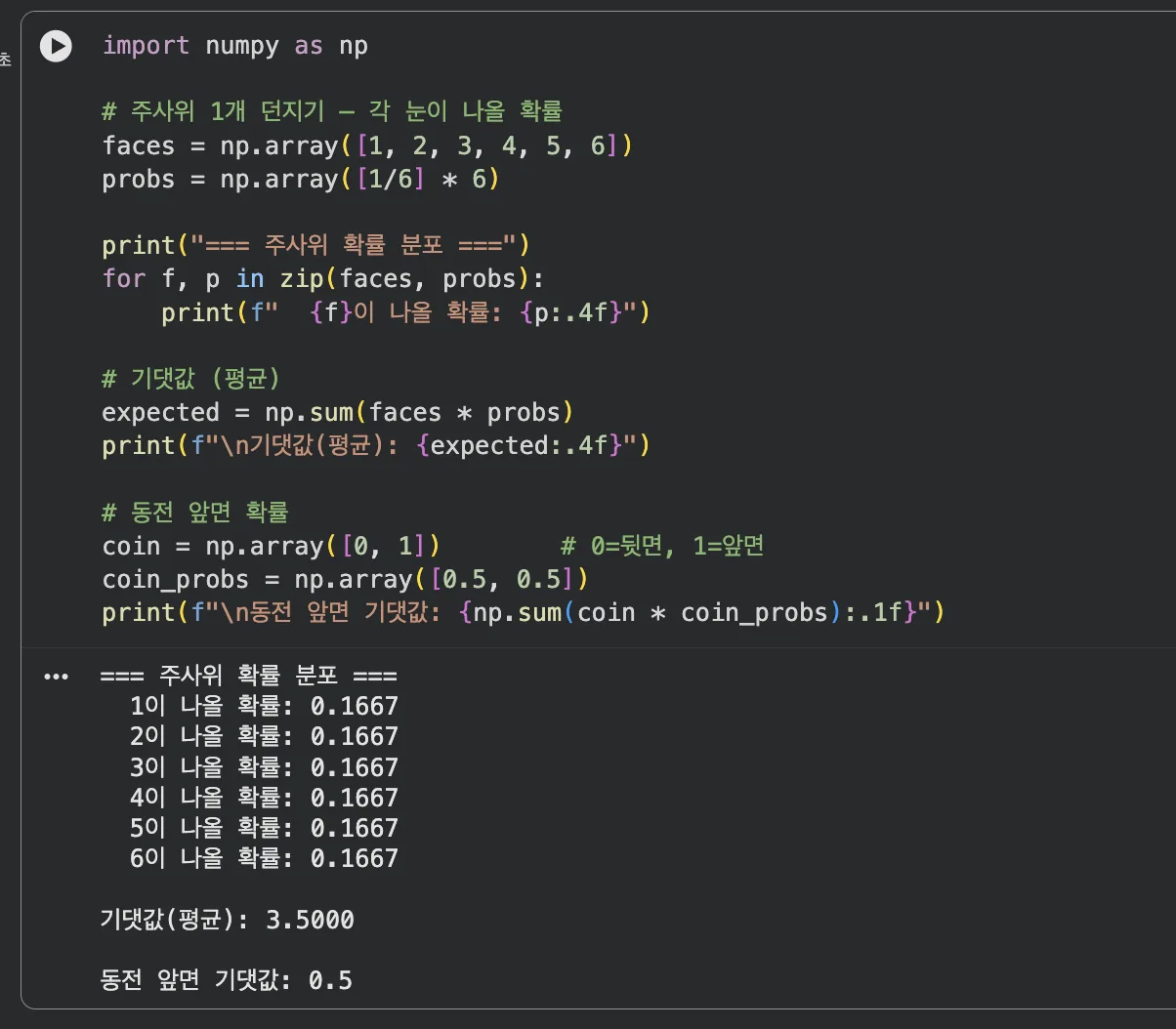
주사위 기댓값 3.5 — 어떤 눈도 아니지만, 평균적으로 기대되는 값
기댓값 3.5는 실제로 나오지 않는 숫자지만,
수백 번 던지면 평균이 3.5에 가까워집니다.
AI도 이런 식으로 "확률로 평균적인 답"을 예측해요.
표준 정규분포가 AI에서 왜 중요한가요?
연속 확률 분포 중에서 가장 중요한 게 정규분포입니다.
종 모양의 그래프, 한번쯤 보셨을 거예요.
표준 정규분포는 그 중에서도 평균=0, 표준편차=1인 특별한 경우입니다.
NumPy로 직접 생성하고 특성을 확인해 봅시다.
# 표준 정규분포 난수 생성
np.random.seed(42)
data = np.random.normal(loc=0, scale=1, size=10000)
print("=== 표준 정규분포 특성 확인 ===")
print(f"생성된 데이터 수: {len(data)}개")
print(f"평균: {np.mean(data):.4f} (이론값: 0)")
print(f"표준편차: {np.std(data):.4f} (이론값: 1)")
print(f"최솟값: {np.min(data):.4f}")
print(f"최댓값: {np.max(data):.4f}")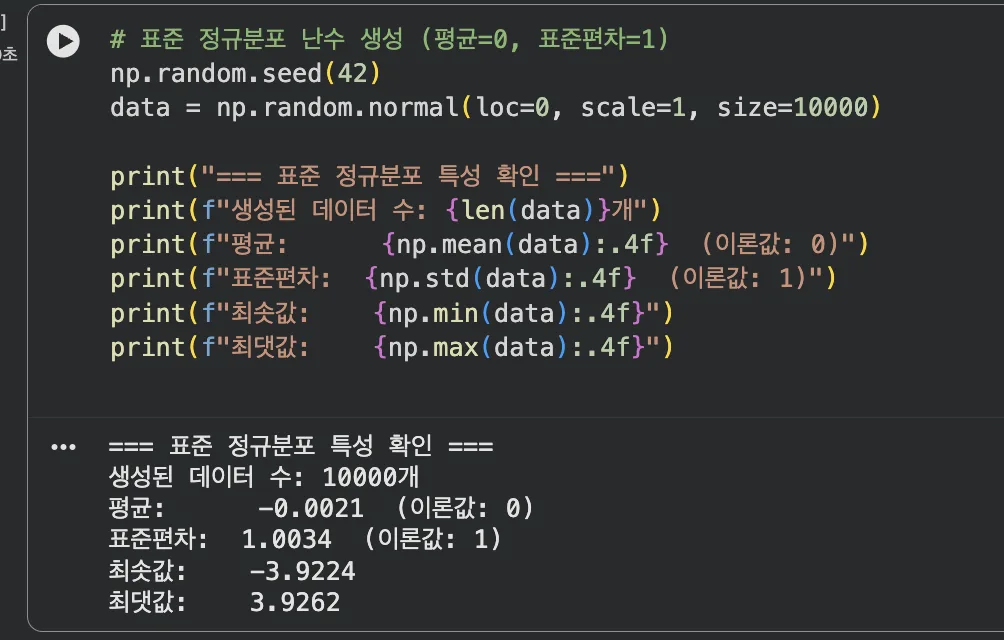
10,000개 난수의 평균은 0에, 표준편차는 1에 수렴한다
AI 신경망을 처음 만들 때 가중치(weight)를 어떤 값으로 초기화할까요?
바로 이 표준 정규분포에서 뽑은 난수를 씁니다.
너무 크지도, 너무 작지도 않은 값으로 시작하기 위해서예요.
조건부 확률은 뭔가요?
조건부 확률은 어떤 사건이 일어났을 때,
다른 사건의 확률이 어떻게 바뀌는지를 계산합니다.
레오파드게코 부화 예시로 같이 풀어봅시다.
암컷이 부화할 확률: 60%
암컷이 건강할 확률: 90%
수컷이 건강할 확률: 80%
→ 건강하게 부화한 개체가 암컷일 확률은?
P_female = 0.6
P_male = 0.4
P_healthy_given_female = 0.9
P_healthy_given_male = 0.8
# 전체 건강 확률 (전체 확률의 법칙)
P_healthy = P_healthy_given_female * P_female + P_healthy_given_male * P_male
print(f"전체 건강 부화 확률: {P_healthy:.2f}")
# 베이즈 정리: P(암컷|건강) = P(건강|암컷) × P(암컷) / P(건강)
P_female_given_healthy = (P_healthy_given_female * P_female) / P_healthy
print(f"건강한 개체가 암컷일 확률: {P_female_given_healthy:.4f}")
print(f"건강한 개체가 수컷일 확률: {1 - P_female_given_healthy:.4f}")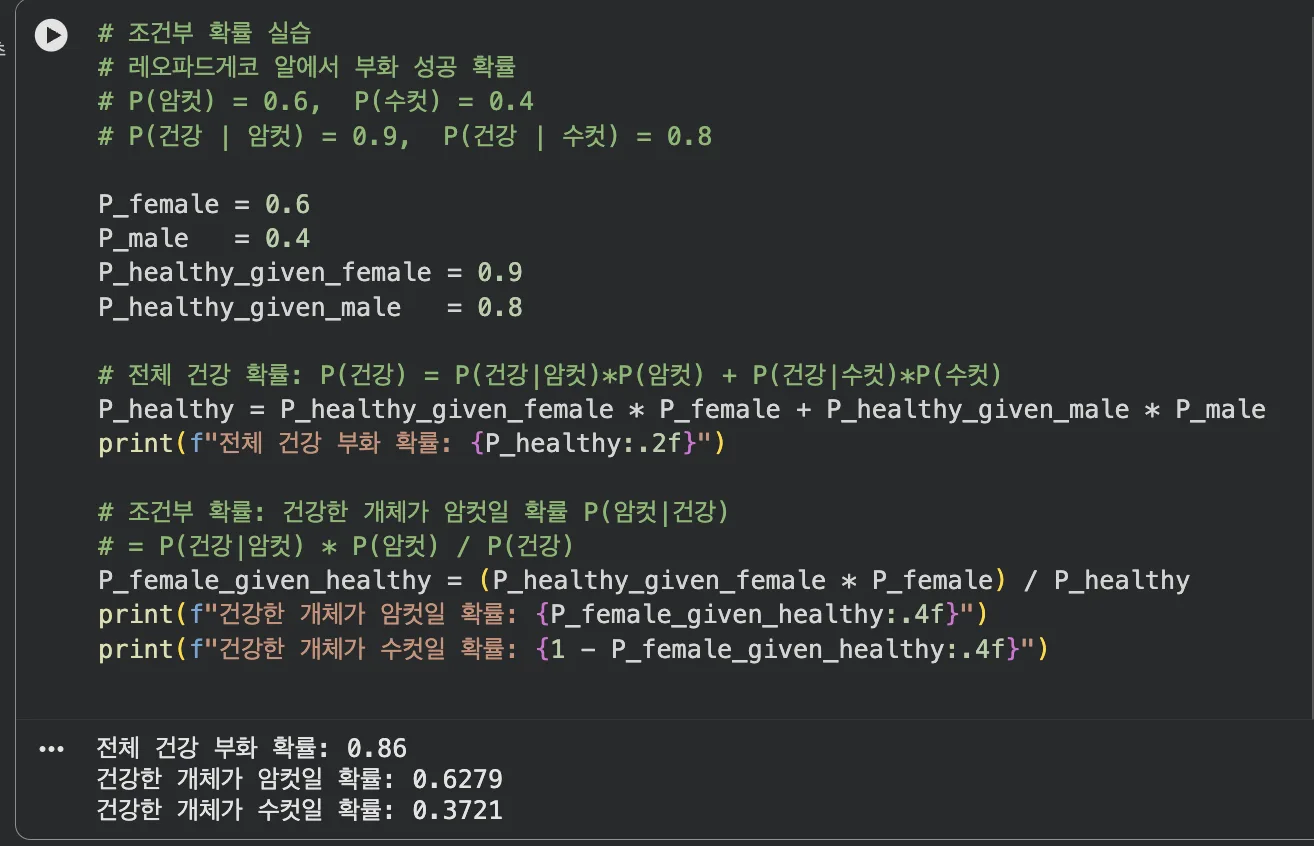
베이즈 정리로 "건강하다"는 조건이 주어졌을 때 성별 확률을 계산
이게 바로 베이즈 정리입니다.
AI의 나이브 베이즈 분류기, 스팸 필터, 의료 진단 AI 모두 이 원리로 돌아가요.
"새로운 정보가 들어오면 기존 확률을 업데이트한다" — AI가 학습하는 방식과 정확히 같습니다.
softmax는 AI 예측에서 어떤 역할을 하나요?
AI 분류 모델이 최종적으로 내놓는 건 항상 확률입니다.
원시 점수(raw score)를 확률로 변환하는 함수가 바로 softmax예요.
레오파드게코 모프 분류로 직접 확인해 봅시다.
# AI 모프 분류: 원시 점수 → 확률로 변환 (softmax)
raw_scores = np.array([3.2, 1.1, 0.5]) # [블랙나이트, 알비노, 스노우]
def softmax(x):
e = np.exp(x - np.max(x)) # 수치 안정화
return e / e.sum()
probs = softmax(raw_scores)
labels = ["블랙나이트", "알비노", "스노우"]
print("=== AI 모프 분류 확률 ===")
for label, p in zip(labels, probs):
print(f" {label}: {p:.4f} ({p*100:.1f}%)")
print(f"\n확률 합계: {probs.sum():.4f} ← 항상 1이 됩니다")
print(f"AI 예측 결과: {labels[np.argmax(probs)]}")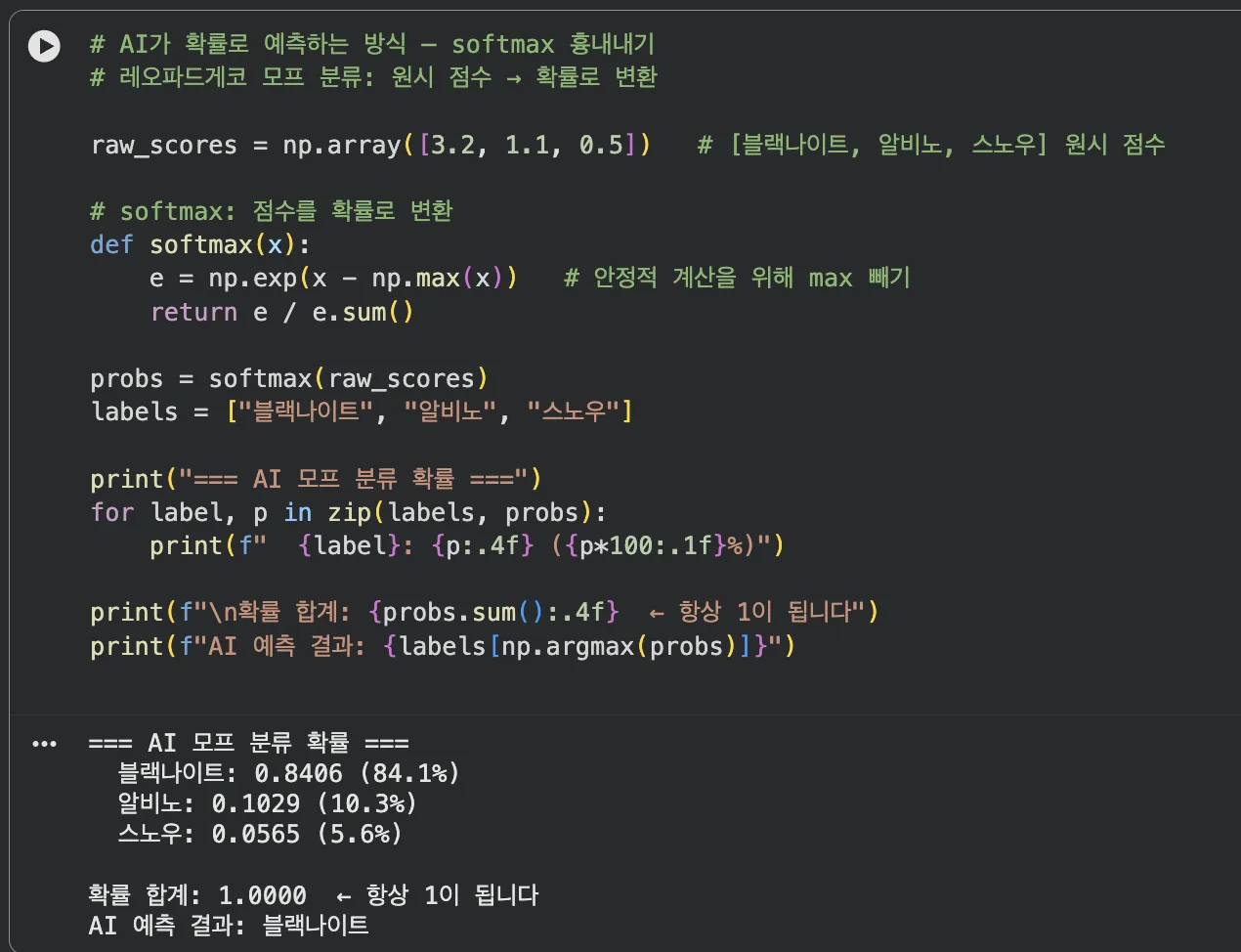
softmax를 거치면 어떤 점수든 합이 1인 확률로 변환된다
어떤 점수든 softmax를 거치면 전부 더해서 1이 되는 확률로 바뀝니다.
AI가 "블랙나이트일 확률 82%, 알비노일 확률 14%..."처럼 답하는 게 바로 이 덕분이에요.
정리
- 이산 확률의 기댓값 = 각 값 × 확률을 모두 더한 것
- 표준 정규분포는 평균=0, 표준편차=1 — AI 가중치 초기화에 사용됩니다
- 조건부 확률(베이즈 정리)은 새 정보로 기존 확률을 업데이트하는 원리
- softmax는 원시 점수를 확률로 변환 — AI 분류 모델의 마지막 단계
3편에 걸쳐 연립방정식, 평균·분산·로그, 확률까지 함께 알아봤습니다.
이 세 가지가 AI 수학의 뼈대입니다.
어렵게 느껴졌던 AI가 조금은 가까워졌으면 좋겠네요. ㅎㅎ