
[알고리즘 기초 2편] 그래프 탐색 — DFS와 BFS
1편에서 배운 스택·큐가 실제로 어떻게 쓰이는지 알 차례입니다. 스택으로 구현하는 DFS, 큐로 구현하는 BFS — 지하철 최단경로·SNS 추천·게임 AI까지 모두 이 두 알고리즘에서 시작해요. 3편에서는 최대공약수·이진 트리·프린터 스케줄링으로 이어집니다.
시작하며 — 1편에서 배운 스택·큐, 이제 써먹을 차례입니다 ㅎㅎ
지난 1편에서 스택과 큐를 배웠죠.
스택은 후입선출(LIFO), 큐는 선입선출(FIFO).
근데 그게 실제로 어디에 쓰이냐고요?
바로 여기서 씁니다 — 그래프 탐색에서요.
DFS(깊이 우선 탐색)는 스택으로 동작하고,
BFS(너비 우선 탐색)는 큐로 동작합니다.
1편을 들었다면 2편은 그 응용편이에요.
그래프란 뭔가요?
그래프는 노드(점)와 엣지(선)로 이루어진 자료구조로, 지하철 노선도나 SNS 친구 관계 같은 연결 구조를 표현해요. DFS와 BFS는 이 그래프를 탐색하는 두 가지 대표적인 방법이고, 스택과 큐를 각각 활용합니다.
서울 지하철 노선도를 생각해보세요.
역(노드)이 있고, 역과 역을 잇는 선(엣지)이 있죠.
이 구조가 바로 그래프(Graph)입니다.
그래프는 두 가지로 이루어져 있어요:
• 노드(Node / Vertex) — 정점, 연결되는 대상
• 엣지(Edge) — 노드와 노드를 잇는 간선
SNS 친구 관계도 그래프예요.
나(노드)와 친구들(노드)을 팔로우 관계(엣지)로 연결한 것과 똑같아요.
인접 리스트로 그래프 표현하기
코드로 그래프를 표현할 때 가장 많이 쓰는 방법은 인접 리스트입니다.
각 노드가 어떤 노드와 연결됐는지 딕셔너리로 저장해두는 거예요.
# 인접 리스트 — 7개 노드, 6개 엣지
graph = {
"A": ["B", "C"],
"B": ["A", "D", "E"],
"C": ["A", "F", "G"],
"D": ["B"],
"E": ["B"],
"F": ["C"],
"G": ["C"],
}
print(f"A와 연결된 노드: {graph['A']}") # ['B', 'C']
print(f"B와 연결된 노드: {graph['B']}") # ['A', 'D', 'E']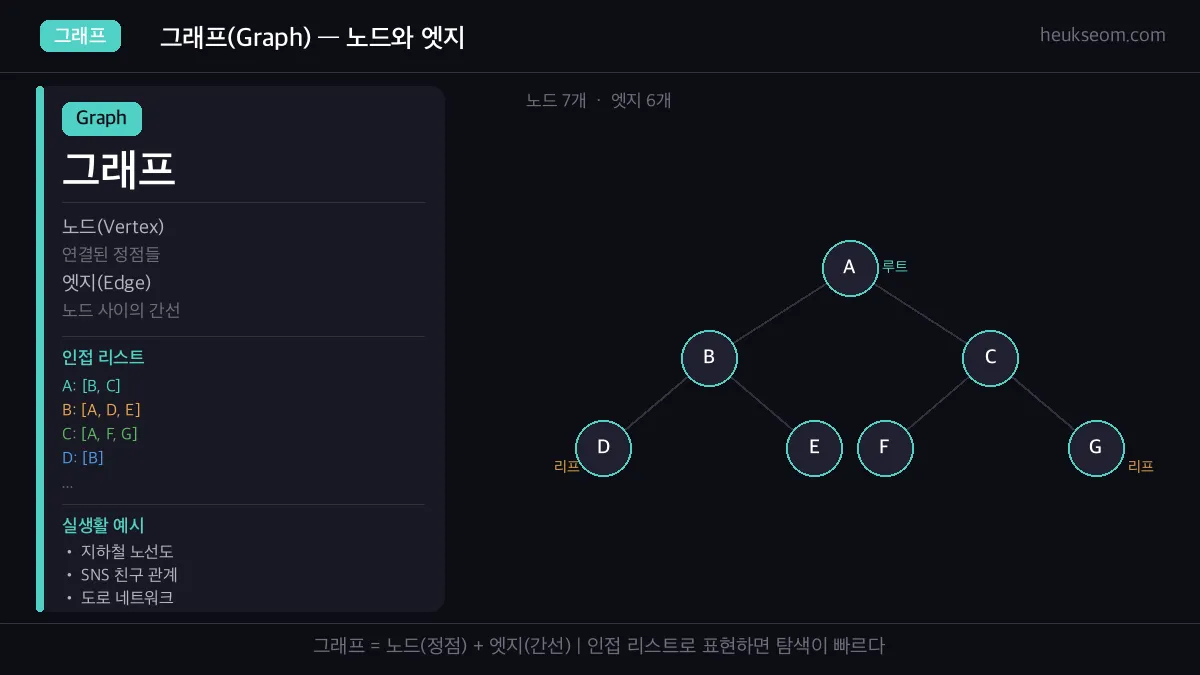
노드 7개, 엣지 6개의 트리형 그래프 — 인접 리스트로 표현
DFS는 어떻게 탐색하나요?
미로를 탈출한다고 상상해보세요.
갈림길에서 일단 한 방향으로 쭉 가다가, 막히면 돌아와서 다른 길을 가는 전략이에요.
이게 바로 DFS(Depth-First Search)입니다.
DFS의 핵심은 스택(재귀 콜스택)입니다.
한 방향으로 끝까지 파고들고, 막히면 되돌아오는 구조가 스택의 LIFO와 딱 맞아요.
def dfs(graph, node, visited=None):
if visited is None:
visited = set()
visited.add(node) # 방문 기록
print(node, end=' ') # 방문한 노드 출력
for neighbor in graph[node]:
if neighbor not in visited:
dfs(graph, neighbor, visited) # 재귀 호출 = 스택 쌓임
dfs(graph, "A")
# 출력: A B D E C F G
A에서 시작해서 B → D(끝) → 되돌아와서 E(끝) → 되돌아와서 C → F(끝) → G(끝).
한 방향으로 끝까지 파고드는 게 보이죠?
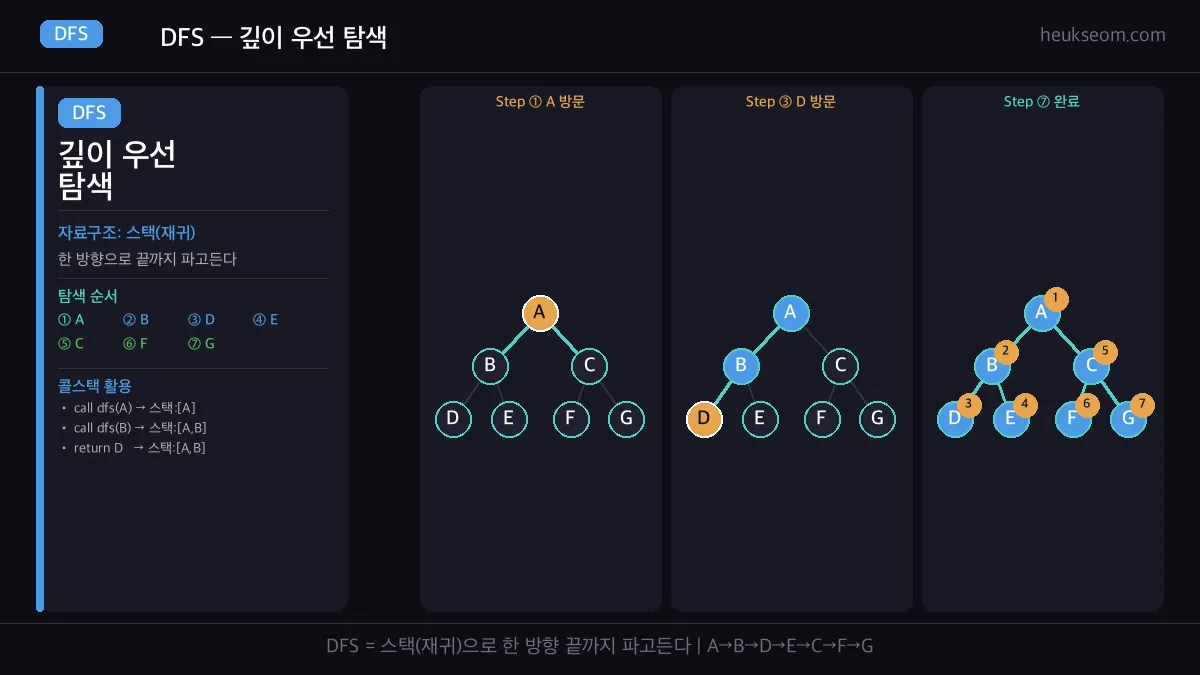
Step①: A만 방문 → Step③: A→B→D 탐색 중 → Step⑦: 전체 탐색 완료
DFS 콜스택이 곧 스택입니다
재귀 함수가 호출될 때마다 콜스택에 쌓입니다.
그게 1편에서 배운 스택 그대로예요.
dfs("A") 호출 → 콜스택: [dfs(A)]
dfs("B") 호출 → 콜스택: [dfs(A), dfs(B)]
dfs("D") 호출 → 콜스택: [dfs(A), dfs(B), dfs(D)]
dfs("D") 반환 → 콜스택: [dfs(A), dfs(B)]
dfs("E") 호출 → 콜스택: [dfs(A), dfs(B), dfs(E)]
... → A→B→D→E→C→F→G 순서로 완료BFS는 DFS랑 뭐가 다른가요?
이번엔 다른 전략이에요.
A에서 출발할 때, 한 방향으로 파고들지 않고 가까운 노드부터 차례로 방문합니다.
레벨 0 → 레벨 1 → 레벨 2 순서로 넓게 퍼져나가는 거예요.
BFS의 핵심은 큐(deque)입니다.
먼저 방문한 노드의 이웃을 먼저 처리하는 구조가 큐의 FIFO와 딱 맞아요.
from collections import deque
def bfs(graph, start):
visited = set([start])
queue = deque([start]) # 큐에 시작 노드 넣기
while queue:
node = queue.popleft() # 앞에서 꺼내기 (FIFO)
print(node, end=' ') # 방문한 노드 출력
for neighbor in graph[node]:
if neighbor not in visited:
visited.add(neighbor)
queue.append(neighbor) # 뒤에서 추가
bfs(graph, "A")
# 출력: A B C D E F G
A에서 시작 → B, C(레벨 1) → D, E, F, G(레벨 2) 순서로 탐색해요.
같은 거리에 있는 노드들을 먼저 다 방문하고 다음 레벨로 넘어가죠.
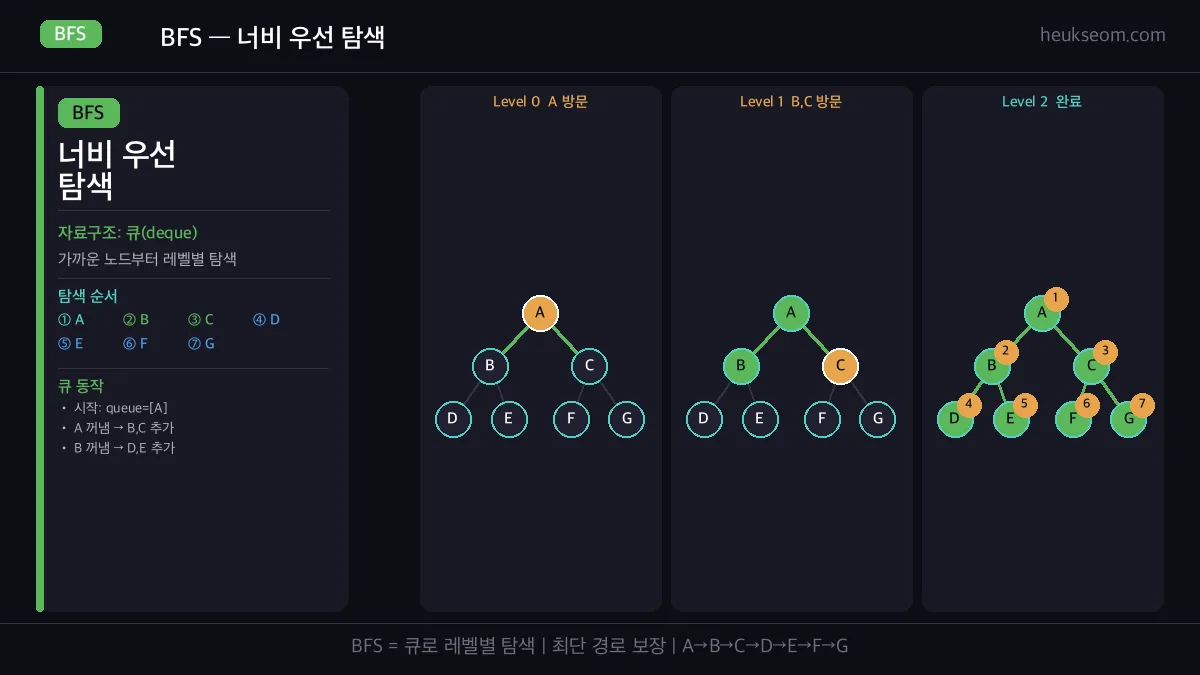
Level 0: A → Level 1: B, C → Level 2: D, E, F, G 순서로 탐색
BFS 큐 동작 과정
시작: queue = [A]
A 꺼냄: print(A) → B, C 추가 → queue = [B, C]
B 꺼냄: print(B) → D, E 추가 → queue = [C, D, E]
C 꺼냄: print(C) → F, G 추가 → queue = [D, E, F, G]
D 꺼냄: print(D) → → queue = [E, F, G]
...
# 출력: A B C D E F G ← 가까운 것부터!DFS와 BFS, 언제 어떤 걸 써야 하나요?
두 알고리즘은 같은 그래프를 탐색하지만 결과가 달라요.
상황에 따라 맞는 걸 골라 써야 합니다.
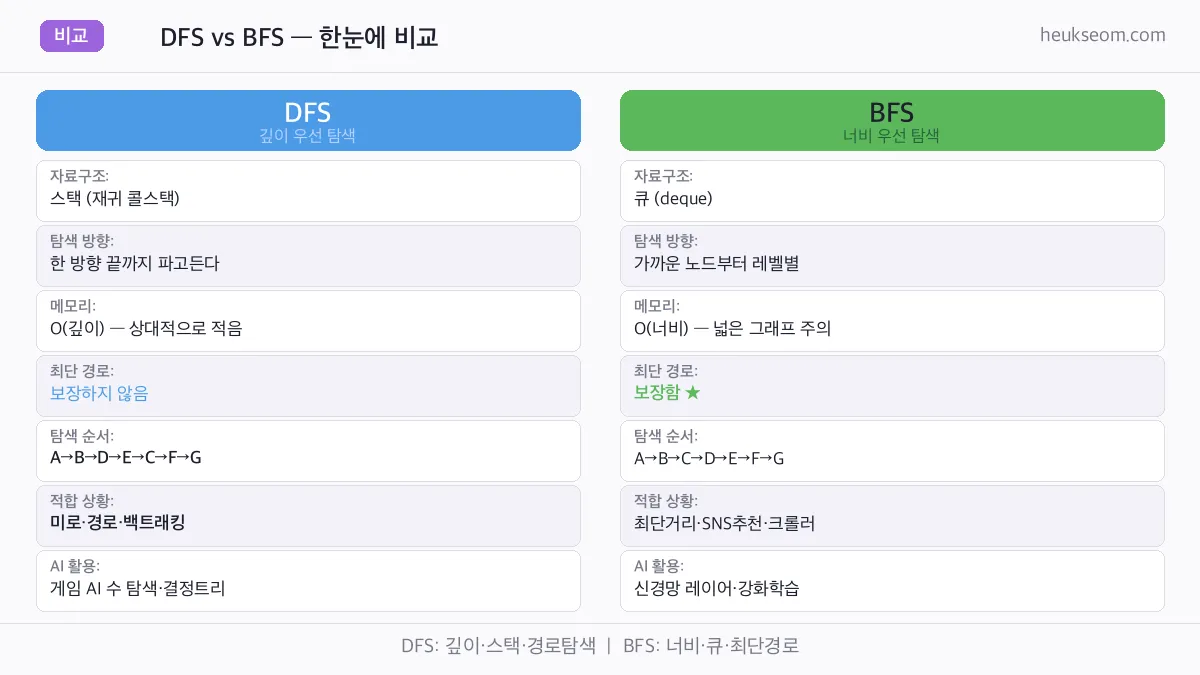
DFS: 스택·경로탐색 | BFS: 큐·최단경로 — 상황에 맞게 선택
핵심 차이를 정리하면:
DFS를 쓰는 경우
• 미로 탈출, 경로 존재 여부 확인
• 백트래킹 문제 (N-Queen, 순열 생성)
• 연결 요소 탐색, 사이클 탐지
• 메모리가 제한될 때 (깊이가 너비보다 작을 때)
BFS를 쓰는 경우
• 두 노드 사이의 최단 경로를 구할 때
• 지하철 최소 환승, 게임 최단 이동
• SNS "몇 단계 친구"인지 계산
• 웹 크롤러 (가까운 링크부터 수집)
그래프 탐색이 AI에서는 어떻게 쓰이나요?
그래프 탐색은 AI의 핵심 알고리즘 중 하나예요.
게임 AI — 체스, 바둑에서 다음 수를 계산할 때 DFS로 수백만 가지 경우를 탐색합니다.
알파고가 쓴 몬테카를로 트리 탐색(MCTS)도 결국 그래프 탐색이에요.
신경망 학습 — 딥러닝 모델에서 역전파(Backpropagation)를 계산할 때
출력층 → 입력층으로 BFS 방식의 레이어별 탐색을 합니다.
추천 시스템 — 넷플릭스, 유튜브에서 "이 영상을 좋아하는 사람이 좋아한 영상"을
찾을 때 사용자-콘텐츠 그래프를 BFS로 탐색해요.
# 간단한 경로 탐색 예제 (DFS 활용)
def find_path(graph, start, end, visited=None):
"""start에서 end까지 경로가 있으면 True 반환"""
if visited is None:
visited = set()
if start == end:
return True
visited.add(start)
for neighbor in graph[start]:
if neighbor not in visited:
if find_path(graph, neighbor, end, visited):
return True
return False
print(find_path(graph, "D", "G")) # True — D→B→A→C→G 경로 존재
print(find_path(graph, "D", "D")) # True — 자기 자신정리
이번 편에서 배운 것들을 정리해요.
1. 그래프 = 노드 + 엣지 | 인접 리스트로 표현하면 효율적
2. DFS = 스택(재귀)으로 깊이 우선 탐색 | 경로 탐색에 강함
3. BFS = 큐(deque)로 너비 우선 탐색 | 최단 경로 보장
4. 연결고리: 1편 스택 → DFS, 1편 큐 → BFS로 그대로 이어진다
알고리즘 기초 2편 시리즈 여기까지입니다. ㅎㅎ
스택·큐·재귀를 배우고 → 그래프 탐색에 바로 적용하는 흐름.
이게 자료구조와 알고리즘이 연결되는 방식이에요.
다음엔 정렬 알고리즘(버블, 퀵, 병합)으로 이어질 예정입니다.