
[머신러닝 기초 4편] 나이브 베이즈 — 확률로 스팸을 잡는다
받은 메일이 스팸인지 아닌지 AI는 어떻게 판단할까요? 나이브 베이즈는 단어 등장 확률을 곱해서 분류하는 단순하지만 강력한 알고리즘입니다. 베이즈 정리부터 스팸 필터 직접 구현까지 다뤄봅니다.
시작하며 — 스팸 메일함, 어떻게 채워지는 걸까?
이메일 받은편지함에 "축하합니다! 무료 당첨 혜택 클릭하세요" 같은 메일이 뜨면
자동으로 스팸함으로 넘어가죠. 한 번도 설정한 적 없는데 어떻게 아는 걸까요?
비밀은 바로 단어 확률입니다.
"무료", "당첨", "클릭" 같은 단어가 많이 등장하면 스팸일 확률이 높아지고,
"회의", "보고서", "첨부" 같은 단어가 많으면 정상 메일일 확률이 높아집니다.
나이브 베이즈는 이 단어들의 확률을 곱해서 분류하는 알고리즘이에요.
(TMI: 사실 이번 시리즈 준비하면서 개인적으로 제일 좋아하는 알고리즘이기도 해요.
수식은 단순한데 실제로 잘 되는 게 묘하게 매력적이거든요 ㅋㅋㅋ)
베이즈 정리가 뭔가요?
베이즈 정리는 새로운 증거(데이터)가 나타났을 때, 기존에 알고 있던 확률을 업데이트하는 공식이에요. 스팸 필터로 치면 "무료"라는 단어가 등장했을 때 이 메일이 스팸일 확률을 다시 계산하는 원리입니다.

나이브 베이즈의 핵심은 베이즈 정리(Bayes' Theorem)입니다.
P(A|B) = P(B|A) × P(A) / P(B)
P(A|B) — 사후확률: B를 본 후 A일 확률 (우리가 원하는 것)
P(B|A) — 우도: A일 때 B가 나올 확률
P(A) — 사전확률: 처음부터 알고 있던 A의 확률
P(B) — 증거: B가 나올 전체 확률
스팸 필터로 치면 — "무료"라는 단어가 등장했을 때(B),
이게 스팸일 확률(A)을 계산하는 거예요.
사전확률(스팸 비율 30%) + 우도(스팸에서 무료 등장률 80%) → 사후확률 계산.
스팸 필터는 어떻게 작동하나요?
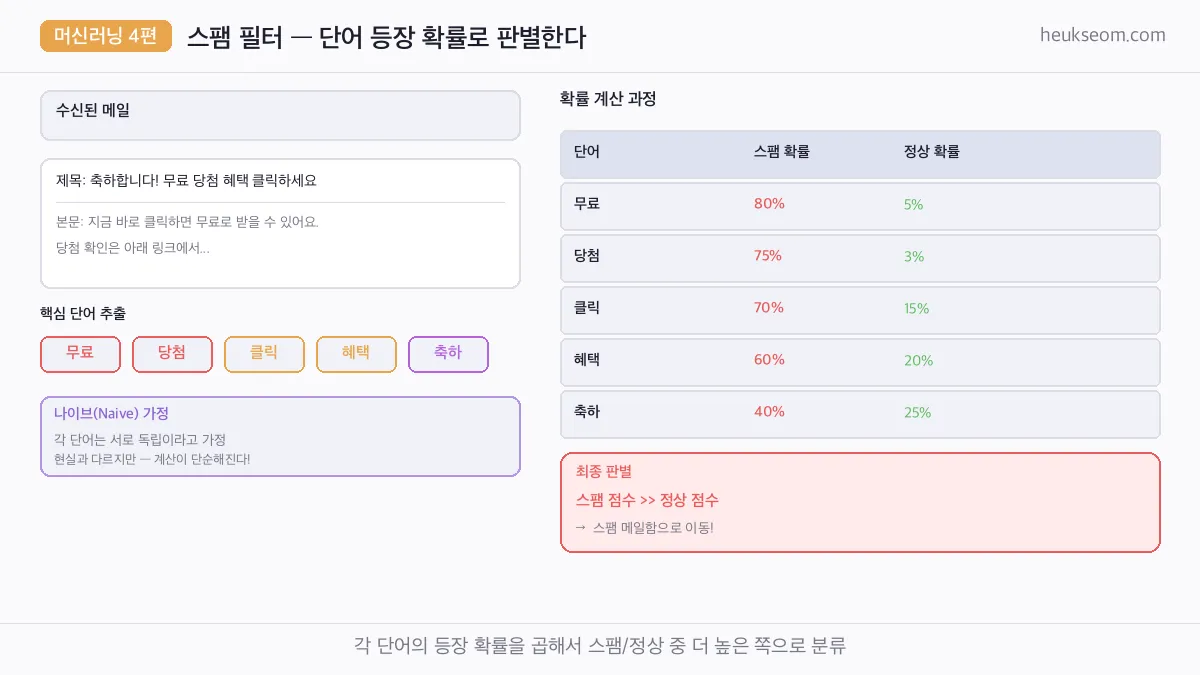
"나이브(Naive, 순진한)"라는 이름이 붙은 이유가 있어요.
각 단어가 서로 독립이라고 가정하거든요.
현실에서 "무료"와 "당첨"은 함께 등장하는 경향이 있어서 독립이 아니에요.
그런데 독립이라고 가정하면 — 확률을 그냥 곱하면 됩니다. 계산이 엄청 단순해지죠.
단순한 가정이지만, 실제로 스팸 필터에서는 굉장히 잘 작동합니다.
스팸 점수 = P(스팸) × P(무료|스팸) × P(당첨|스팸) × P(클릭|스팸) × ...
정상 점수 = P(정상) × P(무료|정상) × P(당첨|정상) × P(클릭|정상) × ...
둘 중 점수가 높은 쪽으로 분류!
나이브 베이즈와 로지스틱 회귀, 뭐가 다른가요?

지난 편의 로지스틱 회귀와 비교해보면 이렇습니다.
데이터가 적고 빠른 판단이 필요하면 나이브 베이즈,
데이터가 많고 정확도가 중요하면 로지스틱 회귀가 유리해요.
코드로 직접 구현해보기
from sklearn.datasets import load_iris
from sklearn.naive_bayes import GaussianNB
from sklearn.model_selection import train_test_split
iris = load_iris()
X, y = iris.data, iris.target
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
model = GaussianNB()
model.fit(X_train, y_train)
print(f"Train Accuracy: {model.score(X_train, y_train):.4f}")
print(f"Test Accuracy: {model.score(X_test, y_test):.4f}")
# 확률 예측
proba = model.predict_proba(X_test[:5])
print("\n첫 5개 샘플 예측 확률:")
for i, p in enumerate(proba):
classes = iris.target_names
best = p.argmax()
print(f" 샘플 {i+1}: {classes[best]} ({p[best]*100:.1f}%)")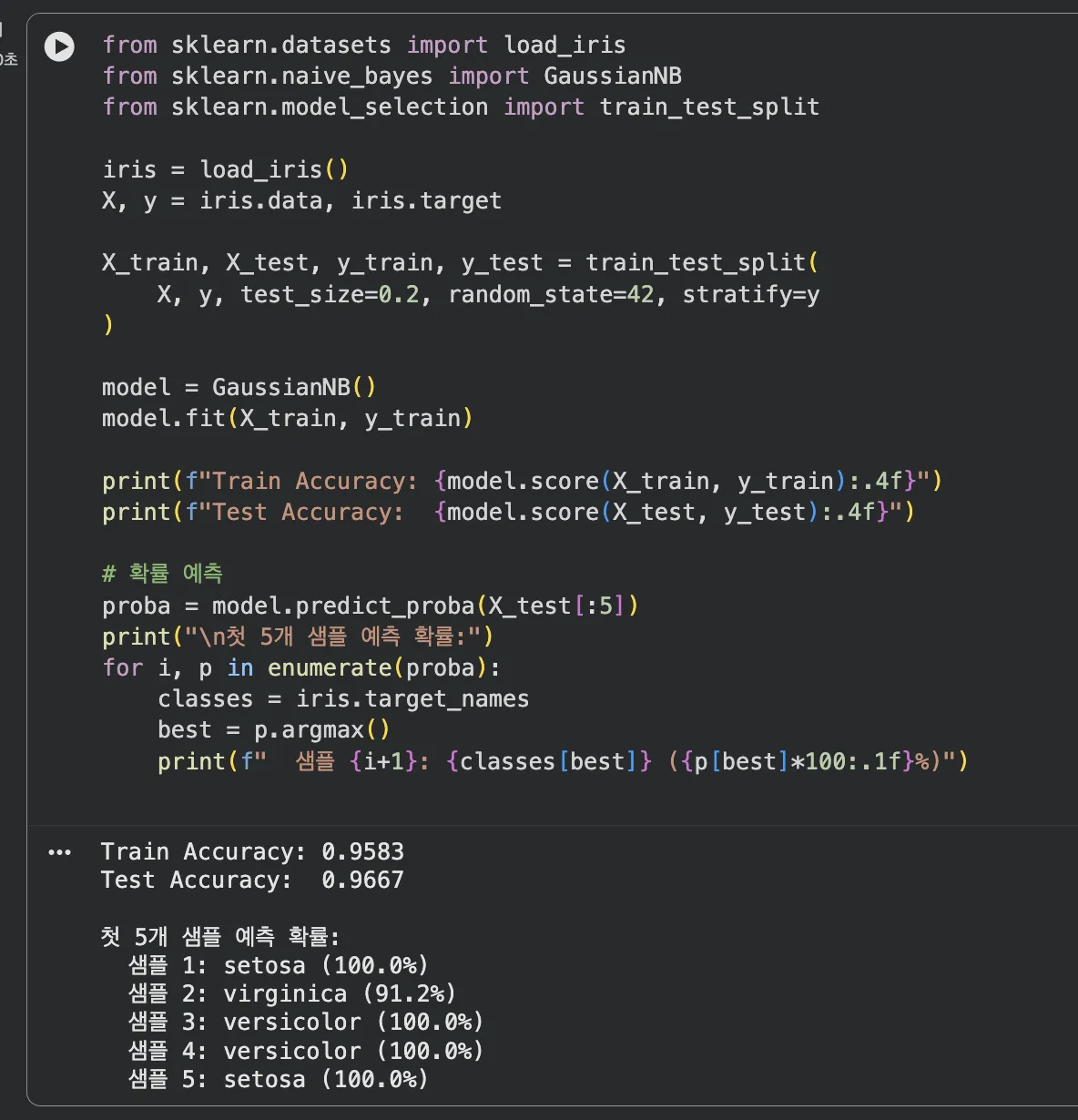
Train 95.83%, Test 96.67% — 안정적인 결과예요.
특히 setosa는 100% 확률로 분류 — 다른 품종과 특성이 명확히 구분되기 때문이에요.
GaussianNB는 각 특성이 정규분포를 따른다고 가정하는 나이브 베이즈예요.
텍스트 데이터엔 MultinomialNB, 연속형 데이터엔 GaussianNB를 주로 씁니다.
정리
- 베이즈 정리로 새 증거(단어)를 반영해 확률을 업데이트한다
- 각 단어가 독립이라는 나이브 가정 덕분에 계산이 단순해진다
- 데이터가 적어도 빠르게 작동 — 스팸 필터, 뉴스 분류에 강하다
다음 편에서는 숫자 데이터로 값을 예측하는 선형 회귀를 다룹니다.