
[머신러닝 기초 6편] 모델 평가 지표 — 정확도만 보면 안 되는 이유
굉장히 민감한 영역입니다. 정확도 99%인데 암 환자를 전부 놓친다면 어떻게 될까요..(상상하기도 싫습니다.) 모델을 제대로 평가하려면 혼동행렬, 정밀도, 재현율, F1 점수를 알아야 합니다. 각 지표가 언제 중요한지, 어떻게 계산하는지 직접 코드로 확인해봅니다.
시작하며 — 정확도의 함정
암 환자 1000명 중 10명만 실제 환자인 데이터가 있다고 해봅시다.
"전부 정상"이라고 예측하는 모델의 정확도는 990/1000 = 99%입니다.
근데 이 모델은 암 환자 10명을 전부 놓쳤어요.
정확도(Accuracy) 하나만 보면 이런 함정에 빠집니다.
머신러닝 6편에서는 모델을 제대로 평가하는 4가지 지표를 정리합니다.
혼동행렬이 뭔가요?
혼동행렬(Confusion Matrix)은 모델의 예측 결과를 TP, FP, TN, FN 네 가지로 나눠서 보여주는 표예요. 정확도만으로는 보이지 않는 모델의 약점을 드러내주고, 정밀도/재현율/F1 같은 핵심 평가 지표의 출발점이 됩니다.

모든 평가 지표의 출발점은 혼동행렬(Confusion Matrix)입니다.
예측 결과를 4가지로 분류합니다.
TP (True Positive) — 양성을 양성으로 올바르게 예측
FN (False Negative) — 양성을 음성으로 잘못 예측 (놓침)
FP (False Positive) — 음성을 양성으로 잘못 예측 (과탐지)
TN (True Negative) — 음성을 음성으로 올바르게 예측
"True"는 예측이 맞았다는 뜻, "False"는 틀렸다는 뜻입니다.
"Positive/Negative"는 예측한 값이 양성/음성이라는 뜻이에요.
정밀도, 재현율, F1은 언제 어떤 걸 써야 하나요?
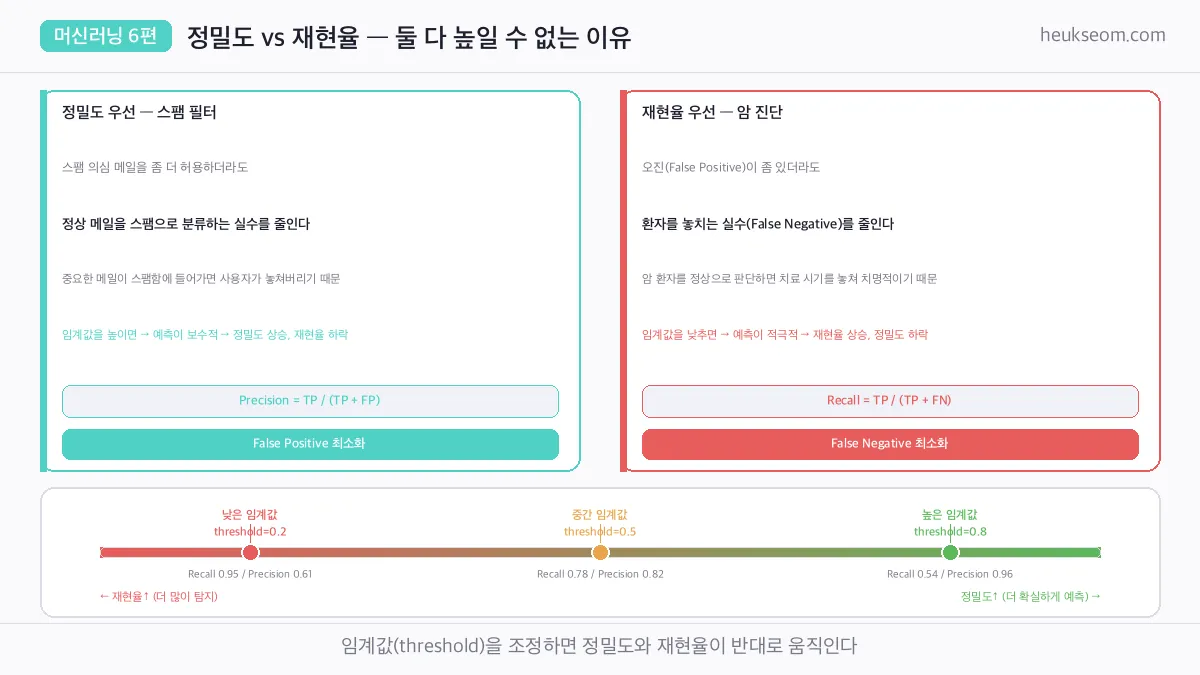
혼동행렬의 4개 숫자로 세 가지 핵심 지표를 계산합니다.
정밀도 (Precision) = TP / (TP + FP)
→ 양성이라 예측한 것 중 실제 양성 비율
→ 스팸 필터 — 중요한 메일을 스팸으로 분류하면 안 됨
재현율 (Recall) = TP / (TP + FN)
→ 실제 양성 중 올바르게 찾아낸 비율
→ 암 진단 — 환자를 놓치면 치료 시기를 잃는다
F1 점수 = 2 × Precision × Recall / (Precision + Recall)
→ 정밀도와 재현율의 조화 평균
→ 둘 다 중요할 때 — 불균형 데이터에 적합
정밀도와 재현율은 트레이드오프 관계입니다.
임계값을 높이면 정밀도 상승 / 재현율 하락, 낮추면 그 반대예요.
어떤 실수가 더 큰 피해를 주는지에 따라 임계값을 조정합니다.
코드로 직접 계산해보기
from sklearn.datasets import make_classification
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import (
confusion_matrix, classification_report,
ConfusionMatrixDisplay
)
import matplotlib.pyplot as plt
# 데이터 준비
X, y = make_classification(n_samples=1000, n_features=10,
n_classes=2, weights=[0.9, 0.1],
random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 모델 학습
model = LogisticRegression(random_state=42)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
# 혼동행렬
cm = confusion_matrix(y_test, y_pred)
disp = ConfusionMatrixDisplay(confusion_matrix=cm)
disp.plot()
plt.title("Confusion Matrix")
plt.show()
# 분류 리포트
print(classification_report(y_test, y_pred,
target_names=["정상", "양성"]))
classification_report()를 실행하면 정밀도, 재현율, F1 점수가 한 번에 출력됩니다.
각 클래스별로 따로 계산되어 어느 클래스에서 약한지 바로 확인할 수 있어요.
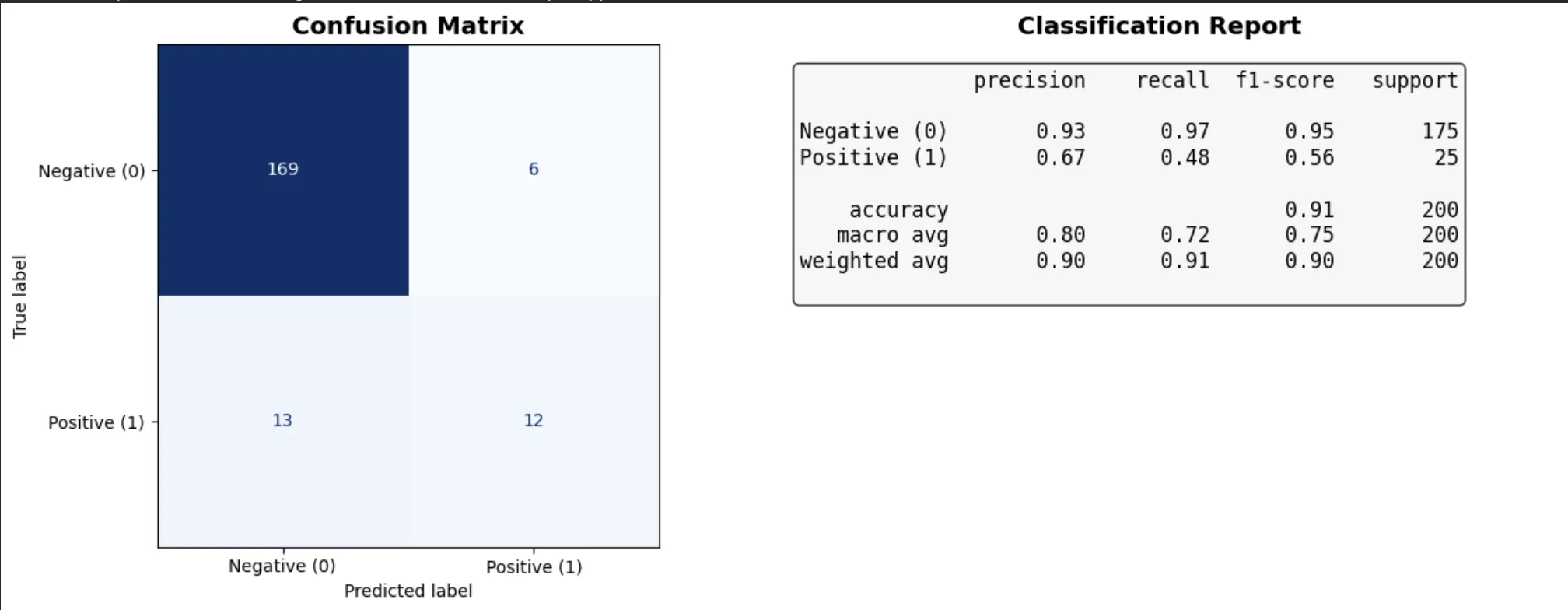
정확도(accuracy)는 0.91이지만 Positive 클래스의 recall은 0.48 — 양성 환자 절반을 놓쳤어요.
정확도만 보면 "잘 작동하는 모델"처럼 보이지만, 실제로는 위험한 모델이에요.
4가지 평가 지표, 한눈에 비교하면 어떤가요?

각 지표를 언제 쓸지 한 줄로 정리하면:
- 정확도 — 데이터가 균형 잡혀 있을 때, 기본 확인용
- 정밀도 — 오탐(FP)이 비싼 경우: 스팸 필터, 광고 타겟팅
- 재현율 — 누락(FN)이 위험한 경우: 암 진단, 사기 탐지
- F1 점수 — 불균형 데이터, 정밀도+재현율 둘 다 중요한 경우
정리
머신러닝 기초 6편이자 마지막 편이에요.
1편(k-NN)부터 6편(모델 평가)까지 읽어주셔서 감사합니다.
핵심만 요약하면:
- 정확도만 믿지 말 것 — 불균형 데이터에서 함정이 있음
- 혼동행렬(TP/FP/TN/FN)에서 모든 지표가 나옴
- 정밀도: FP 최소화 / 재현율: FN 최소화 / F1: 균형
- 상황에 따라 어떤 지표를 우선할지 판단하는 것이 핵심