
[머신러닝 중급 3편] 정규화 기법 — 모델에 '벌금'을 매기는 이유
1편에서 과적합 해결책 중 하나로 '정규화'를 잠깐 언급했었는데, 솔직히 그때는 이름만 들었지 뭔지 감이 안 왔습니다. L1, L2가 뭐고 왜 가중치에 벌금을 매기는 건지.. Ridge, Lasso 코드를 직접 돌려보고 alpha 값을 이리저리 바꿔본 뒤에야 '아, 이래서 정규화가 필요하구나' 이해했습니다.
시작하며 — 짐 싸기 비유
정규화는 영어로 Regularization입니다. "규칙(regular)을 부여한다"는 뜻인데,
쉽게 말하면 모델이 너무 자유롭게 학습하지 못하도록 제약을 거는 것입니다.
1편에서 과적합 해결책 중 하나로 잠깐 언급했었는데,
솔직히 그때는 이름만 들었지 뭔지 전혀 감이 안 왔어요.
"가중치에 벌금을 매긴다"는 설명을 듣고도, 왜 벌금을 매기면 과적합이 줄어든다는 건지 납득이 안 됐습니다.
그러다 이런 비유가 딱 와닿더라고요.
여행 짐을 싸는 상황을 생각해보세요.
짐을 무제한으로 가져갈 수 있으면? "혹시 몰라" 별걸 다 챙기게 됩니다.
근데 짐 하나당 추가 요금(벌금)이 붙는다면?
진짜 필요한 것만 골라서 챙기게 돼요.
모델도 마찬가지입니다. 특성(feature)을 무제한으로 쓰면 과적합이 일어나고,
가중치에 벌금을 매기면 불필요한 특성은 자연스럽게 줄어들어요.
L1(Lasso)과 L2(Ridge), 뭐가 다른가요?
L1(Lasso)은 불필요한 특성의 가중치를 아예 0으로 만들어서 특성을 제거하는 효과가 있고, L2(Ridge)는 가중치를 골고루 줄여서 전체적인 과적합을 방지해요. 쉽게 말하면 L1은 짐을 안 챙기는 거고, L2는 짐을 가볍게 만드는 거예요.
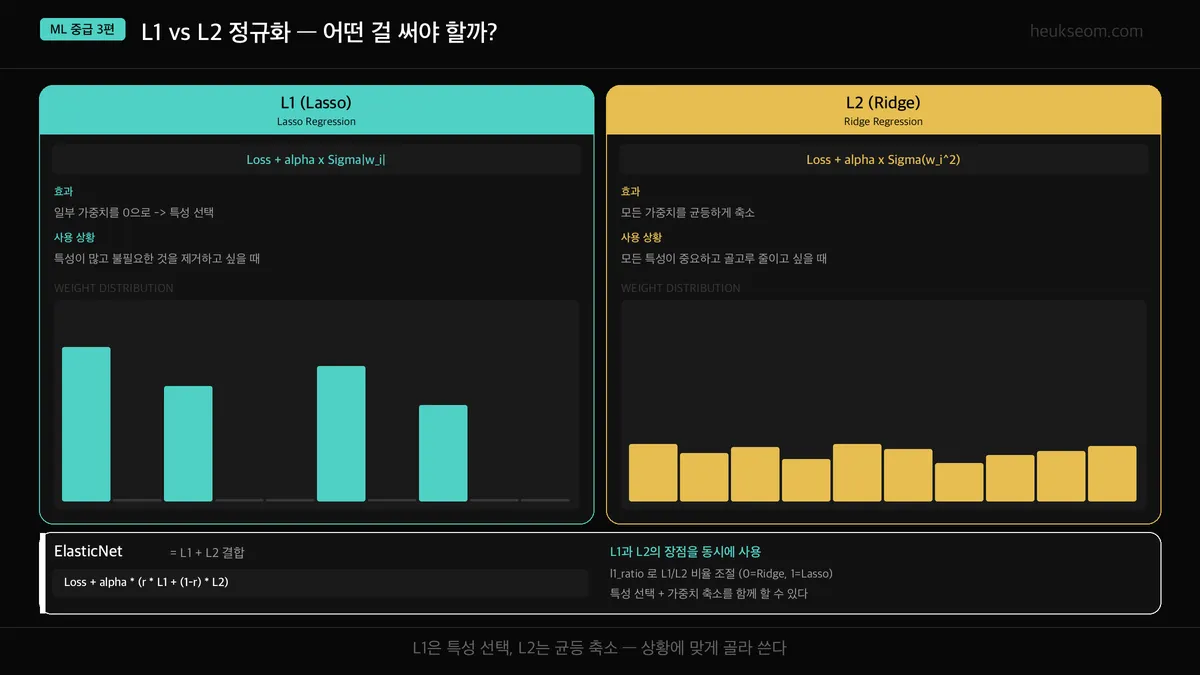
정규화에는 크게 두 가지 방법이 있습니다.
이름은 복잡해 보이지만, 핵심 차이는 심플합니다.
L1 (Lasso) — 짐 '개수'에 비례한 벌금. 안 쓸 짐은 아예 안 챙김 → 가중치를 0으로 만듦 (특성 제거)
L2 (Ridge) — 짐 '무게'에 비례한 벌금. 전체적으로 짐을 가볍게 줄임 → 가중치를 골고루 축소
코드로 보면 더 와닿습니다.
from sklearn.linear_model import Lasso, Ridge
import numpy as np
# 예시 데이터 (보스턴 주택가격 대체 데이터)
from sklearn.datasets import make_regression
X, y = make_regression(n_samples=100, n_features=10, noise=10, random_state=42)
# Ridge (L2) — 가중치를 균등하게 줄임
ridge = Ridge(alpha=1.0)
ridge.fit(X, y)
print("Ridge 계수:", np.round(ridge.coef_, 2))
# Lasso (L1) — 일부 가중치를 0으로 만듦
lasso = Lasso(alpha=1.0)
lasso.fit(X, y)
print("Lasso 계수:", np.round(lasso.coef_, 2))
Ridge 결과를 보면 모든 계수가 살아있되 값이 줄어들어 있고,
Lasso 결과를 보면 일부 계수가 아예 0이 됩니다.
처음에 이 결과를 보고 "진짜 0이 되네?" 하면서 좀 신기했어요.
가중치 분포를 비교하면 어떤 차이가 보이나요?
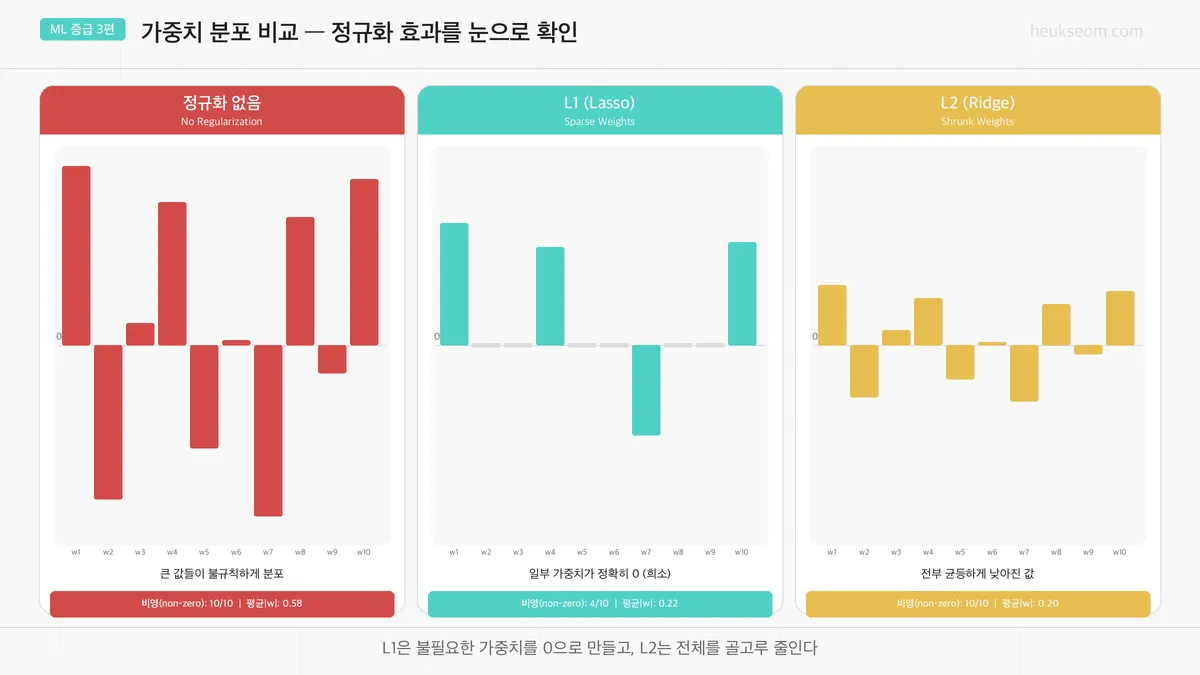
위 그래프를 보면 차이가 확 드러납니다.
정규화 없음 — 가중치가 제멋대로. 어떤 건 엄청 크고, 어떤 건 작고
L1 (Lasso) — 불필요한 가중치가 깔끔하게 0으로 사라짐. 특성 선택 효과
L2 (Ridge) — 전체적으로 값이 줄어들지만, 0은 안 됨. 골고루 축소
그래서 특성이 너무 많아서 중요한 것만 골라내고 싶다면 → L1 (Lasso)
전체적으로 과적합을 줄이고 싶다면 → L2 (Ridge)
이렇게 골라 쓰면 됩니다.
alpha는 어떤 역할을 하나요?
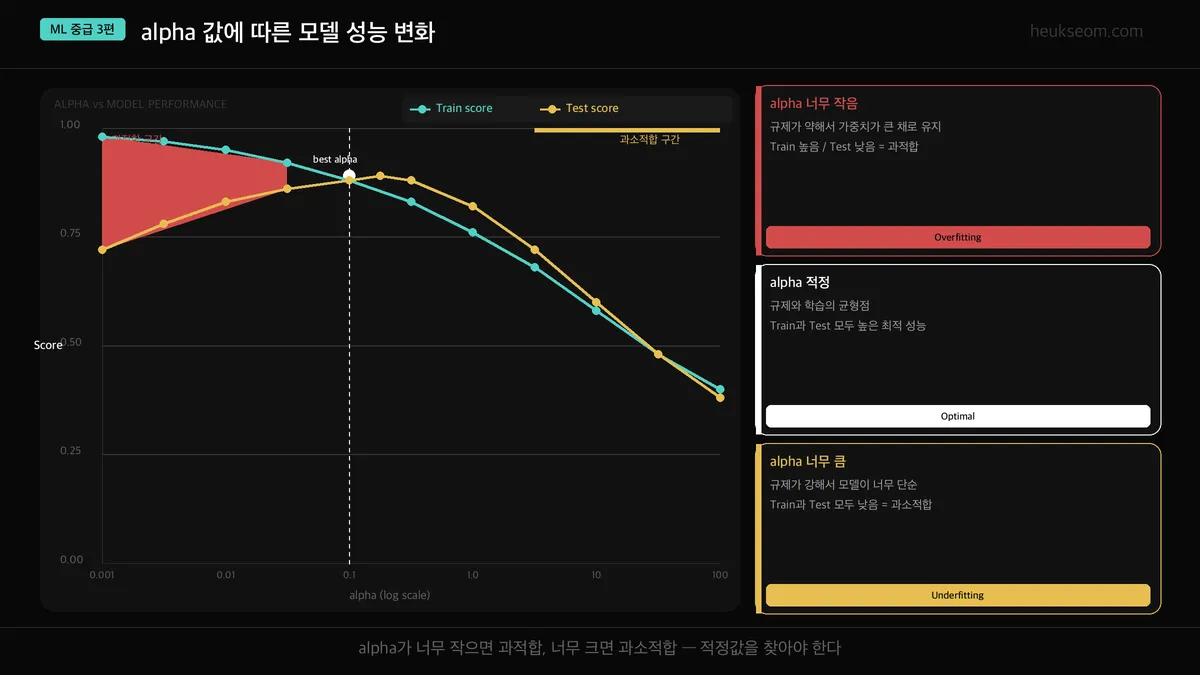
alpha 값은 "벌금을 얼마나 세게 매길 것인가"를 정합니다.
이걸 조절해보면서 과적합·과소적합 사이의 균형을 찾는 건데,
처음에 alpha를 이리저리 바꿔보면서 한참 헤맸습니다.
alpha가 너무 작으면 → 벌금이 약해서 과적합 (정규화 없는 것과 비슷)
alpha가 너무 크면 → 벌금이 너무 세서 과소적합 (모델이 아무것도 못 배움)
적절한 alpha → Train과 Test 점수가 모두 높은 구간. 교차검증으로 찾음
from sklearn.linear_model import Ridge
from sklearn.model_selection import cross_val_score
import numpy as np
alphas = [0.001, 0.01, 0.1, 1, 10, 100, 1000]
for alpha in alphas:
ridge = Ridge(alpha=alpha)
scores = cross_val_score(ridge, X, y, cv=5, scoring='r2')
print(f"alpha={alpha:>7} → 평균 R²: {scores.mean():.4f} (±{scores.std():.4f})")
이렇게 alpha 후보를 넣고 교차검증 돌리면, 어디쯤이 최적인지 감이 옵니다.
저는 처음에 alpha=100 같은 큰 값을 넣어봤다가 점수가 뚝 떨어져서 당황했는데,
그게 바로 과소적합이었더라고요.
실전 코드 — Ridge / Lasso 제대로 비교하기
실무에서는 보통 이런 식으로 Ridge와 Lasso를 나란히 비교합니다.
alpha 값을 여러 개 넣고, 어떤 모델이 더 잘 맞는지 확인하는 거죠.
from sklearn.linear_model import Ridge, Lasso
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import make_regression
import numpy as np
# 데이터 준비
X, y = make_regression(n_samples=200, n_features=20, n_informative=5,
noise=20, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
# 스케일링 (정규화 전에 반드시!)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Ridge vs Lasso 비교
print("=== Ridge (L2) ===")
for alpha in [0.1, 1.0, 10.0]:
ridge = Ridge(alpha=alpha)
ridge.fit(X_train_scaled, y_train)
train_score = ridge.score(X_train_scaled, y_train)
test_score = ridge.score(X_test_scaled, y_test)
n_nonzero = np.sum(np.abs(ridge.coef_) > 0.01)
print(f" alpha={alpha:>5} → train: {train_score:.3f}, test: {test_score:.3f}, 유의미한 특성: {n_nonzero}개")
print("\n=== Lasso (L1) ===")
for alpha in [0.1, 1.0, 10.0]:
lasso = Lasso(alpha=alpha)
lasso.fit(X_train_scaled, y_train)
train_score = lasso.score(X_train_scaled, y_train)
test_score = lasso.score(X_test_scaled, y_test)
n_nonzero = np.sum(np.abs(lasso.coef_) > 0.01)
print(f" alpha={alpha:>5} → train: {train_score:.3f}, test: {test_score:.3f}, 유의미한 특성: {n_nonzero}개")
포인트는 Lasso의 "유의미한 특성" 개수입니다.
alpha를 키울수록 0이 되는 계수가 많아지면서, 자연스럽게 특성 선택이 이루어져요.
원래 20개 특성 중 실제로 의미 있는 건 5개뿐인 데이터라서, Lasso가 그걸 찾아내는 걸 볼 수 있습니다.
참고: 스케일링(StandardScaler)은 정규화 전에 반드시 해야 합니다.
특성마다 단위가 다르면 벌금이 불공평하게 적용되기 때문이에요. 이건 2편 SVM에서도 언급했던 내용.
직접 돌려본 결과 — Ridge vs Lasso 계수 변화
alpha를 0.01부터 1000까지 쭉 바꿔가면서 각 계수가 어떻게 변하는지 그래프로 그려봤습니다.
이걸 보면 Ridge와 Lasso의 차이가 확실하게 보입니다.
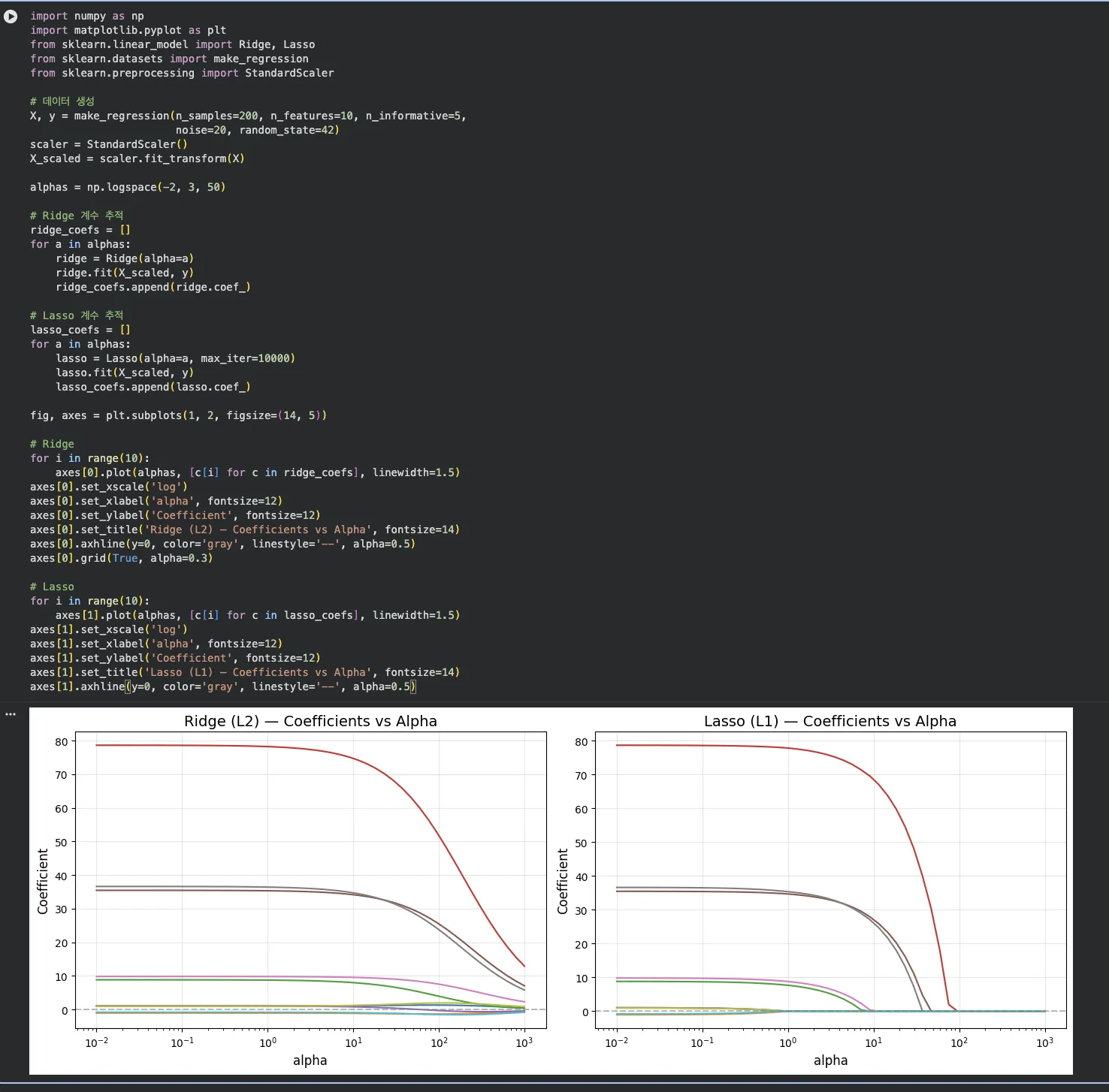
Ridge(왼쪽) — alpha가 커져도 계수들이 0에 수렴할 뿐, 완전히 0이 되지는 않음
Lasso(오른쪽) — alpha가 커지면 하나씩 0으로 딱 떨어지는 게 보임. 이게 특성 선택 효과
규제 강도에 따라 성능이 어떻게 달라지나요?
alpha를 바꾸면 성능이 어떻게 변하는지도 확인해봤습니다.
이게 결국 "적절한 alpha를 어떻게 찾느냐"에 대한 답이에요.
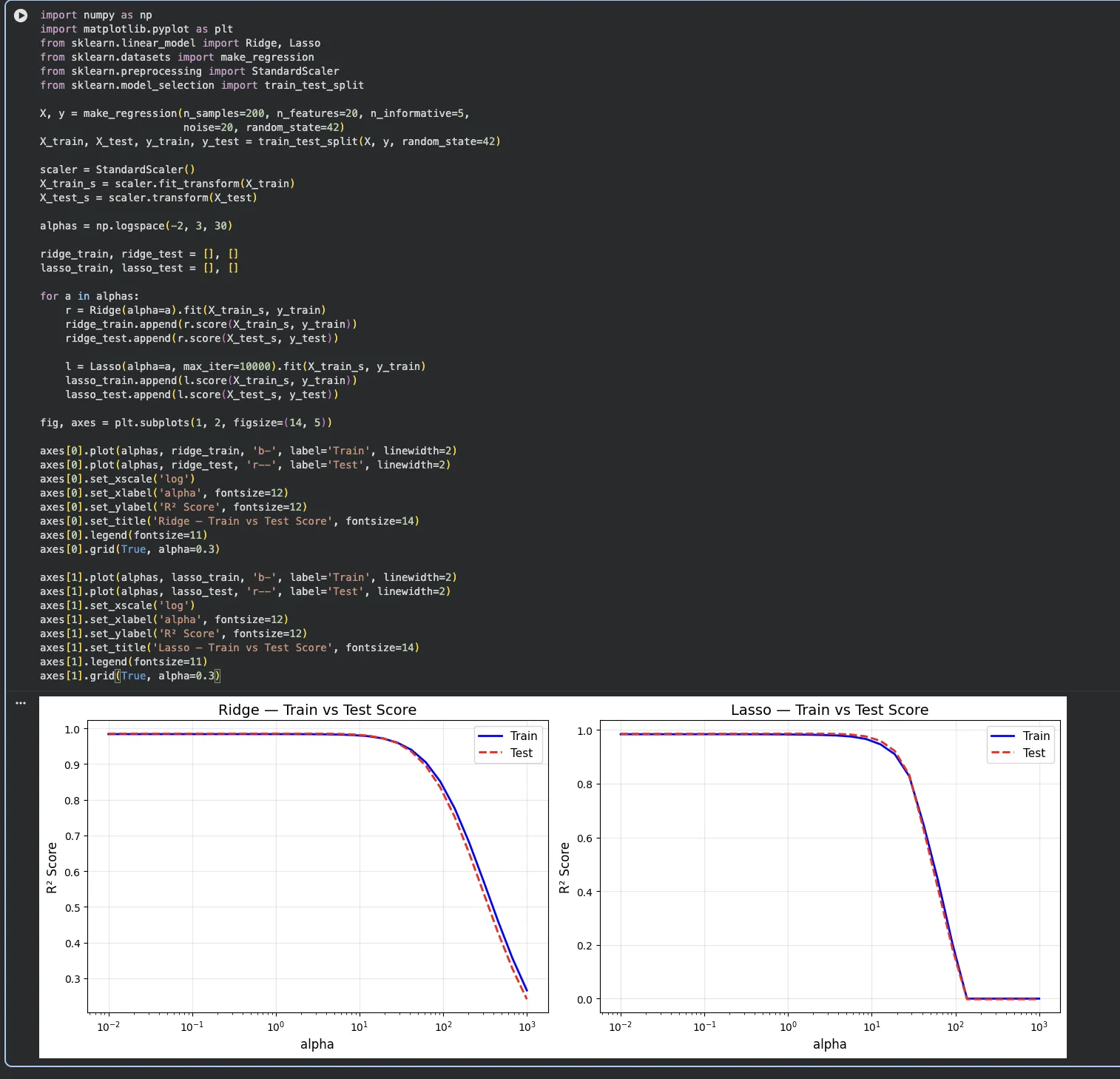
alpha가 작을 때(왼쪽) → Train 점수는 높지만 Test와 차이가 벌어짐 = 과적합
alpha가 클 때(오른쪽) → 둘 다 점수가 떨어짐 = 과소적합
중간 어딘가에 Train과 Test가 모두 높은 최적 구간이 있음
그럼 Ridge랑 Lasso 중 뭘 써야 하나요?
처음에 Ridge, Lasso 보고 "그래서 뭘 써야 하는데?" 싶었습니다.
실무에서 쓰다 보니 이런 기준이 생겼어요.
특성이 많고, 중요한 것만 골라내고 싶다면 → Lasso (L1)
전반적으로 안정적인 성능이 필요하다면 → Ridge (L2)
둘 다 쓰고 싶다면 → ElasticNet (L1 + L2 혼합)
from sklearn.linear_model import ElasticNet
# L1과 L2를 섞어서 사용
# l1_ratio=0.5면 L1과 L2를 반반 혼합
elastic = ElasticNet(alpha=1.0, l1_ratio=0.5)
elastic.fit(X_train_scaled, y_train)
print(f"ElasticNet score: {elastic.score(X_test_scaled, y_test):.3f}")
print(f"0이 된 계수: {np.sum(elastic.coef_ == 0)}개")
ElasticNet은 l1_ratio로 L1과 L2 비율을 조절할 수 있어서,
"둘 중 뭘 쓸지 모르겠다" 싶으면 ElasticNet으로 시작하는 것도 방법입니다.
정리
정규화는 결국 "모델이 너무 복잡해지지 않도록 브레이크를 거는 것"입니다.
1편에서 과적합 해결책 중 하나로 잠깐 나왔던 내용인데,
직접 코드를 돌려보니까 왜 필요한지 확 와닿더라고요.
1. L1 (Lasso) — 가중치를 0으로 만들어서 불필요한 특성을 제거. 특성 선택 효과
2. L2 (Ridge) — 가중치를 골고루 줄여서 과적합 방지. 전반적 안정성
3. alpha — 벌금 강도. 교차검증으로 최적값을 찾아야 함. 스케일링 필수
다음 편(4편)에서는 그래디언트 부스팅을 다룹니다.
약한 모델 여러 개를 순서대로 쌓아서, 이전 모델의 실수를 보완하는 방식인데 — XGBoost가 왜 캐글 대회에서 그렇게 많이 쓰이는지 직접 확인해봅니다.