
[머신러닝 중급 4편] 그래디언트 부스팅 — 약한 모델들이 팀을 이루는 방법
랜덤포레스트랑 뭐가 다른 건지 처음엔 구분이 안 됐습니다. 둘 다 트리를 여러 개 쓰는 건 같은데.. 직접 코드를 돌려보고 나서야 '순차적으로 오차를 보정한다'는 게 무슨 뜻인지 이해했습니다. 그래디언트 부스팅의 원리부터 XGBoost, 특성 중요도 해석까지 정리합니다.
시작하며 — 의사 한 명 vs 의사 여러 명
3편까지 오면서 과적합, SVM, 정규화를 다뤘는데,
이번에는 실무에서 정말 많이 쓰이는 그래디언트 부스팅(Gradient Boosting)을 다뤄봅니다.
이름부터 풀어볼게요. Gradient는 "경사, 기울기"라는 뜻이고, Boosting은 "끌어올리기"입니다.
쉽게 말하면, 오차가 줄어드는 방향(경사)으로 모델을 계속 끌어올린다는 뜻이에요.
수학적으로는 손실 함수의 그래디언트(기울기)를 이용해서 최적화하는 건데, 지금은 이 정도만 알면 충분합니다.
비유를 하나 해볼게요.
병원에서 진단을 받을 때, 의사 한 명의 소견만 듣는 것과
여러 의사가 차례로 검토하면서 이전 의사가 놓친 부분을 보완하는 것 — 어느 쪽이 더 정확할까요?
그래디언트 부스팅이 바로 후자입니다.
약한 모델(주로 결정 트리)을 순서대로 쌓으면서, 이전 모델이 틀린 부분에 집중해서 학습하는 방식이에요.
처음에 "배깅이랑 뭐가 다르지?" 싶었는데, 직접 코드를 돌려보고 차이가 확 와닿았습니다.
그래디언트 부스팅은 어떤 순서로 학습하나요?
그래디언트 부스팅은 약한 모델을 순서대로 쌓으면서, 이전 모델이 틀린 부분(잔차)에 집중해서 학습하는 방식이에요. 첫 번째 모델이 예측하고 남은 오차를 두 번째 모델이 배우고, 또 남은 오차를 세 번째가 배우고 — 이걸 반복하면 점점 정확해집니다.
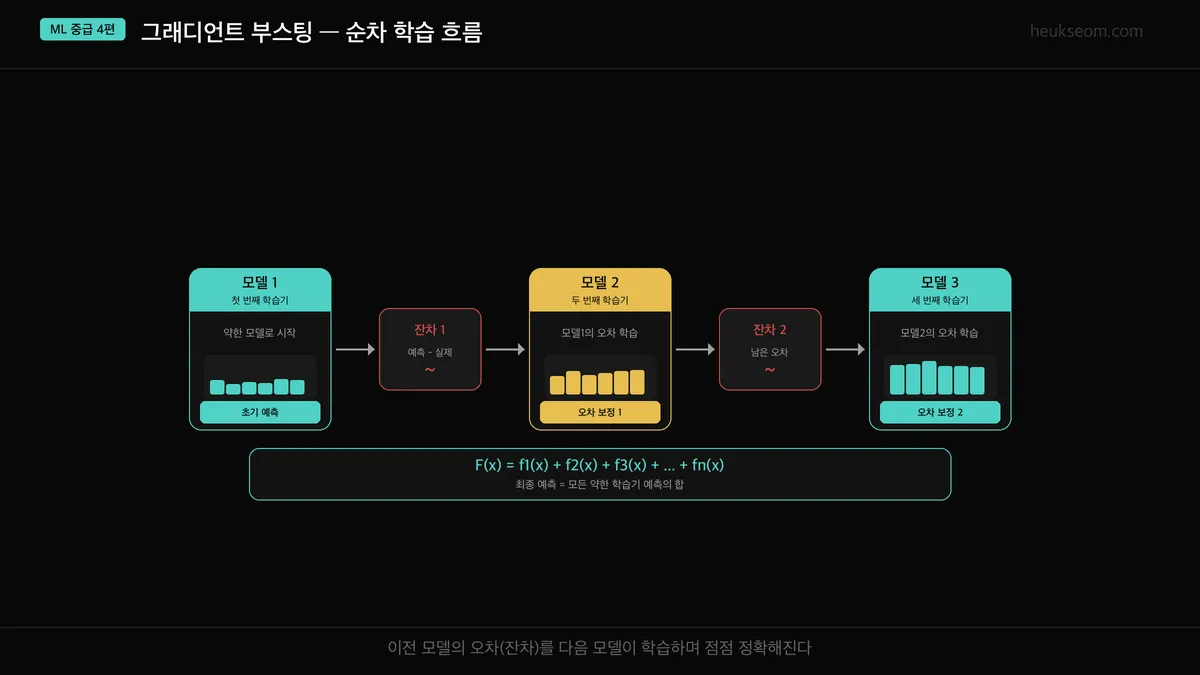
핵심 원리는 간단합니다.
1. 모델 1이 먼저 예측 → 틀린 부분(잔차)이 남음
2. 모델 2가 그 잔차를 학습 → 또 남은 잔차가 생김
3. 모델 3이 또 그 잔차를 학습 → ...
4. 최종 예측 = 모든 모델의 예측을 합산
시험 공부에 비유하면, 틀린 문제만 골라서 다시 풀고, 또 틀린 것만 다시 푸는 방식이에요.
그래서 반복할수록 점점 정확해지는 거죠.
# 핵심 아이디어 (의사 코드)
predictions = 초기_예측값
for i in range(n_estimators):
residuals = 실제값 - predictions # 잔차 계산
new_model = 결정트리.fit(X, residuals) # 잔차를 학습
predictions += learning_rate * new_model.predict(X) # 보정배깅이랑 부스팅, 뭐가 다른 건가요?
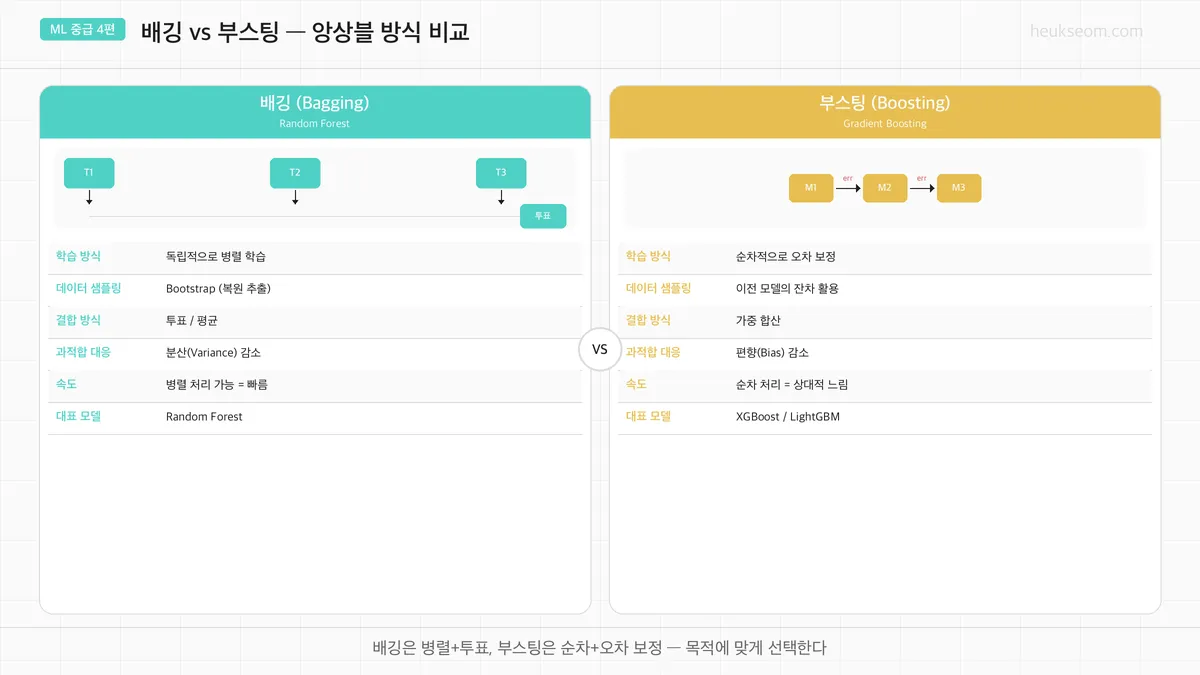
랜덤포레스트(배깅)도 트리를 여러 개 쓰고, 그래디언트 부스팅도 트리를 여러 개 씁니다.
처음에 이 둘이 진짜 헷갈렸는데, 핵심 차이는 이겁니다.
배깅(Random Forest) — 각 트리가 독립적으로 학습하고, 나중에 투표/평균으로 결합. 분산 감소가 목적
부스팅(Gradient Boosting) — 각 트리가 순차적으로 이전 트리의 오차를 보정. 편향 감소가 목적
쉽게 말하면,
배깅은 "여러 명이 각자 풀고 다수결로 정한다"이고,
부스팅은 "한 명이 풀고, 틀린 부분을 다음 사람이 고치고, 또 고치고..."입니다.
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
X, y = make_classification(n_samples=1000, n_features=20, random_state=42)
# 배깅 (Random Forest)
rf = RandomForestClassifier(n_estimators=100, random_state=42)
rf_scores = cross_val_score(rf, X, y, cv=5)
print(f"Random Forest: {rf_scores.mean():.4f} (±{rf_scores.std():.4f})")
# 부스팅 (Gradient Boosting)
gb = GradientBoostingClassifier(n_estimators=100, random_state=42)
gb_scores = cross_val_score(gb, X, y, cv=5)
print(f"Gradient Boosting: {gb_scores.mean():.4f} (±{gb_scores.std():.4f})")
돌려보면 대부분의 경우 그래디언트 부스팅이 살짝 더 높은 점수를 냅니다.
대신 학습 속도는 배깅이 더 빠릅니다 — 병렬 처리가 가능하니까요.
핵심 하이퍼파라미터는 뭐가 있나요?
그래디언트 부스팅을 제대로 쓰려면 이 세 가지를 조절할 줄 알아야 합니다.
처음에 이것저것 바꿔보면서 감을 잡았는데, 정리하면 이렇습니다.
n_estimators — 트리 개수. 많을수록 정확하지만, 너무 많으면 과적합 + 느려짐
learning_rate — 각 트리의 기여도. 작을수록 천천히 학습 (보통 0.01~0.3). n_estimators와 반비례로 조절
max_depth — 각 트리의 깊이. 부스팅에서는 보통 3~8 정도의 얕은 트리를 씀 (약한 학습기 원칙)
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import train_test_split
import numpy as np
X, y = make_classification(n_samples=1000, n_features=20, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
# learning_rate와 n_estimators의 관계
configs = [
(0.3, 50, 3),
(0.1, 100, 3),
(0.05, 200, 3),
(0.01, 500, 3),
(0.1, 100, 5),
(0.1, 100, 8),
]
print(f"{'lr':>6} {'n_est':>6} {'depth':>6} {'train':>8} {'test':>8}")
print("-" * 42)
for lr, n_est, depth in configs:
gb = GradientBoostingClassifier(
learning_rate=lr, n_estimators=n_est, max_depth=depth, random_state=42
)
gb.fit(X_train, y_train)
tr = gb.score(X_train, y_train)
te = gb.score(X_test, y_test)
print(f"{lr:>6.2f} {n_est:>6d} {depth:>6d} {tr:>8.4f} {te:>8.4f}")
이걸 돌려보면 learning_rate=0.01에 n_estimators=500 같은 조합이 꽤 좋은 결과를 보여줍니다.
근데 학습 시간이 오래 걸리죠. 그래서 실무에서는 learning_rate=0.1, n_estimators=100~300 정도에서 시작해서 튜닝합니다.
XGBoost는 왜 실무에서 많이 쓰이나요?
sklearn의 GradientBoostingClassifier도 쓸 만하지만,
실무에서는 대부분 XGBoost를 씁니다.
캐글 대회에서 상위권 솔루션의 대부분이 XGBoost였던 시절이 있었을 정도예요.
XGBoost의 장점
- 속도가 빠름 (병렬 처리, 캐시 최적화)
- 자체 정규화 내장 (L1, L2)
- 결측치 자동 처리
- early_stopping으로 과적합 방지
# pip install xgboost
import xgboost as xgb
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_classification
X, y = make_classification(n_samples=1000, n_features=20, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
model = xgb.XGBClassifier(
n_estimators=200,
learning_rate=0.1,
max_depth=5,
eval_metric='logloss',
random_state=42,
)
# early_stopping: 성능이 안 좋아지면 자동 중단
model.fit(
X_train, y_train,
eval_set=[(X_test, y_test)],
verbose=False,
)
# 참고: XGBoost 최신 버전에서는 early_stopping_rounds를
# XGBClassifier 생성자에 넣습니다:
# model = xgb.XGBClassifier(..., early_stopping_rounds=20)
print(f"Train score: {model.score(X_train, y_train):.4f}")
print(f"Test score: {model.score(X_test, y_test):.4f}")
print(f"Best iteration: {model.best_iteration}")
early_stopping이 진짜 편합니다. n_estimators를 크게 잡아놓고,
더 이상 성능이 안 좋아지면 알아서 멈추거든요. 과적합 방지도 되고 시간도 절약됩니다.
특성 중요도는 어떻게 확인하나요?
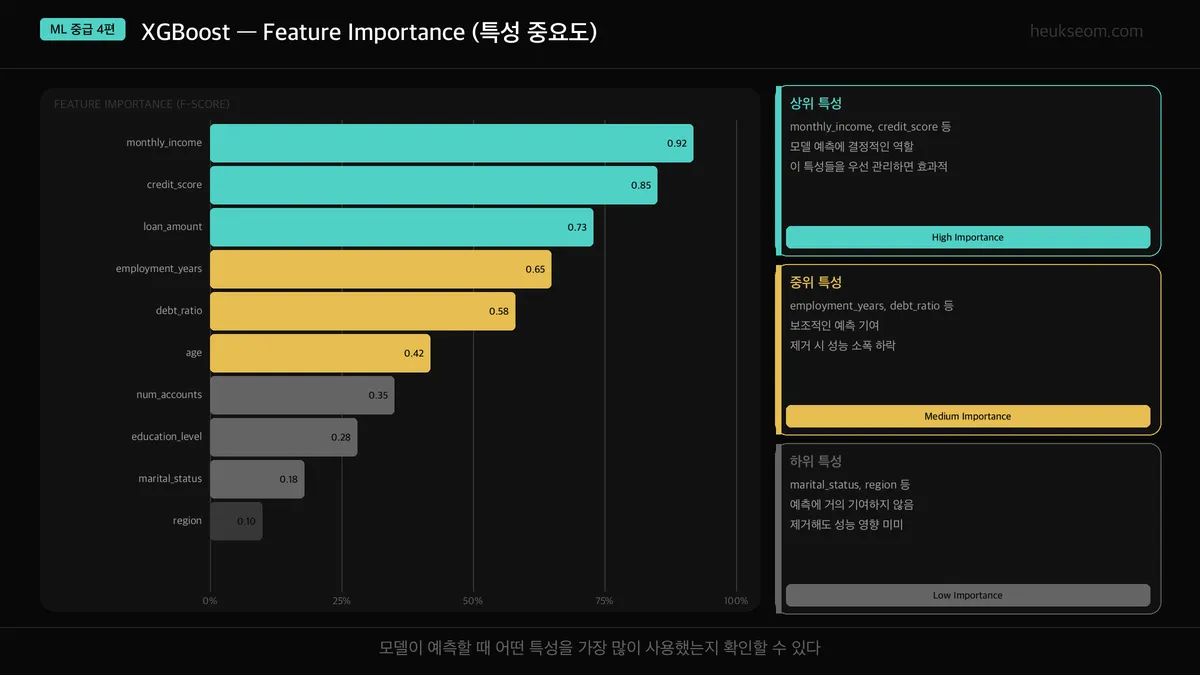
그래디언트 부스팅의 큰 장점 중 하나가 특성 중요도(feature importance)를 볼 수 있다는 겁니다.
"이 모델이 예측할 때 어떤 특성을 가장 많이 참고했는지" 확인할 수 있어요.
import matplotlib.pyplot as plt
import numpy as np
# 특성 중요도 시각화
importances = model.feature_importances_
indices = np.argsort(importances)[::-1]
plt.figure(figsize=(10, 6))
plt.title("Feature Importance")
plt.barh(range(len(importances)), importances[indices[::-1]])
plt.yticks(range(len(importances)),
[f"feature_{i}" for i in indices[::-1]])
plt.xlabel("Importance")
plt.tight_layout()
plt.show()
이 결과를 보면 "아, 이 특성은 예측에 거의 기여를 안 하는구나" 하는 것도 보이고,
불필요한 특성을 제거하는 데도 활용할 수 있습니다.
3편에서 배운 Lasso의 특성 선택 효과와 비슷한 맥락이에요.
직접 돌려본 결과 — n_estimators별 학습 곡선
트리를 1개부터 300개까지 늘려가면서 Train/Test 정확도가 어떻게 변하는지 그려봤습니다.
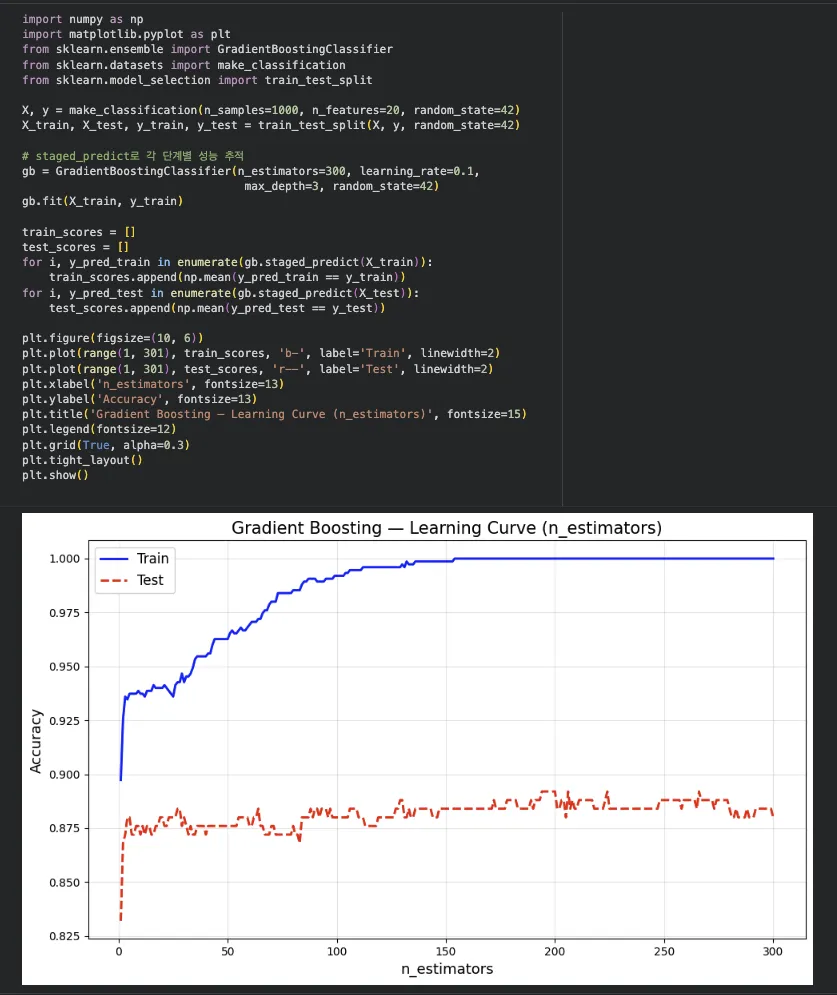
Train은 계속 올라가지만, Test는 어느 시점부터 정체하거나 살짝 떨어짐 → 이게 과적합 신호
이 그래프를 보고 적절한 n_estimators를 정하거나, early_stopping을 활용하면 됨
특성 중요도 — 실제 실행 결과
10개 특성으로 학습시킨 뒤 feature_importances_를 뽑아봤습니다.
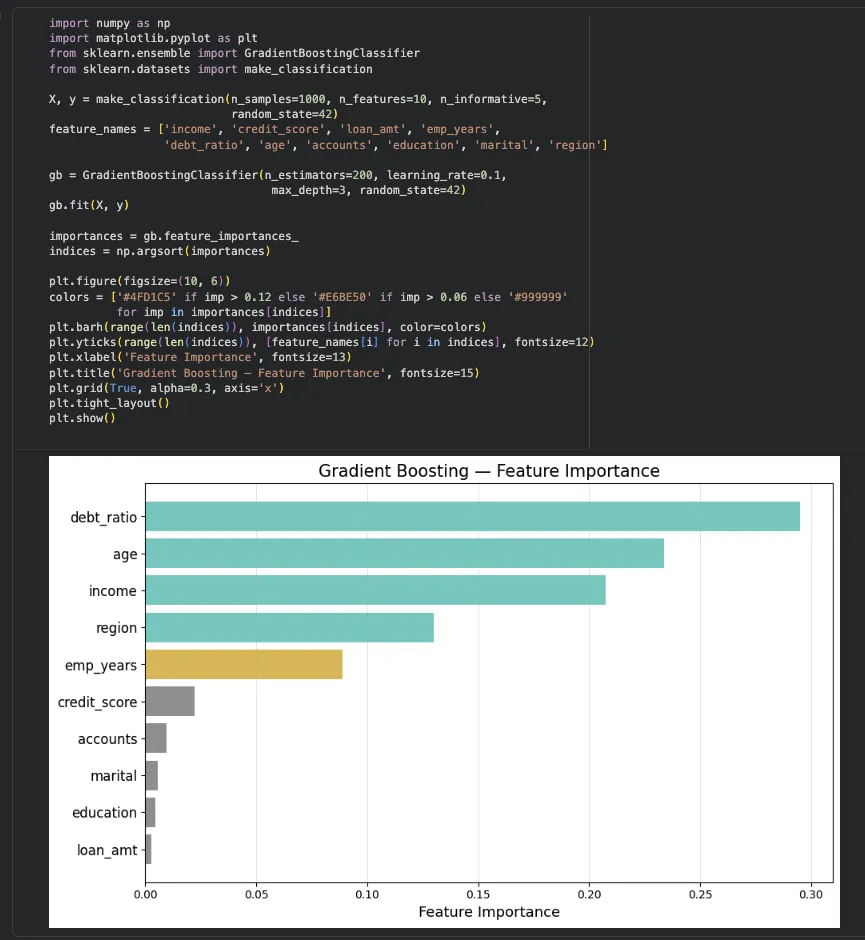
실제로 의미 있는 특성 5개(n_informative=5)가 상위권에 위치하는 걸 볼 수 있음
하위 특성들은 거의 기여를 안 하므로 제거해도 성능에 큰 영향 없음
정리
그래디언트 부스팅은 처음에 개념이 좀 복잡하게 느껴졌는데,
"이전 모델이 틀린 부분을 다음 모델이 보정한다"는 핵심만 잡으면 나머지는 따라옵니다.
1. 순차 학습 — 이전 모델의 잔차(오차)를 다음 모델이 학습. 반복할수록 정확해짐
2. 배깅과의 차이 — 배깅은 병렬+투표, 부스팅은 순차+오차 보정
3. XGBoost — 실무 표준. early_stopping + 특성 중요도 해석이 강점
다음 편(5편)에서는 이상치 탐지를 다룹니다.
카드 사기, 공장 불량품처럼 "1000개 중 1개 이상한 걸 찾아내는" 문제인데 — Isolation Forest가 왜 인기 있는지 직접 확인해봅니다.