
[머신러닝 중급 5편] 이상치 탐지 — 1000명 중 수상한 1명을 찾아내는 법
이상치 탐지는 처음 접했을 때 '그냥 평균에서 멀면 이상치 아닌가?' 싶었습니다. 근데 실제 데이터에서는 그렇게 단순하지 않더라고요. 레이블도 없고, 정상과 비정상의 경계도 애매하고.. Isolation Forest를 직접 돌려보고 나서야 왜 이 방법이 인기 있는지 이해했습니다.
시작하며 — 카드 사기를 어떻게 찾아낼까?
카드 회사에 하루에 100만 건의 거래가 들어온다고 생각해보세요.
그중 사기 거래는 딱 10건. 전체의 0.001%.
이걸 어떻게 찾아낼 수 있을까요?
처음에는 "그냥 평균에서 멀면 이상치 아닌가?" 싶었습니다.
근데 실제 데이터는 그렇게 단순하지 않아요.
다차원 데이터에서 "멀다"는 게 뭔지도 애매하고,
사기 데이터에 레이블이 없는 경우가 대부분입니다.
이번 편에서는 레이블 없이도 이상치를 탐지하는 방법들을 다뤄봅니다.
참고로, 이상치 탐지를 영어로는 Anomaly Detection이라고 합니다. "anomaly"가 "비정상, 이례적인 것"이라는 뜻이에요.
이상치 탐지란 뭔가요?
이상치 탐지는 대량의 정상 데이터 속에서 비정상적인 패턴을 가진 소수의 데이터를 찾아내는 기법이에요. 카드 사기, 공장 불량품 같은 문제에 쓰이는데, 레이블이 없는 비지도 학습 상황에서도 동작한다는 게 핵심입니다.
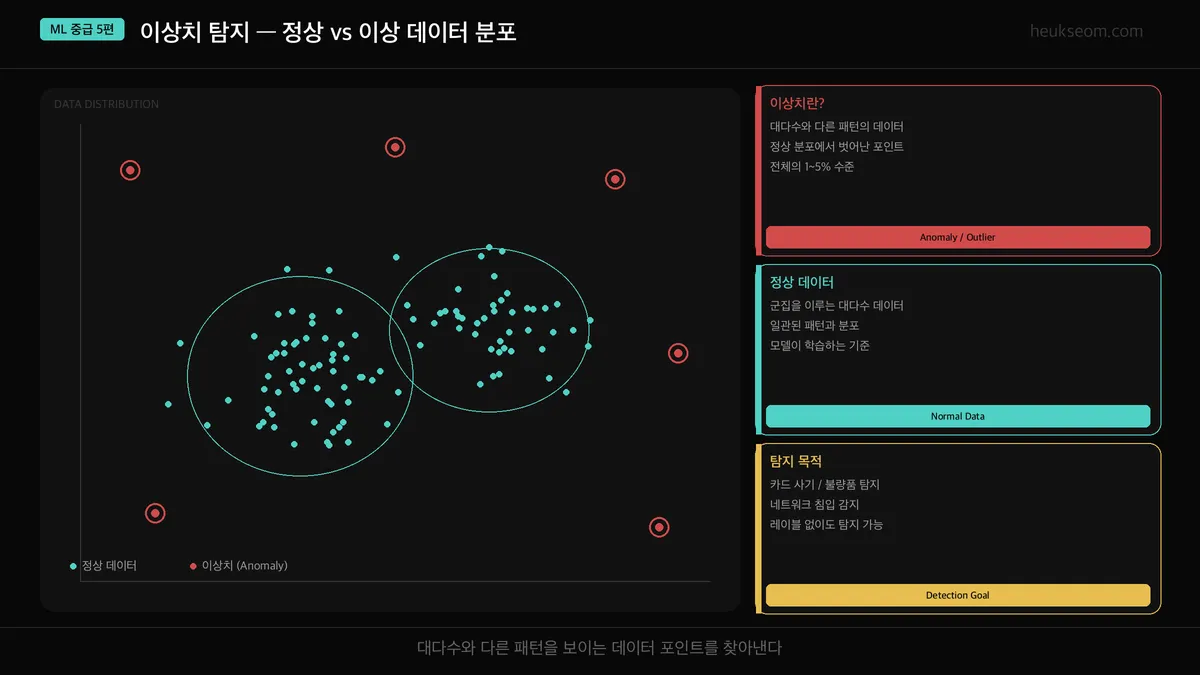
위 그래프에서 민트색 점들은 정상 데이터, 빨간 점들은 이상치입니다.
정상 데이터는 군집을 이루는데, 이상치는 혼자 동떨어져 있죠.
이상치 탐지가 어려운 이유
1. 이상치는 전체의 1~5%에 불과 → 극심한 불균형
2. 레이블이 없는 경우가 대부분 → 비지도 학습 필요
3. "무엇이 정상인지"조차 정의하기 어려울 수 있음
Isolation Forest는 어떤 원리로 이상치를 찾나요?
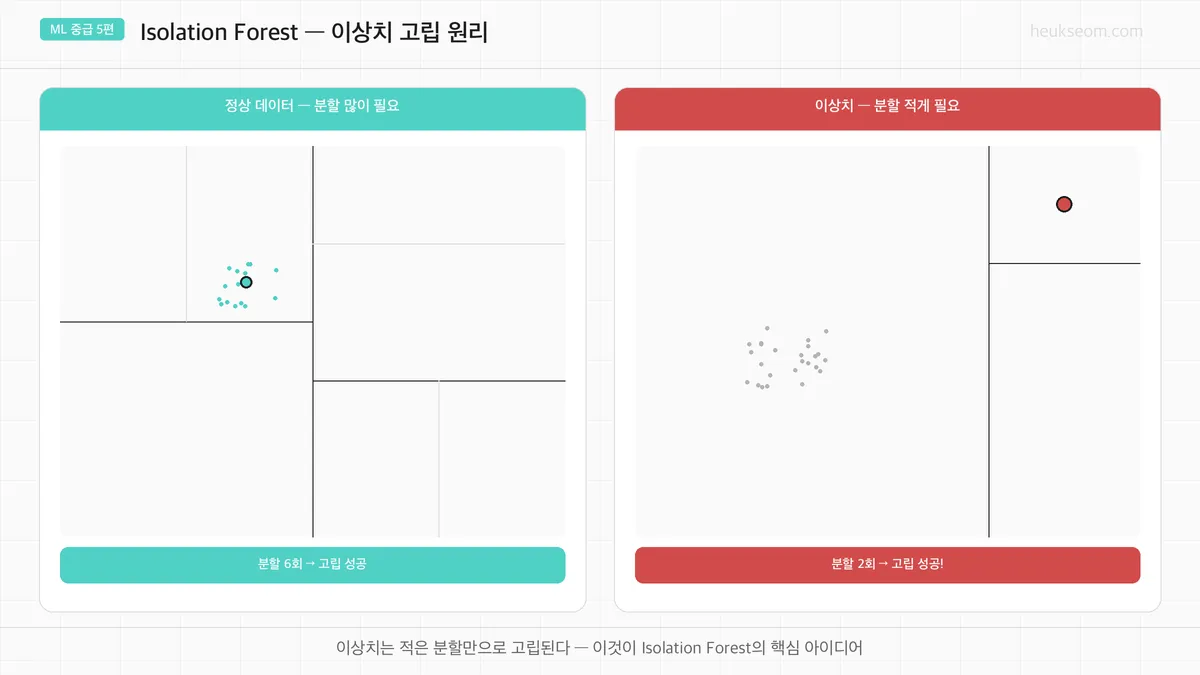
Isolation Forest의 아이디어는 정말 심플합니다.
데이터를 랜덤으로 분할(split)할 때,
정상 데이터는 다른 데이터와 뭉쳐 있어서 고립시키려면 분할을 많이 해야 하고,
이상치는 혼자 떨어져 있어서 적은 분할만으로 바로 고립됨
분할 횟수가 적을수록 = 이상치일 가능성 높음
이거 처음 읽었을 때 "이렇게 단순한 아이디어가 잘 돼?" 싶었는데,
직접 돌려보니까 진짜 잘 됩니다. 속도도 빠르고요.
from sklearn.ensemble import IsolationForest
import numpy as np
# 정상 데이터 생성 (2개 군집)
np.random.seed(42)
normal1 = np.random.randn(200, 2) * 0.5 + [2, 2]
normal2 = np.random.randn(150, 2) * 0.5 + [6, 6]
normal = np.vstack([normal1, normal2])
# 이상치 추가 (랜덤 위치에 10개)
anomalies = np.random.uniform(low=-2, high=10, size=(10, 2))
X = np.vstack([normal, anomalies])
# Isolation Forest 학습
iso = IsolationForest(contamination=0.03, random_state=42)
predictions = iso.fit_predict(X)
# -1: 이상치, 1: 정상
n_anomalies = (predictions == -1).sum()
print(f"탐지된 이상치: {n_anomalies}개 / 전체 {len(X)}개")
print(f"이상치 비율: {n_anomalies / len(X) * 100:.1f}%")
contamination은 "전체 데이터에서 이상치 비율이 대략 얼마나 될 것 같은지" 알려주는 파라미터입니다.
정확한 비율을 몰라도 대략적인 추정치를 넣으면 됩니다.
처음에 이 값을 어떻게 정해야 하나 고민했는데, 보통 0.01~0.05 사이에서 시작하면 됩니다.
One-Class SVM은 어떻게 다른가요?
2편에서 SVM을 다뤘었는데, One-Class SVM은 그 변형입니다.
보통 SVM은 두 클래스를 분리하지만, One-Class SVM은 정상 데이터만 보고 경계를 학습합니다.
정상 데이터를 둘러싸는 경계를 만들고,
그 경계 밖에 있으면 이상치로 판단
커널 트릭도 쓸 수 있어서 비선형 경계도 가능
from sklearn.svm import OneClassSVM
from sklearn.preprocessing import StandardScaler
# 스케일링 (SVM은 스케일링 필수 — 2편에서 배운 내용)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# One-Class SVM
ocsvm = OneClassSVM(kernel='rbf', gamma='scale', nu=0.03)
predictions_svm = ocsvm.fit_predict(X_scaled)
n_anomalies_svm = (predictions_svm == -1).sum()
print(f"One-Class SVM 탐지: {n_anomalies_svm}개")
nu 파라미터가 Isolation Forest의 contamination과 비슷한 역할을 합니다.
단점은 데이터가 크면 느려요. 커널 연산이 비싸서요.
이상치 탐지 알고리즘, 언제 뭘 써야 하나요?

Isolation Forest — 범용적. 빠르고 대부분의 상황에서 잘 동작. 첫 번째 선택지
One-Class SVM — 비선형 경계가 필요할 때. 데이터가 작으면 정밀도 높음
LOF (Local Outlier Factor) — 밀도 기반. 로컬 이상치 탐지에 강함. 군집 내 이상치도 잡음
from sklearn.ensemble import IsolationForest
from sklearn.svm import OneClassSVM
from sklearn.neighbors import LocalOutlierFactor
import numpy as np
# 3가지 알고리즘 비교
models = {
'Isolation Forest': IsolationForest(contamination=0.03, random_state=42),
'One-Class SVM': OneClassSVM(kernel='rbf', gamma='scale', nu=0.03),
'LOF': LocalOutlierFactor(n_neighbors=20, contamination=0.03),
}
for name, model in models.items():
preds = model.fit_predict(X_scaled) # 모든 모델이 fit_predict 지원
n_anom = (preds == -1).sum()
print(f"{name:>20s} → 탐지된 이상치: {n_anom}개")실무에서 threshold와 anomaly score는 어떻게 쓰나요?
실무에서는 단순히 "이상치다 / 아니다"보다 이상치 점수(anomaly score)를 보는 게 더 유용합니다.
점수가 높을수록 더 이상한 데이터인 거죠.
# Isolation Forest의 anomaly score
iso = IsolationForest(contamination=0.03, random_state=42)
iso.fit(X)
# score_samples: 낮을수록 이상치
scores = iso.score_samples(X)
print(f"정상 데이터 평균 score: {scores[:350].mean():.3f}")
print(f"이상치 평균 score: {scores[350:].mean():.3f}")
# threshold를 직접 조절
threshold = -0.5
custom_pred = np.where(scores < threshold, -1, 1)
print(f"\nthreshold={threshold}일 때 탐지 수: {(custom_pred == -1).sum()}개")contamination 대신 threshold를 직접 조절하는 이유
- contamination은 "비율을 알고 있을 때" 편리
- threshold는 "얼마나 이상해야 이상치로 볼 것인지" 직접 제어 가능
- 실무에서는 score 분포를 보고 threshold를 정하는 경우가 많음
직접 돌려본 결과 — Isolation Forest 탐지 결과
정상 데이터 2개 군집 + 랜덤 이상치를 넣고 Isolation Forest를 돌려봤습니다.
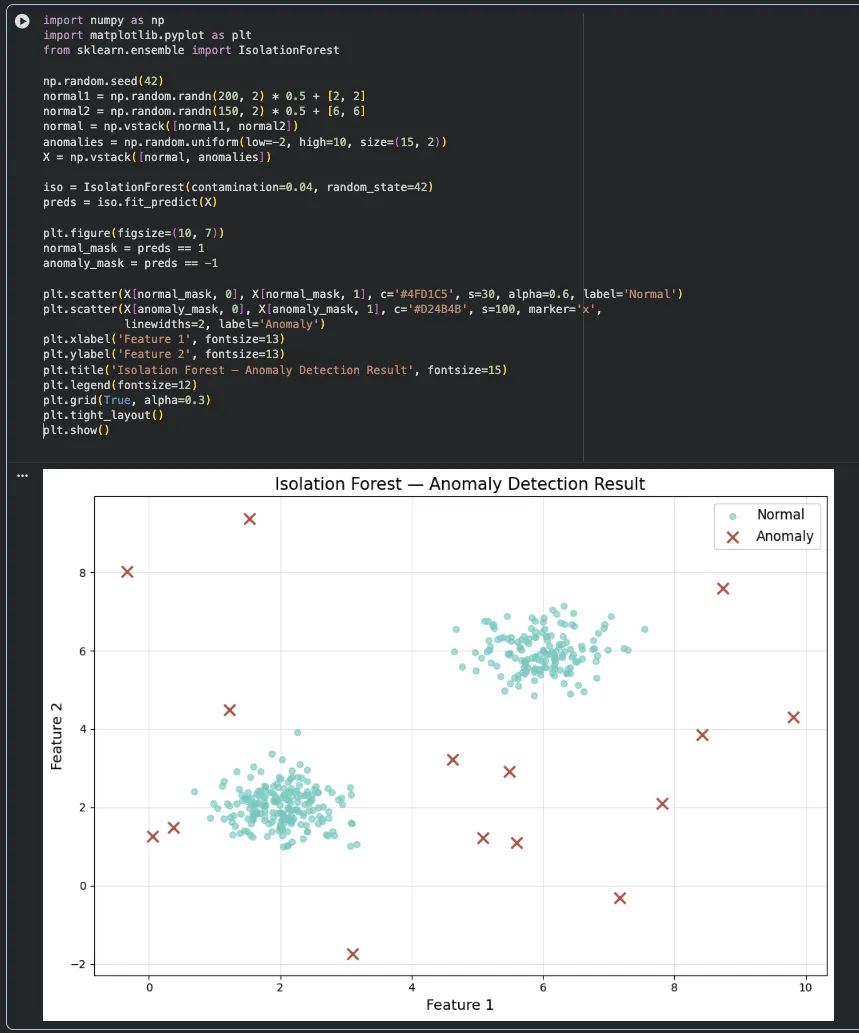
민트색 점이 정상, 빨간 X가 이상치로 탐지된 데이터
군집에서 멀리 떨어진 포인트들이 정확하게 이상치로 잡힌 걸 볼 수 있음
Anomaly Score 분포는 어떻게 생겼나요?
score_samples()로 각 데이터의 이상치 점수를 뽑아서 히스토그램으로 그려봤습니다.
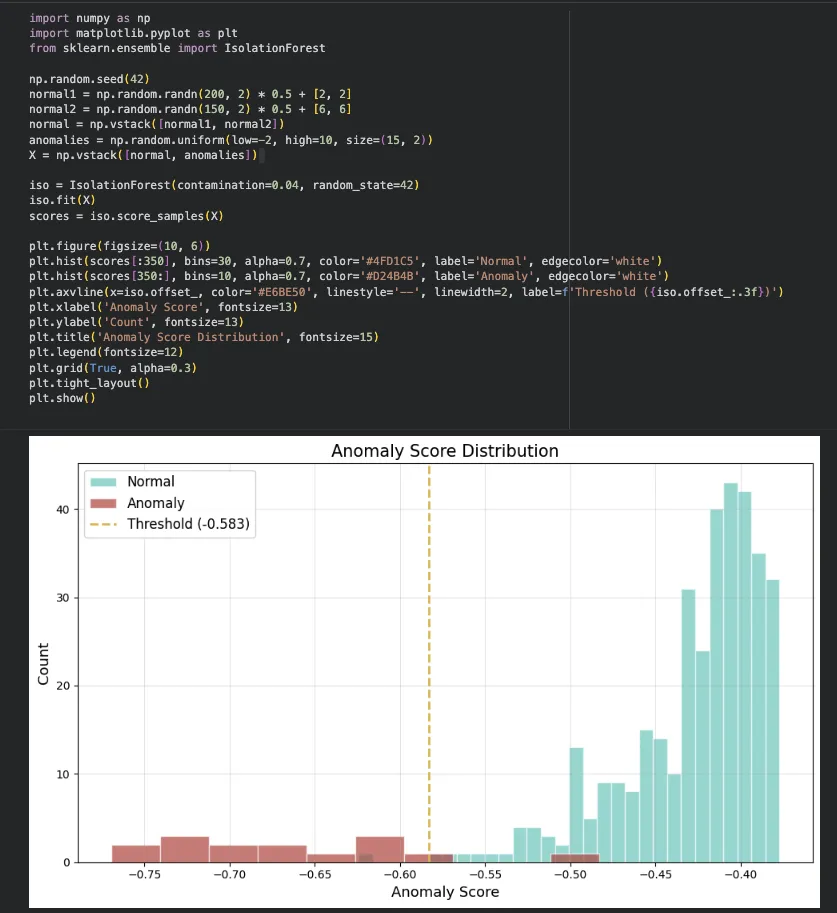
정상 데이터(민트)는 score가 높은 쪽에 몰려 있고, 이상치(빨강)는 낮은 쪽에 분포
노란 점선이 threshold — 이 선 아래에 있으면 이상치로 판정
정리
이상치 탐지는 "정답이 없는 상태에서 이상한 걸 찾아내야 하는" 어려운 문제입니다.
근데 Isolation Forest 같은 알고리즘 덕분에 생각보다 쉽게 시작할 수 있어요.
1. Isolation Forest — 이상치는 적은 분할로 고립된다. 빠르고 범용적
2. One-Class SVM — 정상 경계를 학습. 비선형 경계 가능하지만 느림
3. anomaly score — 이상치 여부보다 "얼마나 이상한지" 점수로 보는 게 실무적
다음 편(6편, 마지막)에서는 주성분 분석(PCA)을 다룹니다.
100개 특성을 2개로 줄여도 핵심 정보가 남는 이유 — 차원 축소의 원리를 정리합니다.