
[머신러닝 실전 3편] "남자/여자"를 모델은 못 읽는다 — 피처 엔지니어링 실전
2편에서 결측치와 이상치를 처리하고 바로 모델에 넣었더니 에러가 났습니다. gender='Male'을 모델이 이해하지 못한 겁니다. 범주형을 숫자로 바꾸는 인코딩, 스케일을 맞추는 스케일링, 새 변수를 만드는 파생변수까지 — 모델이 먹을 수 있는 형태로 데이터를 가공하는 과정을 정리했습니다.
시작하며 — 모델에 넣었더니 에러가 났다
2편에서 결측치도 처리하고 이상치도 확인했으니, 이제 모델에 넣으면 되겠지? 싶었습니다.
그래서 바로 돌려봤는데 — ValueError: could not convert string to float: 'Male'
아... 맞다. 모델은 숫자만 먹습니다.
gender, Contract, InternetService 같은 범주형 컬럼은 문자열입니다.
이걸 숫자로 바꾸는 과정이 인코딩이고,
숫자들 사이의 스케일을 맞추는 게 스케일링입니다.
솔직히 처음에는 "그냥 Male=1, Female=0 하면 되는 거 아닌가?" 싶었는데,
Contract처럼 3개 이상 카테고리가 있으면 단순 숫자 매핑이 문제를 일으킵니다.
Month-to-month=0, One year=1, Two year=2로 하면
모델이 "Two year는 Month-to-month의 2배"라고 오해합니다 ㅋㅋ
피처 엔지니어링 전후로 뭐가 달라지나요?
피처 엔지니어링을 거치면 모델이 이해할 수 없던 범주형 텍스트 데이터가 숫자로 변환되고, 스케일이 달랐던 수치형 변수들이 동일한 범위로 정규화됩니다. 기존 변수를 조합해서 새로운 파생변수도 만들 수 있어 모델 성능이 크게 올라갑니다.
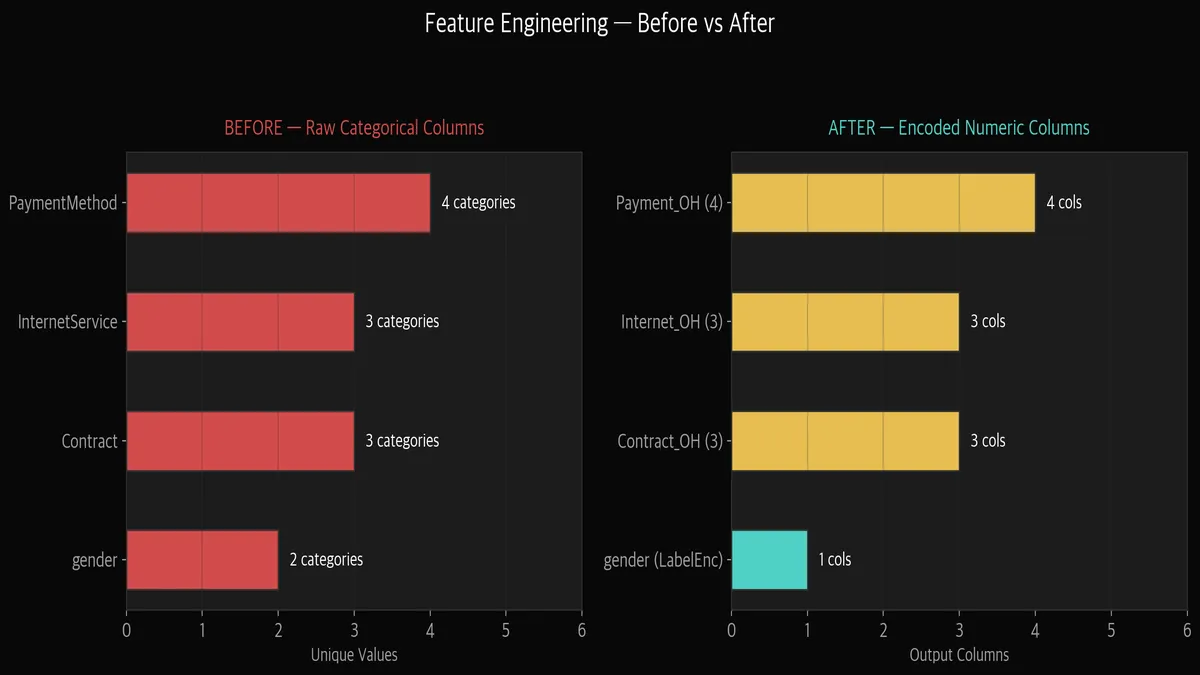
왼쪽이 원본 데이터의 범주형 컬럼들입니다. gender(2), Contract(3), InternetService(3), PaymentMethod(4).
오른쪽이 인코딩 후. gender는 Label Encoding으로 1개 컬럼, 나머지는 One-Hot으로 여러 컬럼으로 펼쳤습니다.
4개 문자열 컬럼 → 8개 숫자 컬럼이 된 겁니다. (drop_first=True로 기준 카테고리 제외)
인코딩은 언제 어떤 방법을 써야 하나요?
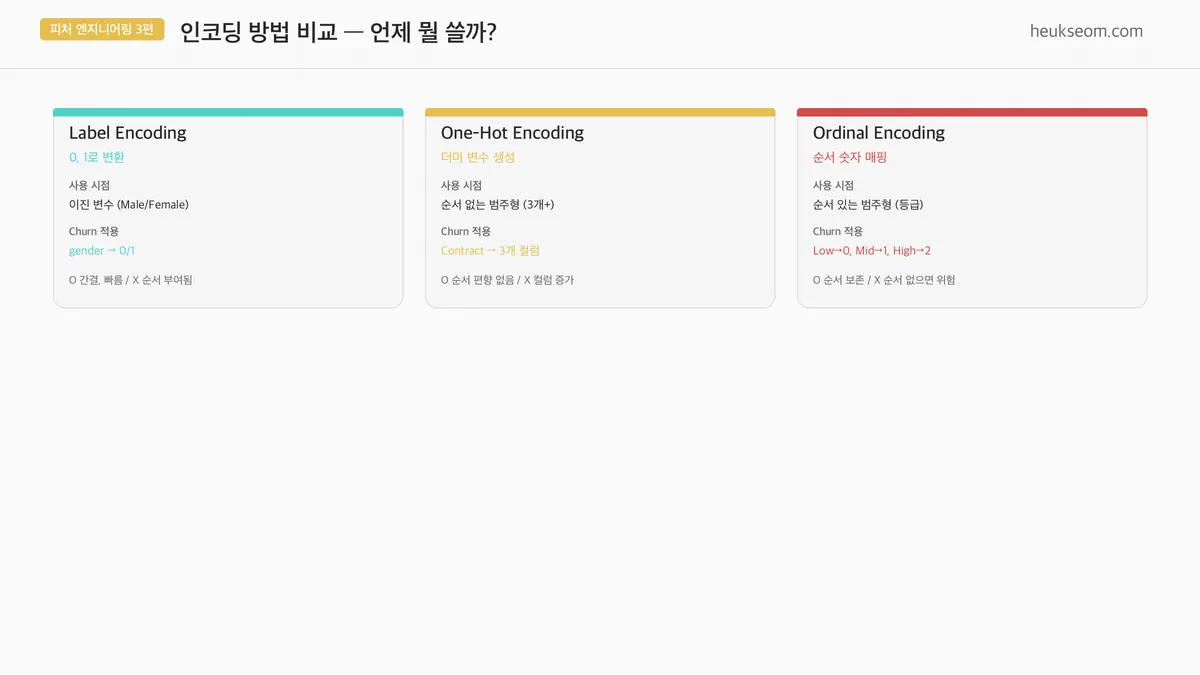
인코딩 방법은 크게 3가지입니다. 핵심은 "순서가 있냐 없냐"입니다.
Label Encoding — 이진 변수(2개)에 적합. gender → 0/1
One-Hot Encoding — 순서 없는 다범주에 적합. Contract → 2개 더미 컬럼 (drop_first 시)
Ordinal Encoding — 순서가 의미 있을 때. Low/Mid/High → 0/1/2
(Churn 데이터에는 해당 없음)
제가 처음에 실수했던 게, Contract를 Label Encoding으로 처리한 거였습니다.
Month-to-month=0, One year=1, Two year=2로 했는데,
모델이 "Two year가 Month-to-month보다 2배 크다"고 학습했습니다.
계약 유형에 크기 순서가 없으니까, One-Hot으로 해야 맞는 것이었습니다.
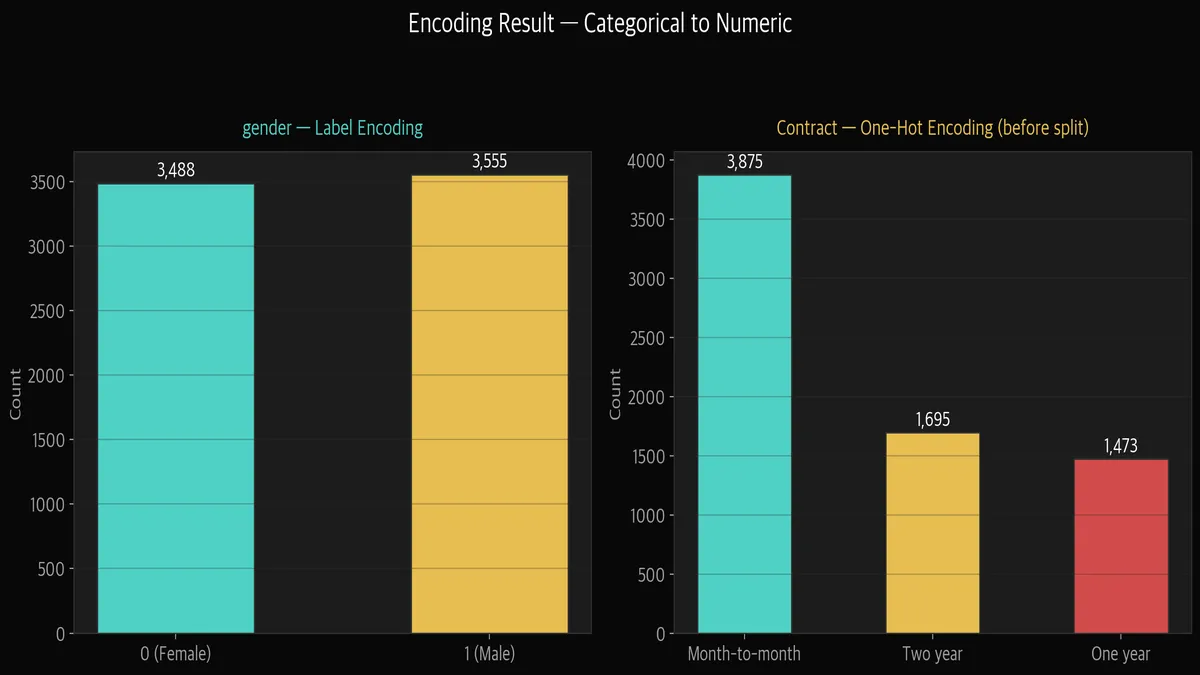
왼쪽은 gender를 Label Encoding한 결과. Female=0, Male=1로 거의 반반입니다.
오른쪽은 Contract의 분포. Month-to-month가 3,875명으로 가장 많고,
이걸 One-Hot(drop_first=True)으로 펼치면 Contract_One year, Contract_Two year 2개 컬럼이 됩니다. Month-to-month는 둘 다 0일 때로 표현됩니다.
# Label Encoding — 이진 변수
df['gender'] = df['gender'].map({'Female': 0, 'Male': 1})
# SeniorCitizen은 이미 0/1이라 그대로 사용
# One-Hot Encoding — 다범주 변수
df_encoded = pd.get_dummies(df, columns=['Contract', 'InternetService', 'PaymentMethod'],
drop_first=True) # 다중공선성 방지
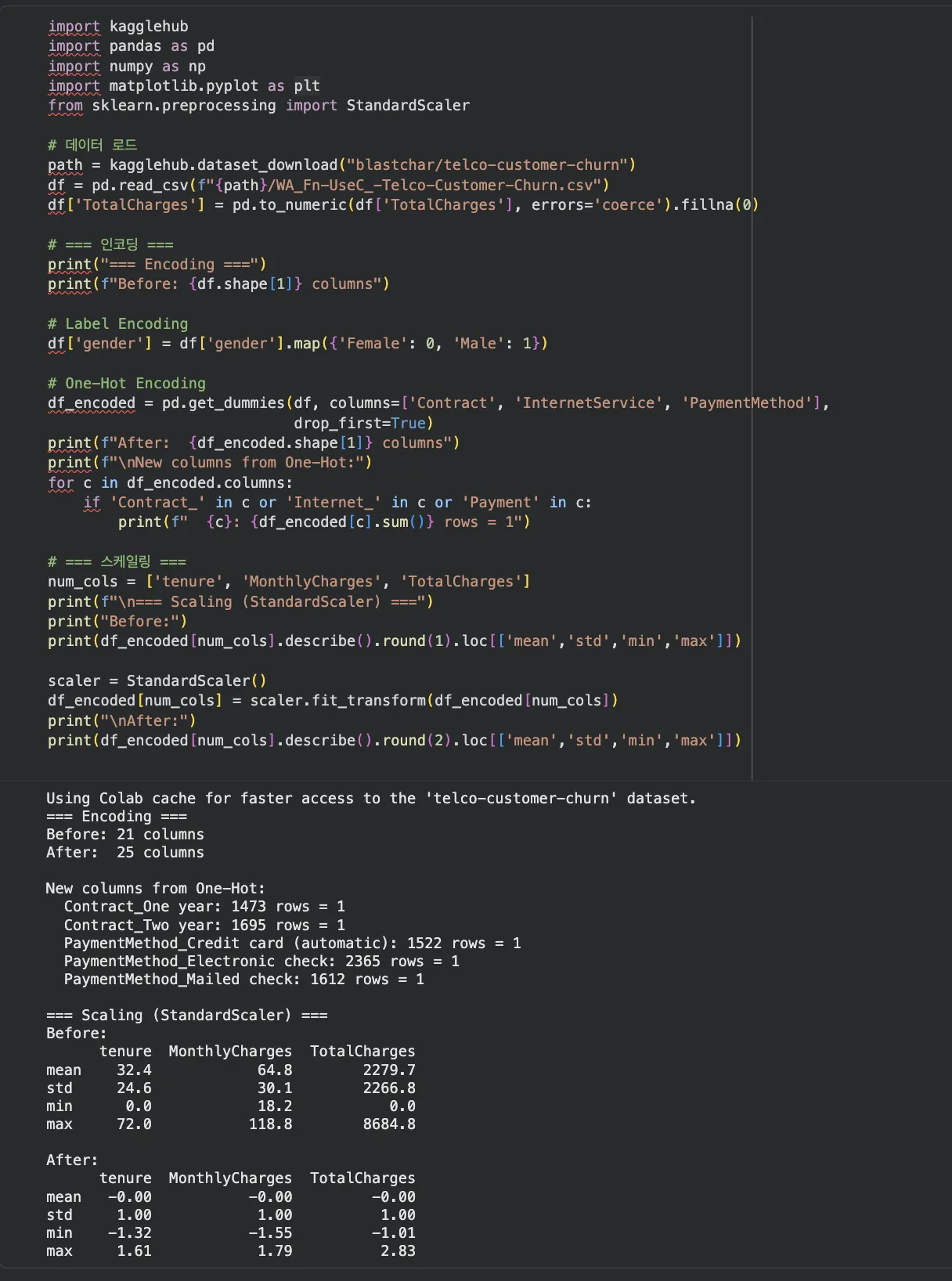
print(f"인코딩 전: {df.shape[1]}개 컬럼")
print(f"인코딩 후: {df_encoded.shape[1]}개 컬럼")Jupyter Notebook 실행 결과
스케일링은 왜 필요한가요?
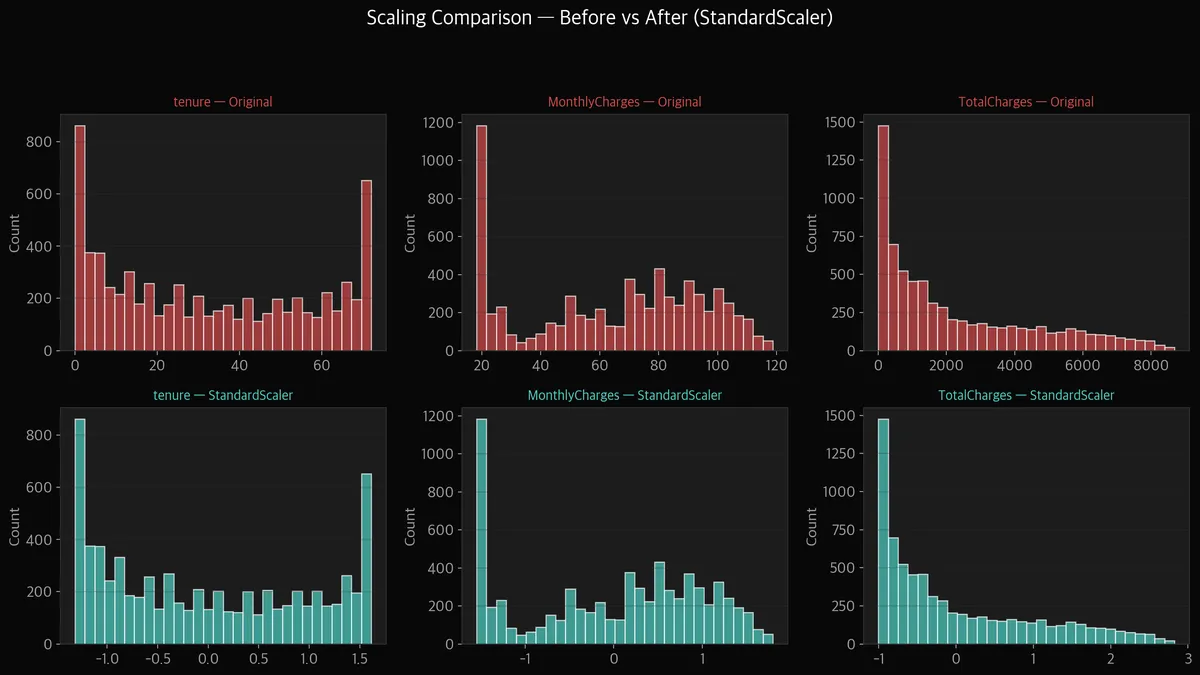
인코딩이 끝났으면 이제 숫자들의 스케일을 맞춰야 합니다.
위 차트를 보면 원본(빨간색) tenure는 0~72, MonthlyCharges는 18~118, TotalCharges는 0~8,684.
스케일이 완전히 다릅니다.
이게 왜 문제냐면, SVM이나 KNN 같은 거리 기반 모델은
큰 값을 가진 변수에 지배당합니다.
TotalCharges가 수천 단위니까, tenure(0~72)의 영향력이 묻혀버립니다.
중급 2편에서 SVM 배울 때 "스케일링 필수"라고 했던 이유가 이것입니다.
아래쪽(민트색)이 StandardScaler 적용 후. 전부 평균 0, 표준편차 1 근처로 맞춰졌습니다.
분포 모양은 그대로인데, 스케일만 통일된 겁니다.
StandardScaler — 평균 0, 분산 1로 변환. 정규분포 가정. 대부분의 경우 무난
MinMaxScaler — 0~1 범위로 변환. 최소/최대에 민감. 이상치 있으면 비추
RobustScaler — 중앙값과 IQR 기준. 이상치에 강건. 2편에서 이상치 없다고 확인했으니 Standard로 충분
from sklearn.preprocessing import StandardScaler
# 수치형 컬럼만 스케일링
num_cols = ['tenure', 'MonthlyCharges', 'TotalCharges']
scaler = StandardScaler()
df_encoded[num_cols] = scaler.fit_transform(df_encoded[num_cols])
print(df_encoded[num_cols].describe().round(2))
# mean ≈ 0, std ≈ 1 확인파생변수는 어떻게 만드나요?
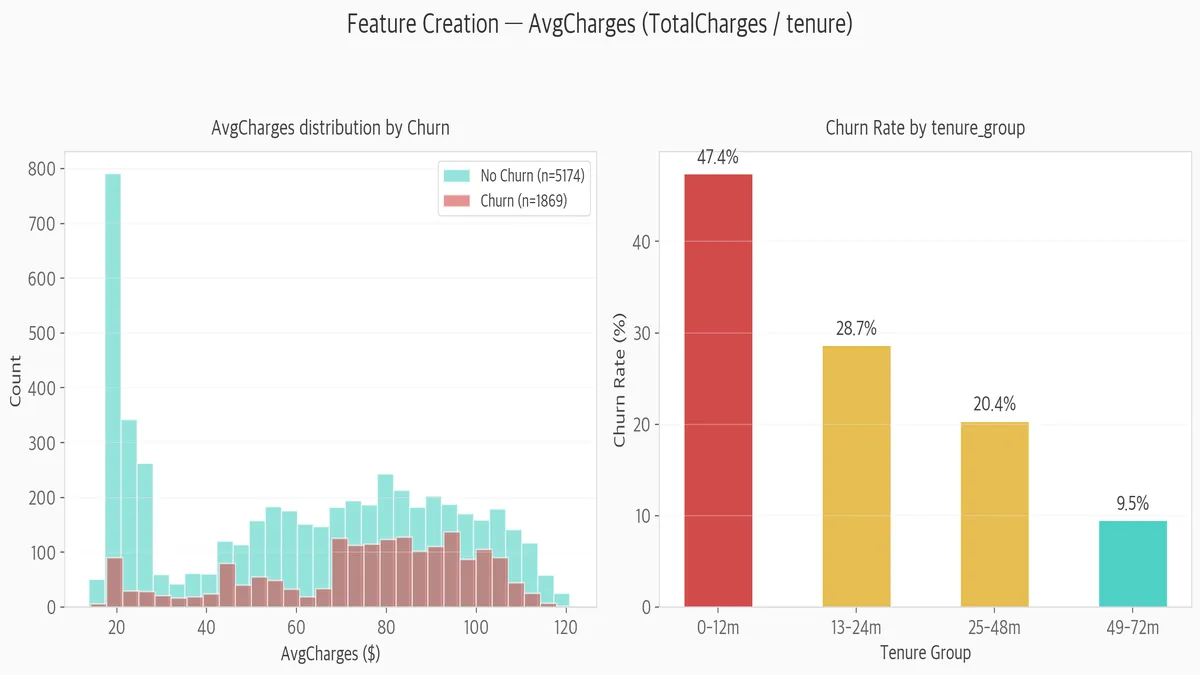
피처 엔지니어링의 진짜 재미는 파생변수 만들기입니다.
기존 변수를 조합해서 모델이 못 보는 패턴을 드러내는 것입니다.
왼쪽 차트: AvgCharges = TotalCharges / tenure (월평균 요금)을 만들어서 Churn별로 비교했습니다.
이탈 고객(빨간색)이 $20 근처에 몰려 있는 게 보입니다.
저렴한 요금제 + 짧은 사용기간 = 이탈 위험이 높다는 패턴이 드러납니다.
오른쪽 차트: tenure_group으로 구간을 나눠봤더니 더 명확합니다.
0~12개월 구간 이탈률이 47.4%로 압도적입니다.
49~72개월 장기 고객은 9.5%밖에 안 됩니다.
이 파생변수 하나만으로도 모델에 강력한 신호를 줄 수 있습니다.
# 파생변수 1: 월평균 요금
df['AvgCharges'] = np.where(df['tenure'] > 0,
df['TotalCharges'] / df['tenure'],
df['MonthlyCharges'])
# 파생변수 2: 재직 기간 구간
bins = [0, 12, 24, 48, 72]
labels = ['0-12m', '13-24m', '25-48m', '49-72m']
df['tenure_group'] = pd.cut(df['tenure'], bins=bins, labels=labels,
include_lowest=True)
# Churn Rate 확인
print(df.groupby('tenure_group')['Churn'].apply(
lambda x: f"{(x=='Yes').mean()*100:.1f}%"
))Jupyter Notebook 실행 결과
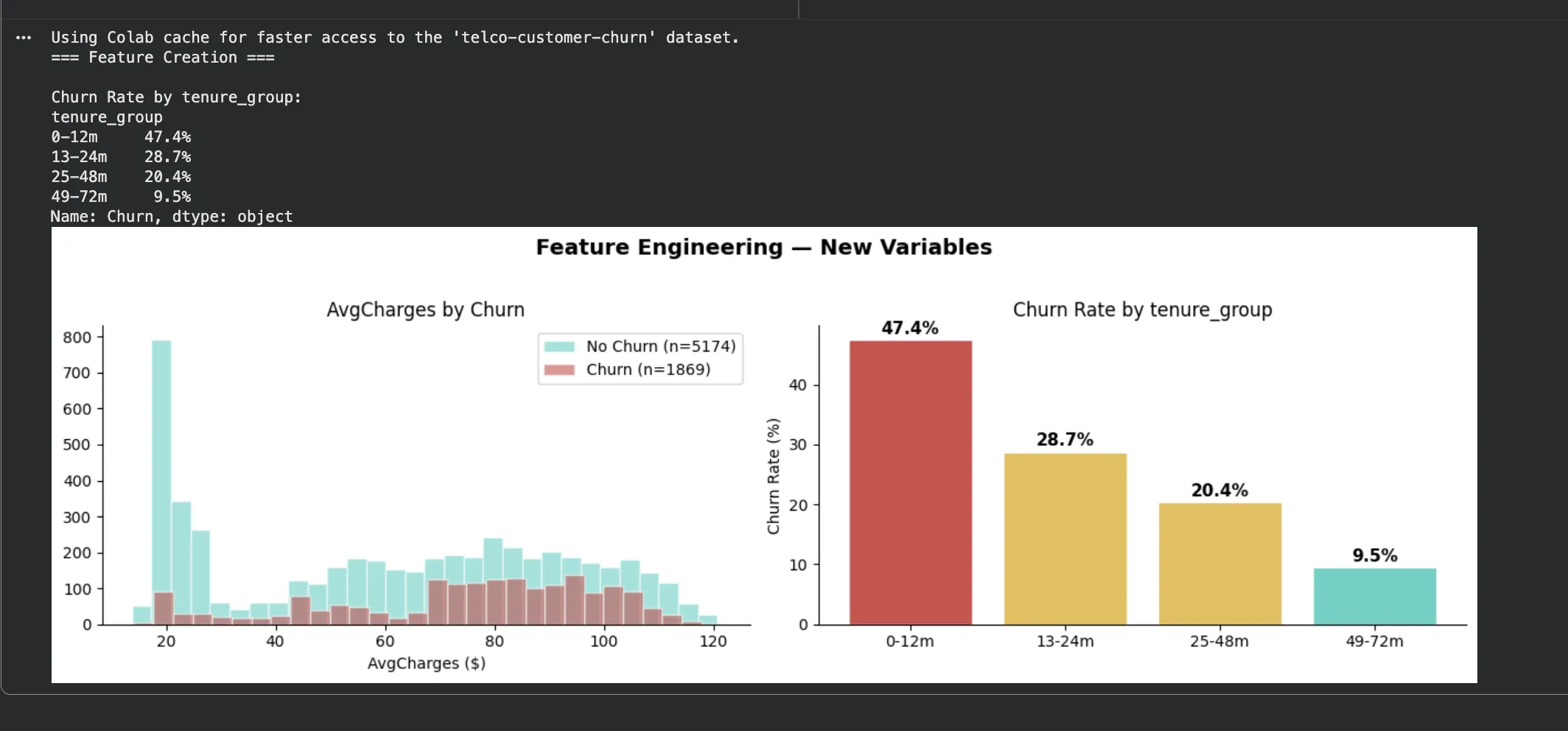
불필요한 컬럼은 어떻게 제거하나요?
마지막으로 모델에 넣으면 안 되는 컬럼을 정리합니다.
customerID — 고유 식별자. 모델이 외워버리면 과적합
원본 범주형 컬럼 — 인코딩한 뒤에는 원본 제거 (중복 정보)
Churn — 타겟 변수는 X에서 분리해야 함
# 불필요 컬럼 제거
drop_cols = ['customerID']
df_final = df_encoded.drop(columns=drop_cols)
# X, y 분리
X = df_final.drop('Churn', axis=1)
y = df_final['Churn'].map({'No': 0, 'Yes': 1})
print(f"최종 피처 수: {X.shape[1]}개")
print(f"샘플 수: {X.shape[0]}개")
print(f"타겟 분포: No={sum(y==0)}, Yes={sum(y==1)}")3편에서 처리한 것들 — 정리
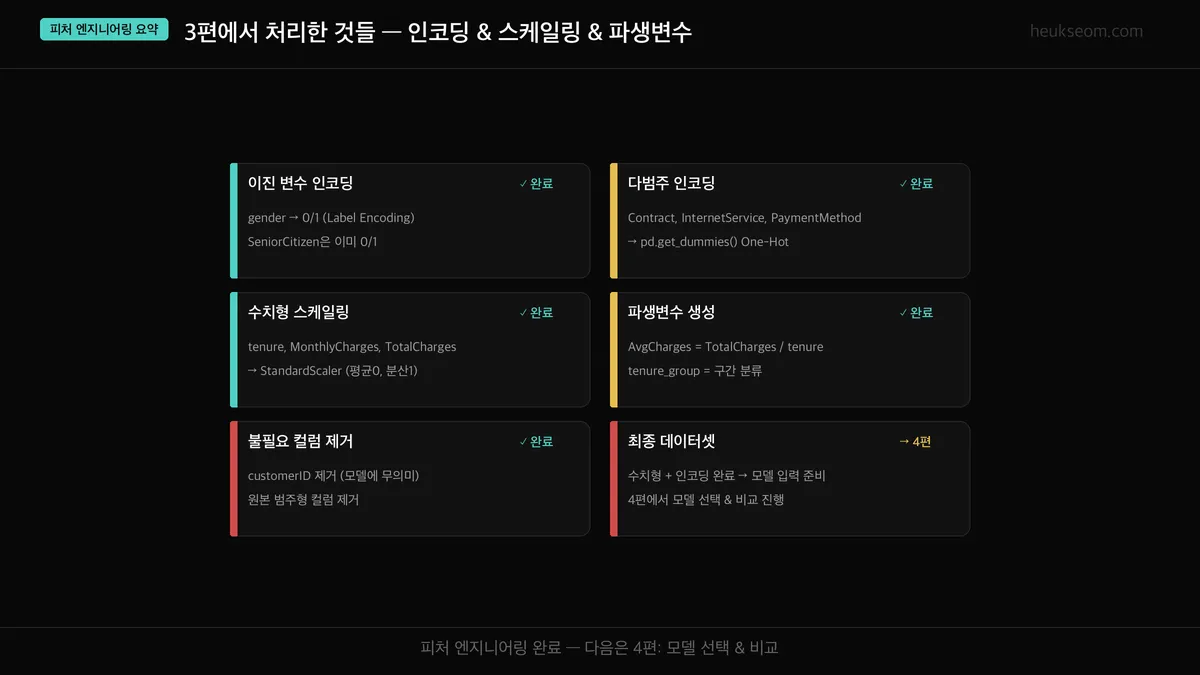
1. 이진 변수 — Label Encoding (gender → 0/1)
2. 다범주 변수 — One-Hot Encoding (Contract, InternetService, PaymentMethod)
3. 스케일링 — StandardScaler (tenure, MonthlyCharges, TotalCharges)
4. 파생변수 — AvgCharges, tenure_group으로 이탈 패턴 강화
5. 컬럼 정리 — customerID 제거, X/y 분리 완료
이번 편에서 가장 인상 깊었던 건, 파생변수의 위력이었습니다.
tenure_group 하나만 만들어도 이탈률 47.4% vs 9.5%라는 극적인 차이가 보였습니다.
좋은 피처 하나가 복잡한 모델보다 강력할 수 있다는 걸 체감했습니다.
다음 편(4편)에서는 드디어 모델을 돌려봅니다.
로지스틱 회귀, 랜덤포레스트, XGBoost 등 5개 모델을 빠르게 비교해보고,
어떤 모델이 이탈 예측을 가장 잘 하는지 확인합니다.