
[머신러닝 실전 5편] 같은 모델인데 셋팅만 바꿨더니 — 하이퍼파라미터 튜닝
4편에서 Gradient Boosting이 종합 1위였습니다. 근데 기본 설정 그대로 쓴 거라 '이게 최선인가?' 싶었습니다. 하이퍼파라미터를 바꿔봤더니 — 사실 기본 설정이 이미 꽤 좋았습니다. GridSearchCV, RandomizedSearchCV로 실험한 과정과, '튜닝이 항상 극적 개선을 주지는 않는다'는 현실적인 교훈을 정리했습니다.
시작하며 — 기본 설정이 최선일까?
4편에서 Gradient Boosting이 종합 1위였습니다.
근데 기본 설정(default) 그대로 돌린 거였습니다.
learning_rate=0.1, max_depth=3, n_estimators=100 — sklearn이 정해준 기본값입니다.
참고: 4편의 Accuracy 80.6%는 교차검증(CV) 평균이고, 이번 편의 79.7%는 최종 테스트셋 점수입니다.
CV 평균과 테스트셋 점수가 약간 다른 건 정상입니다 — 데이터 분할이 다르니까요.
"이걸 바꾸면 더 좋아지지 않을까?" 싶었습니다.
이게 바로 하이퍼파라미터 튜닝입니다.
같은 모델이라도 셋팅을 바꾸면 성능이 달라집니다.
Jupyter 실습 — 데이터 준비 (셀1)
4편까지 쓰던 전처리 코드 그대로입니다. kagglehub로 데이터 받고, 결측치 처리, 인코딩, train_test_split까지.
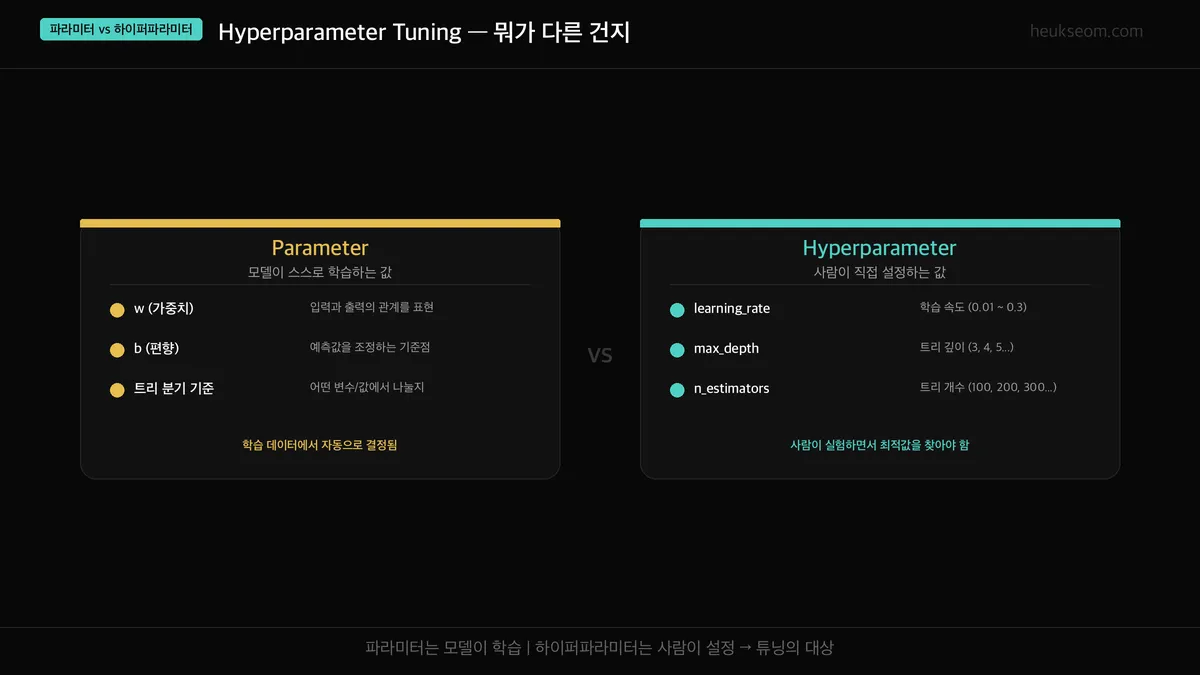
파라미터와 하이퍼파라미터는 뭐가 다른 건가요?
파라미터는 모델이 학습 과정에서 스스로 찾아가는 값(가중치, 편향)이고, 하이퍼파라미터는 학습 전에 사람이 직접 설정하는 값(학습률, 트리 개수, 정규화 강도)입니다. 하이퍼파라미터 튜닝은 GridSearchCV나 RandomizedSearchCV로 최적 조합을 탐색합니다.
이 둘을 헷갈리는 경우가 많습니다. 간단하게 정리하면 —
파라미터(Parameter)는 모델이 학습 데이터에서 스스로 찾아내는 값입니다.
가중치(w), 편향(b), 트리의 분기 기준 같은 것들. 우리가 건드릴 수 없습니다.
하이퍼파라미터(Hyperparameter)는 학습 전에 사람이 직접 설정하는 값입니다.
learning_rate(학습 속도), max_depth(트리 깊이), n_estimators(트리 개수) 같은 것들.
이걸 어떻게 설정하느냐에 따라 같은 모델이라도 성능이 달라집니다.
파라미터 = 모델이 알아서 학습
하이퍼파라미터 = 사람이 실험하면서 최적값을 찾아야 함
문제는 — 조합이 너무 많다는 겁니다. learning_rate 3개 × max_depth 3개 × n_estimators 3개만 해도 27가지입니다.
Jupyter 실습 — Default Gradient Boosting (셀2)
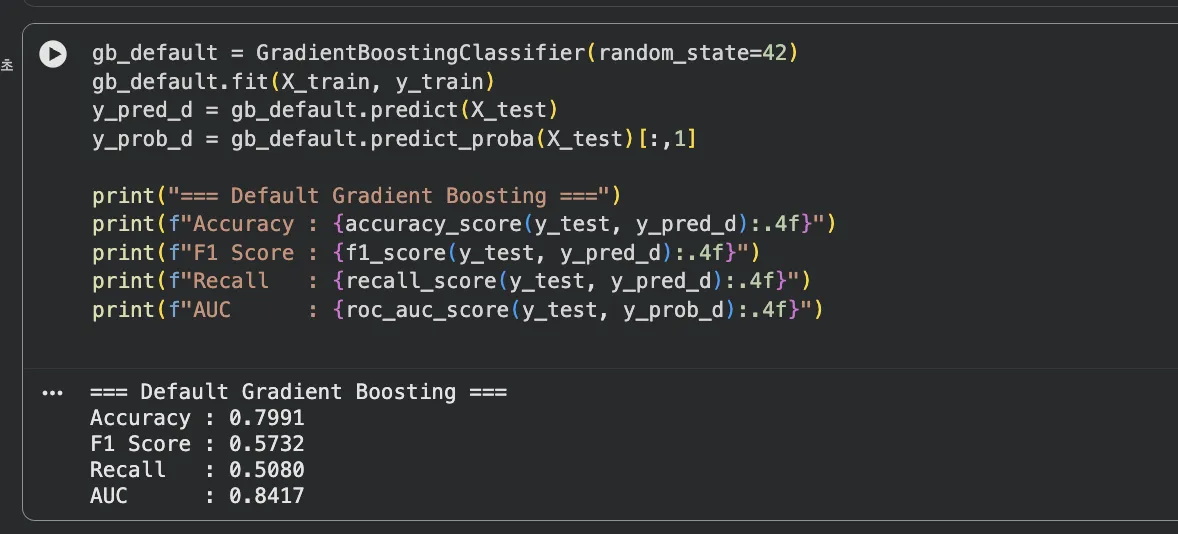
기본 설정 그대로 돌린 Gradient Boosting. Accuracy 0.7991, F1 0.5732, AUC 0.8417. 이게 우리의 기준점(baseline)입니다.
GridSearchCV는 어떻게 최적 조합을 찾나요?
가장 직관적인 방법입니다. 후보 값들의 모든 조합을 격자(Grid) 형태로 탐색합니다.
Churn 데이터에 이렇게 설정했습니다:
learning_rate: [0.05, 0.1, 0.2]
max_depth: [3, 4, 5]
n_estimators: [100, 200, 300]
subsample: [0.8, 1.0]
총 조합: 3 × 3 × 3 × 2 = 54가지
각 조합마다 5-Fold CV = 총 270번 학습
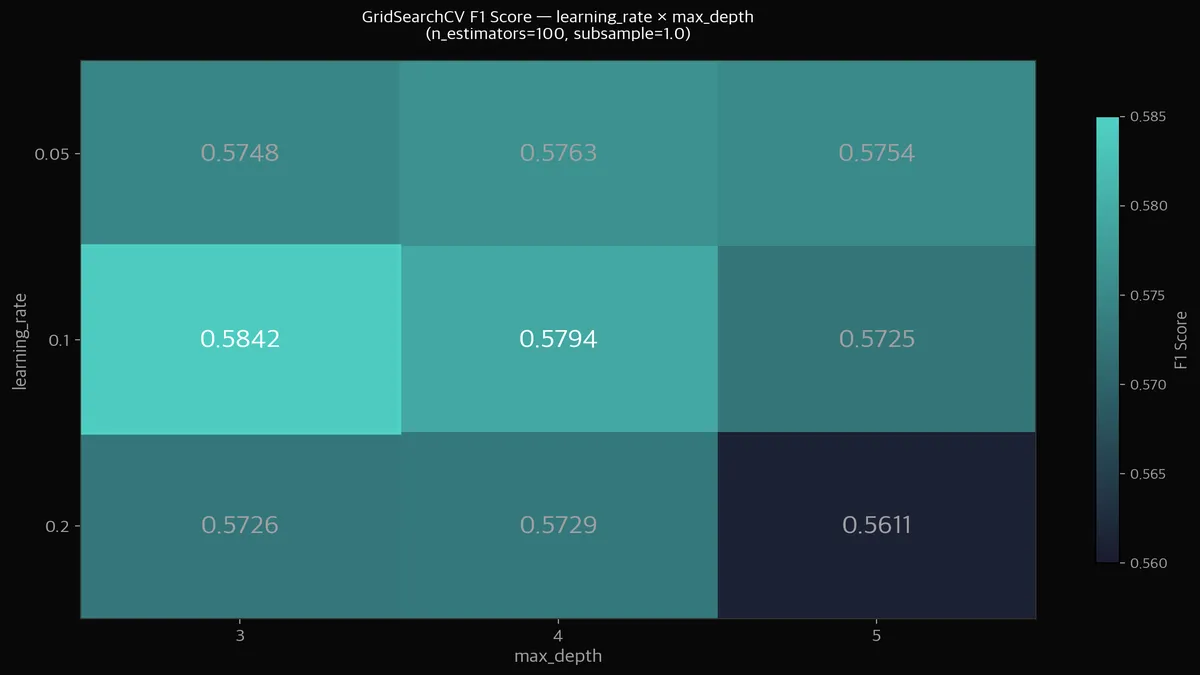
히트맵을 보면 learning_rate=0.1, max_depth=3이 F1 0.5842로 최고점입니다.
그런데... 이게 기본값과 동일합니다 ㅋㅋ
GridSearch 결과 best가 default와 같다는 건, sklearn 기본값이 이미 합리적으로 설정되어 있다는 뜻입니다.
learning_rate가 높아지면(0.2) 성능이 떨어지고, max_depth가 깊어지면(5) 과적합 경향이 보입니다.
Jupyter 실습 — GridSearchCV 실행 (셀3, 약 8분 소요)
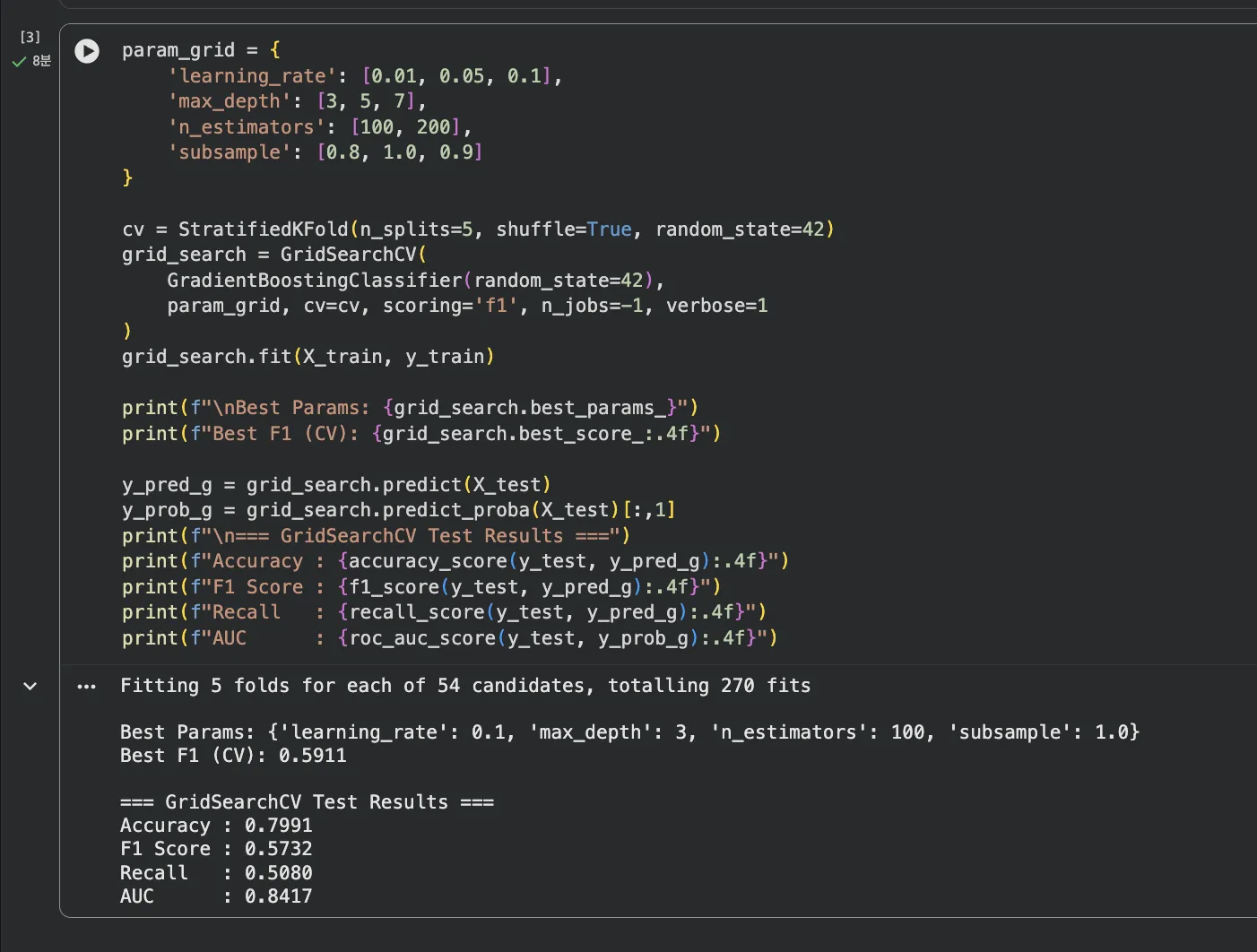
54개 조합 × 5-Fold = 총 270번 학습이라 약 8분 걸립니다.
Gradient Boosting은 트리를 순차적으로 쌓는 모델이라 한 번 학습 자체가 느린 편입니다. 거기에 270번을 반복하니 시간이 걸리는 게 당연합니다.
Colab 무료 GPU로도 이 정도니, 실무에서 조합 수가 수백~수천 개면 시간이 훨씬 더 걸립니다. 그래서 RandomSearch가 필요한 겁니다.
RandomizedSearchCV는 어떻게 다르게 탐색하나요?
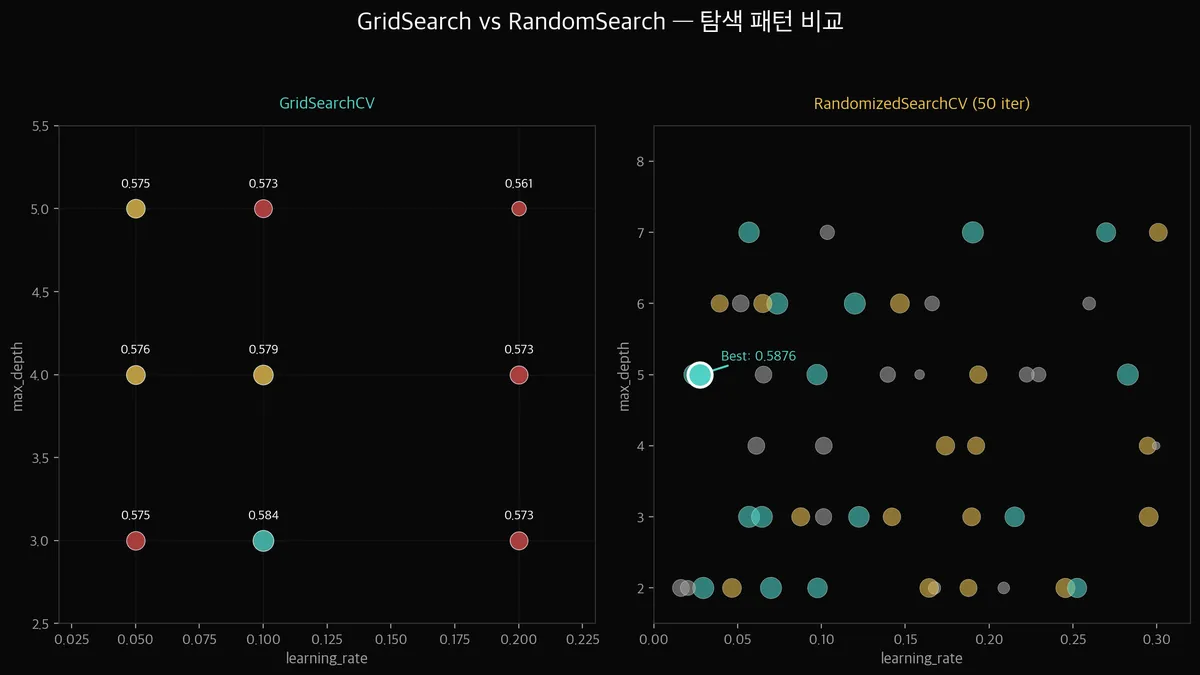
GridSearch는 모든 조합을 다 보지만, 후보 값을 사람이 정해야 합니다.
[0.05, 0.1, 0.2] 사이의 0.07이나 0.12 같은 값은 탐색하지 못합니다.
RandomizedSearchCV는 범위를 정하고 그 안에서 랜덤하게 뽑습니다.
연속 구간을 탐색할 수 있어서, GridSearch가 놓치는 조합을 발견할 수 있습니다.
RandomizedSearchCV (50 iterations)
Best: learning_rate=0.095, max_depth=2, n_estimators=179, subsample=0.76
CV F1 = 0.5876
GridSearch보다 넓은 범위를 탐색해서 depth=2, subsample=0.76이라는 새로운 조합을 발견했습니다.
Jupyter 실습 — RandomizedSearchCV + 최종 비교 (셀4, 약 6분 소요)
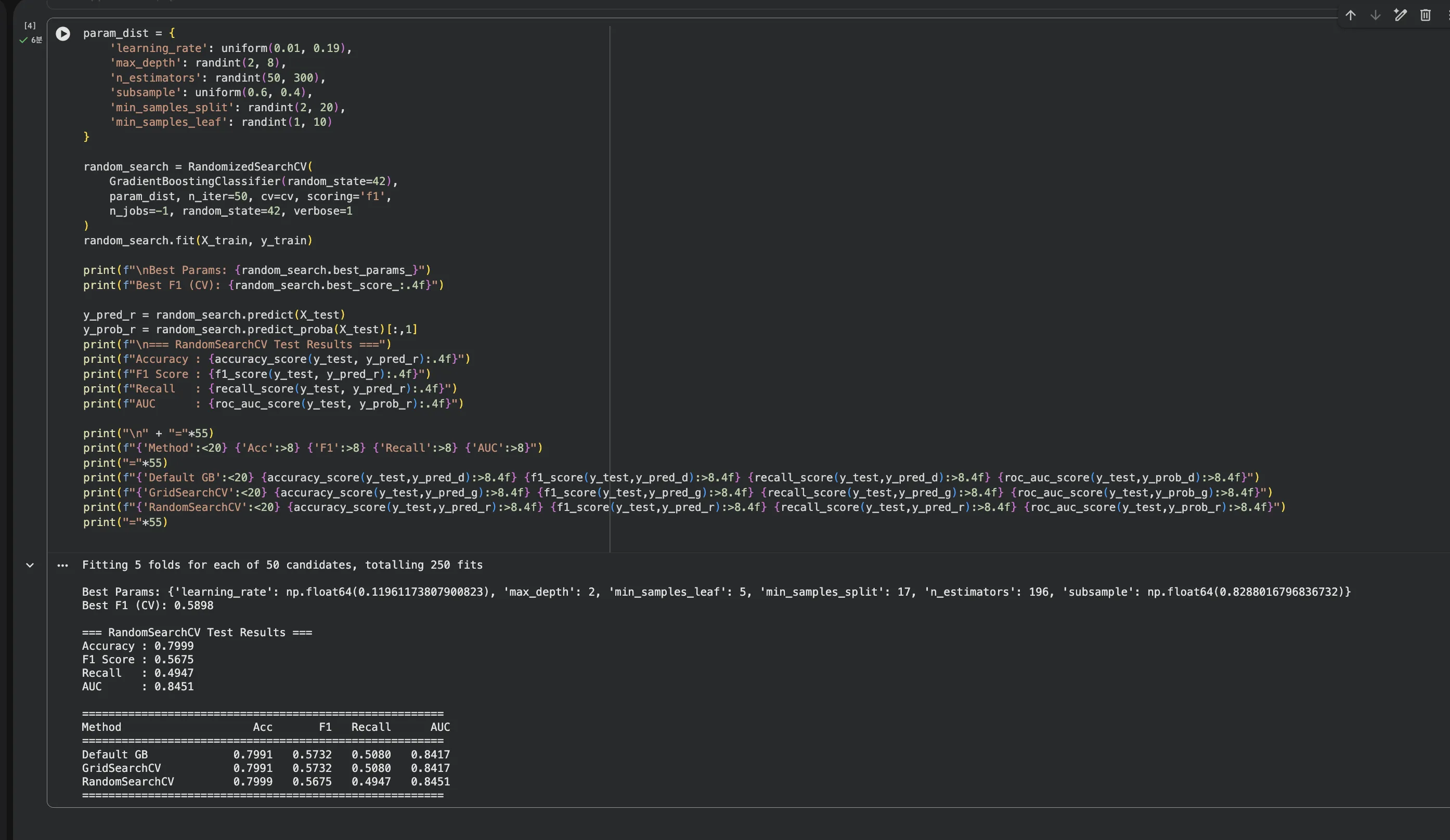
50회 × 5-Fold = 총 250번 학습이라 약 6분 걸립니다.
GridSearch(270번)보다 횟수는 적은데, RandomSearch는 탐색하는 하이퍼파라미터가 6개(min_samples_split, min_samples_leaf 추가)라 한 번 학습이 살짝 더 무겁습니다.
결과표를 보면 Default GB와 GridSearchCV가 거의 동일하고, RandomSearchCV가 AUC에서 소폭 앞서는 것을 확인할 수 있습니다.
결과 비교 — 튜닝이 얼마나 효과가 있었나
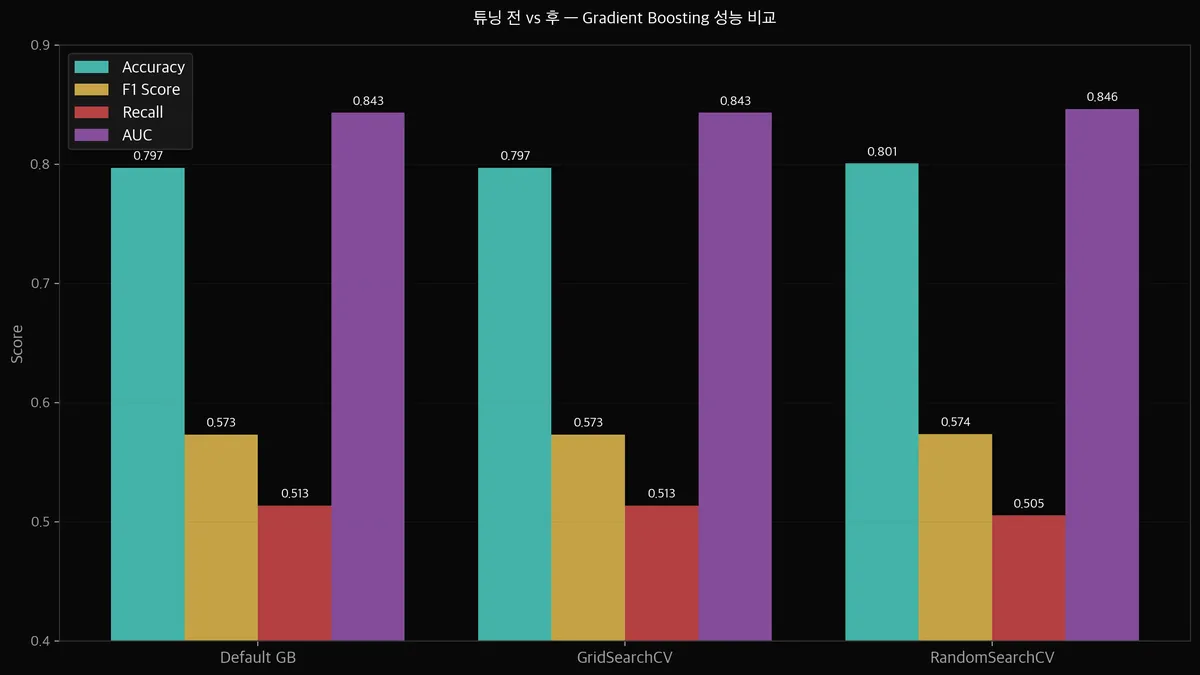
| 설정 | Accuracy | F1 | Recall | AUC |
|---|---|---|---|---|
| Default GB | 0.7970 | 0.5731 | 0.5134 | 0.8431 |
| GridSearchCV | 0.7970 | 0.5731 | 0.5134 | 0.8431 |
| RandomSearchCV | 0.8006 | 0.5736 | 0.5053 | 0.8462 |
솔직하게 말하면 — 개선폭이 크지 않습니다.
Accuracy +0.4%, AUC +0.3%. F1은 거의 동일합니다.
Recall은 오히려 살짝 떨어졌습니다 (51.3% → 50.5%).
이게 현실입니다. 튜닝이 항상 극적인 개선을 주지는 않습니다.
특히 기본 설정이 이미 잘 되어 있는 sklearn 모델에서는 더 그렇습니다.
ROC 커브로 보면 어떤 차이가 보이나요?
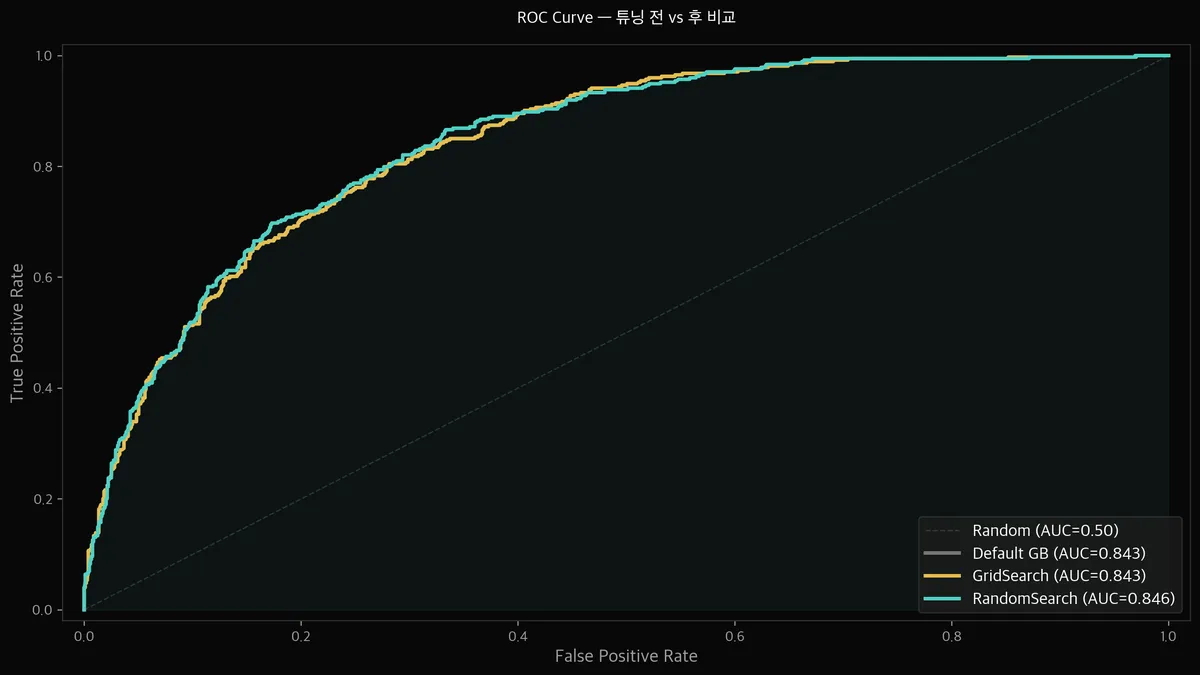
ROC 커브를 보면 세 모델이 거의 겹칩니다.
AUC가 0.843 → 0.846으로 소폭 개선되었지만, 눈으로는 차이를 구분하기 어렵습니다.
Jupyter 실습 — ROC Curve 시각화 (셀5)
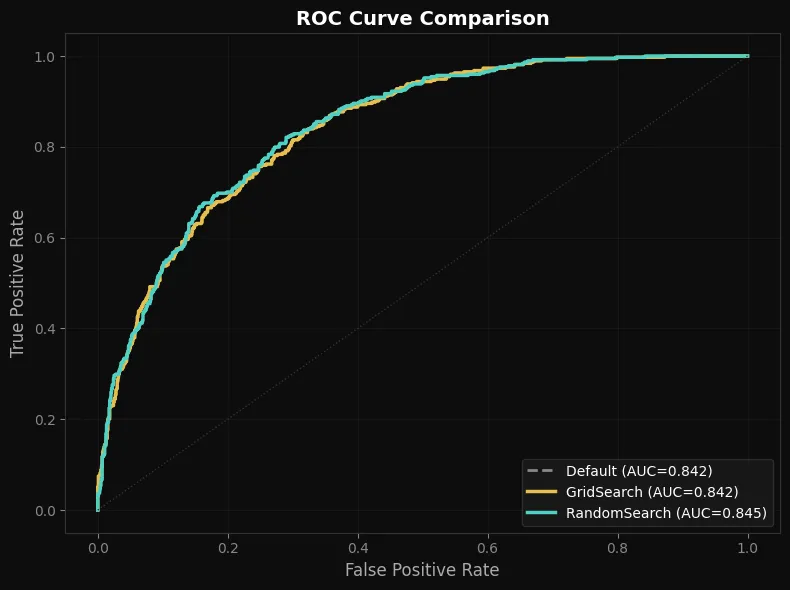
Default(회색 점선), GridSearch(골드), RandomSearch(민트)를 한 그래프에 겹쳐 그린 결과입니다. 세 곡선이 거의 겹치는 게 보이시죠? AUC 차이가 0.003 정도밖에 안 됩니다.
그래도 의미가 없는 건 아닙니다.
"이 설정이 최선인지 확인했다"는 것 자체가 중요합니다.
확인 없이 "아마 기본값이 괜찮겠지"라고 넘어가는 것과,
54가지(Grid) + 50가지(Random) = 104가지를 실험해보고 확인한 건 다릅니다.
GridSearch와 RandomSearch 중 언제 뭘 써야 하나요?
GridSearchCV
- 후보 값이 몇 개로 명확할 때
- 조합 수가 100개 이하일 때
- "빠짐없이 다 보고 싶다"면
RandomizedSearchCV
- 탐색 범위가 넓거나 연속값일 때
- 조합 수가 너무 많을 때 (1000개+)
- "시간 대비 효율적으로 찾고 싶다"면
실전에서는 RandomSearch로 넓게 탐색 → GridSearch로 좁혀서 정밀 탐색하는 2단계 전략을 많이 씁니다.
정리 — 이번 편에서 확인한 것
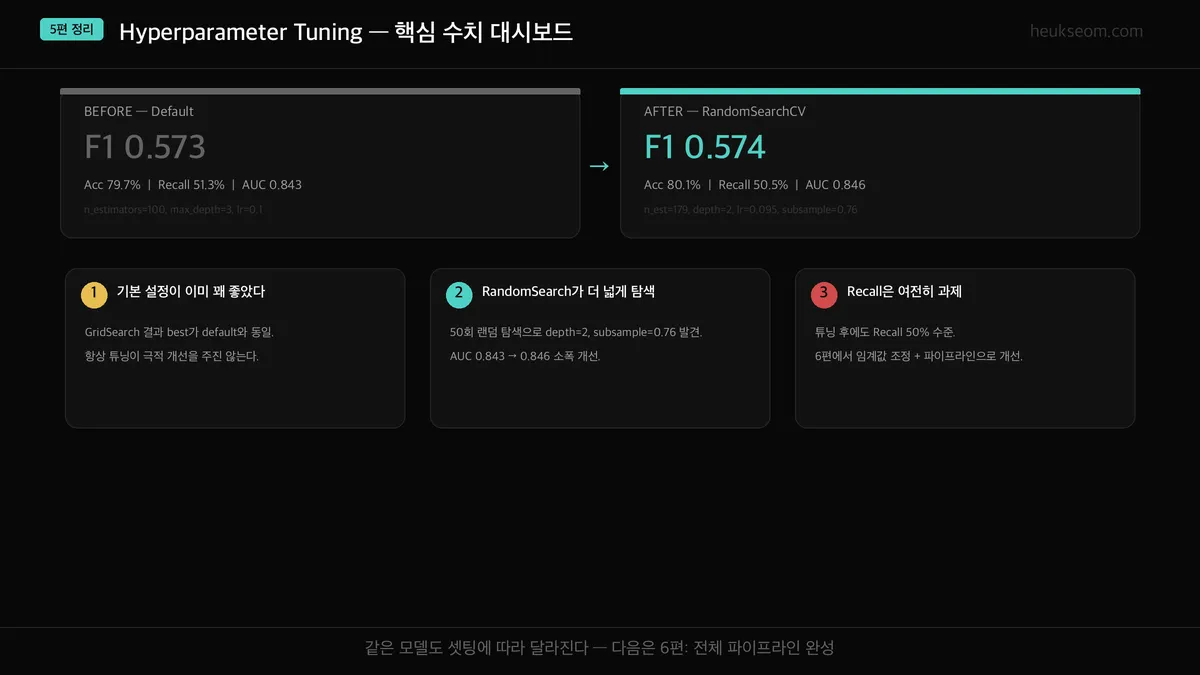
1. GridSearchCV best가 default와 동일했습니다. 기본 설정이 이미 꽤 합리적이었습니다.
2. RandomSearchCV가 depth=2, subsample=0.76이라는 새 조합을 찾아 AUC를 0.843→0.846으로 소폭 개선했습니다.
3. 튜닝만으로는 Recall 50% 한계를 넘기 어렵습니다. 데이터 자체의 한계입니다.
이번 편에서 가장 중요한 교훈은 — 튜닝은 마법이 아니라는 것입니다.
기본 설정이 좋은 모델에서는 개선폭이 작을 수 있습니다.
하지만 "확인했다"는 것 자체가 실전에서는 의미 있는 과정입니다.
다음 편(6편, 마지막)에서는 전체 파이프라인을 하나로 엮습니다.
1편 EDA부터 5편 튜닝까지, 지금까지 한 모든 과정을 sklearn Pipeline 하나로 묶어서
재현 가능한 워크플로우를 완성합니다.