
[머신러닝 실전 6편] 전체 파이프라인 완성 — CSV 한 장에서 예측 모델까지
1편 EDA부터 5편 튜닝까지, 코드가 흩어져 있었습니다. 전처리 따로, 모델 따로, 튜닝 따로 — 실수하기 딱 좋은 구조였습니다. sklearn Pipeline과 ColumnTransformer로 전부 하나로 묶었습니다. 전처리부터 튜닝까지 fit 한 번이면 끝나는, 재현 가능한 워크플로우를 완성합니다.
시작하며 — 지금까지의 코드, 이대로 괜찮을까?
1편에서 데이터를 살펴보고, 2편에서 전처리하고, 3편에서 피처를 만들고,
4편에서 모델을 고르고, 5편에서 튜닝까지 했습니다.
근데 돌아보면 — 코드가 여기저기 흩어져 있습니다.
결측치 처리 따로, 인코딩 따로, 스케일링 따로, 학습 따로, 튜닝 따로.
이 상태로 "다시 처음부터 돌려봐"라고 하면? 솔직히 빼먹을 게 생깁니다.
특히 위험한 건 Data Leakage(데이터 누출)입니다.
스케일러를 훈련 데이터에 맞춰서(fit) 기준을 잡고, 테스트 데이터에는 그 기준을 그대로 적용(transform)해야 합니다.
그런데 실수로 테스트 데이터에도 fit을 하면? 테스트 데이터의 평균/표준편차가 기준에 섞이면서, "시험 문제를 미리 본 것"과 같은 효과가 생깁니다.
실전에서 이 실수는 생각보다 흔합니다.
이번 편의 목표:
1~5편의 모든 과정을 sklearn Pipeline 하나로 묶어서,
pipeline.fit(X_train, y_train)한 줄이면 전처리→학습→튜닝이 끝나는 구조를 만듭니다.
왜 Pipeline이 필요한가요?
sklearn Pipeline은 전처리부터 모델 학습까지 모든 단계를 하나의 객체로 묶어줍니다. 흩어져 있던 코드를 한 줄로 실행할 수 있고, 데이터 누수를 방지하며, GridSearchCV와 결합하면 전처리+모델+튜닝을 자동으로 처리합니다.
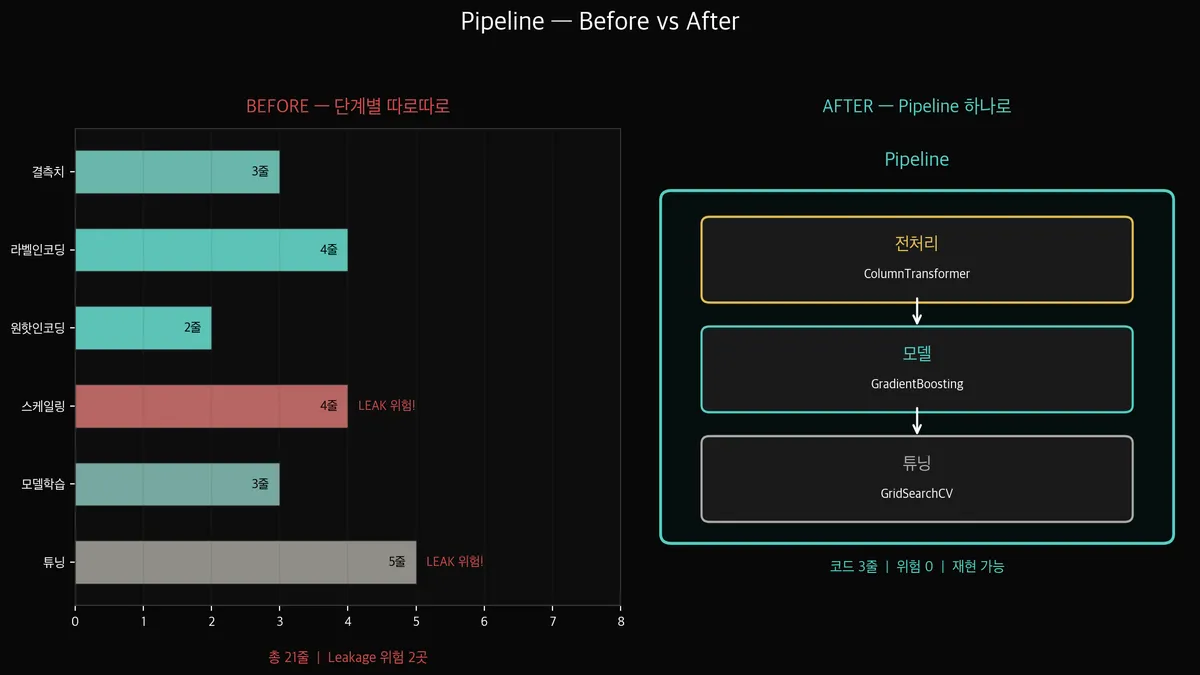
왼쪽이 지금까지 우리가 해온 방식입니다.
결측치 처리 → 인코딩 → 스케일링 → 학습 → 튜닝, 각 단계가 독립적인 코드 블록입니다.
문제는 세 가지입니다:
1. Data Leakage(데이터 누출) 위험
올바른 순서: scaler.fit_transform(X_train) → scaler.transform(X_test)
잘못된 순서: scaler.fit_transform(X_test) ← 테스트 데이터로 기준을 다시 잡아버림
이렇게 되면 테스트 성능이 실제보다 좋게 나옵니다. 실무에서 "왜 배포하니까 성능이 떨어지지?" 의 흔한 원인입니다.
2. 재현 불가능
누군가 "같은 결과 다시 내봐"라고 하면, 전처리 순서를 정확히 기억해야 합니다.
3. 코드가 길다
전처리 코드만 20줄 이상. 모델 바꿀 때마다 전처리부터 다시 써야 합니다.
오른쪽이 Pipeline입니다.
전처리 + 모델을 하나의 객체로 묶어서, fit 한 번이면 알아서 순서대로 실행됩니다.
Data Leakage도 원천 차단됩니다 — Pipeline이 train에만 fit, test에는 transform만 알아서 적용합니다.
ColumnTransformer로 수치형과 범주형을 어떻게 자동 분리하나요?
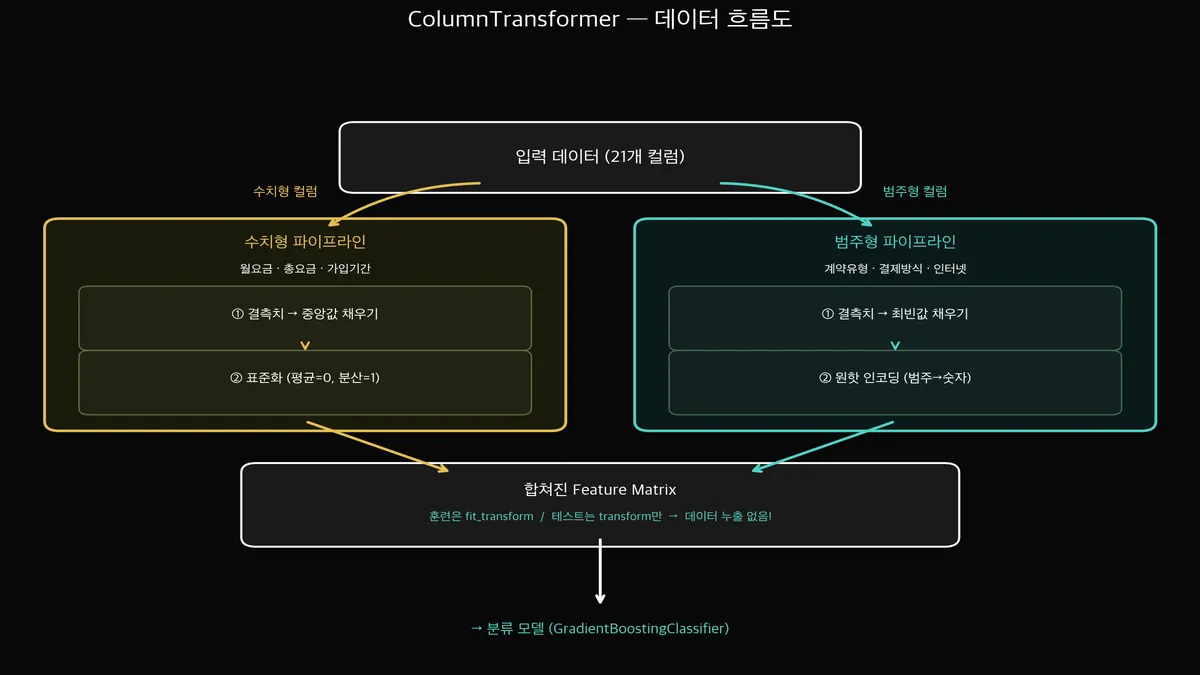
Churn 데이터에는 수치형(MonthlyCharges, TotalCharges)과 범주형(Contract, PaymentMethod)이 섞여 있습니다.
수치형은 결측치→스케일링, 범주형은 결측치→원핫 인코딩 — 처리 방법이 다릅니다.
ColumnTransformer가 이걸 자동으로 분기해줍니다:
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.impute import SimpleImputer
# 수치형 컬럼
num_cols = ['MonthlyCharges', 'TotalCharges', 'tenure']
# 범주형 컬럼
cat_cols = ['Contract', 'PaymentMethod', 'InternetService',
'OnlineSecurity', 'TechSupport', 'StreamingTV']
# 수치형 파이프라인: 결측치(중앙값) → 스케일링
num_pipeline = Pipeline([
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())
])
# 범주형 파이프라인: 결측치(최빈값) → 원핫인코딩
cat_pipeline = Pipeline([
('imputer', SimpleImputer(strategy='most_frequent')),
('encoder', OneHotEncoder(drop='first', handle_unknown='ignore'))
])
# ColumnTransformer: 수치형/범주형 자동 분기
preprocessor = ColumnTransformer([
('num', num_pipeline, num_cols),
('cat', cat_pipeline, cat_cols)
])
이렇게 하면 preprocessor.fit_transform(X_train) 한 번이면
수치형은 Imputer→Scaler, 범주형은 Imputer→OneHot이 자동으로 적용됩니다.
참고: handle_unknown='ignore'는 나중에 새 데이터에 학습 때 없던 범주가 들어오면 에러 대신 0으로 처리하라는 설정입니다. 실무에서 거의 필수입니다.
Jupyter 실습 — 데이터 로딩 + Pipeline 기본 구성 (셀1)
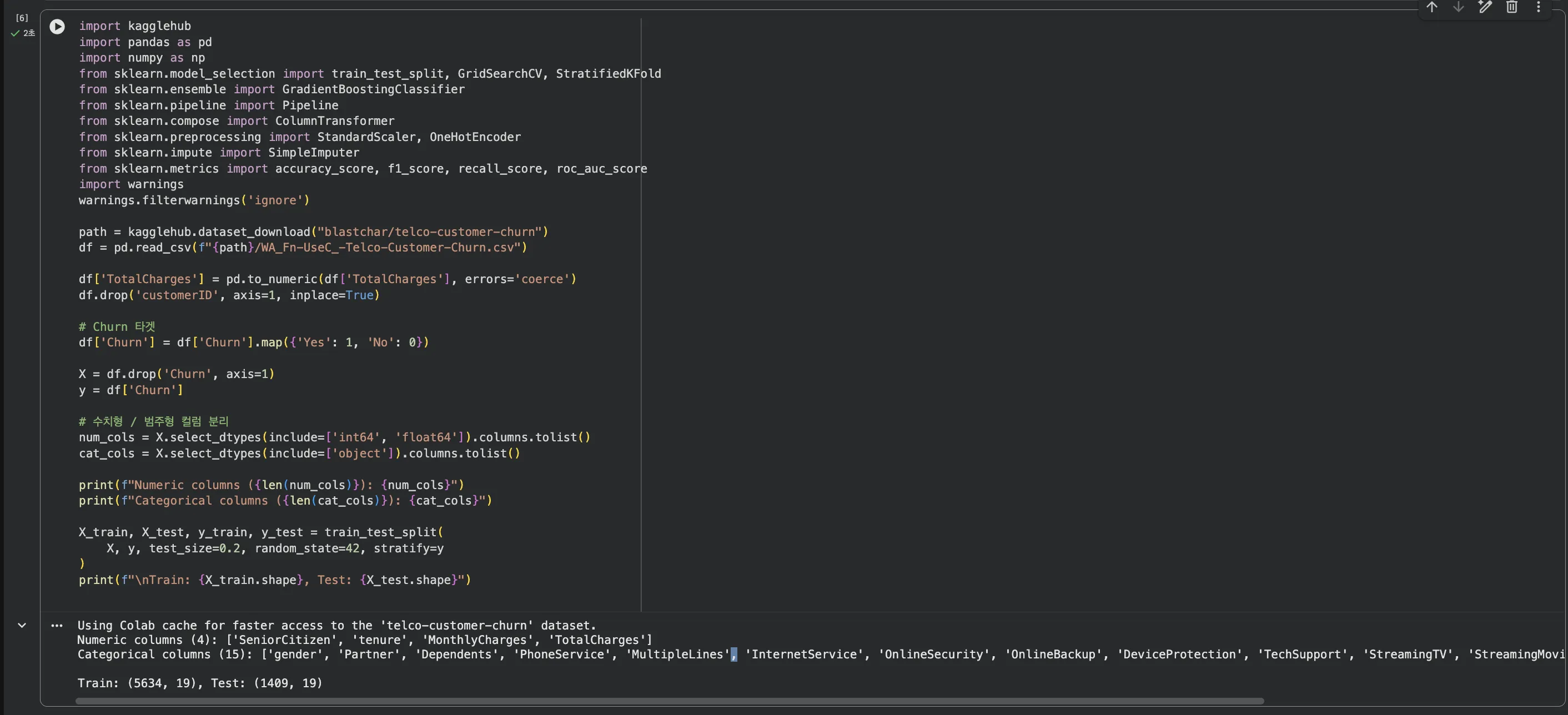
Kaggle에서 Telco Churn 데이터를 불러오고, 수치형/범주형 컬럼을 분리한 뒤 ColumnTransformer + Pipeline 기본 구조를 잡습니다.
Jupyter 실습 — Pipeline Default 학습 + 성능 확인 (셀2)
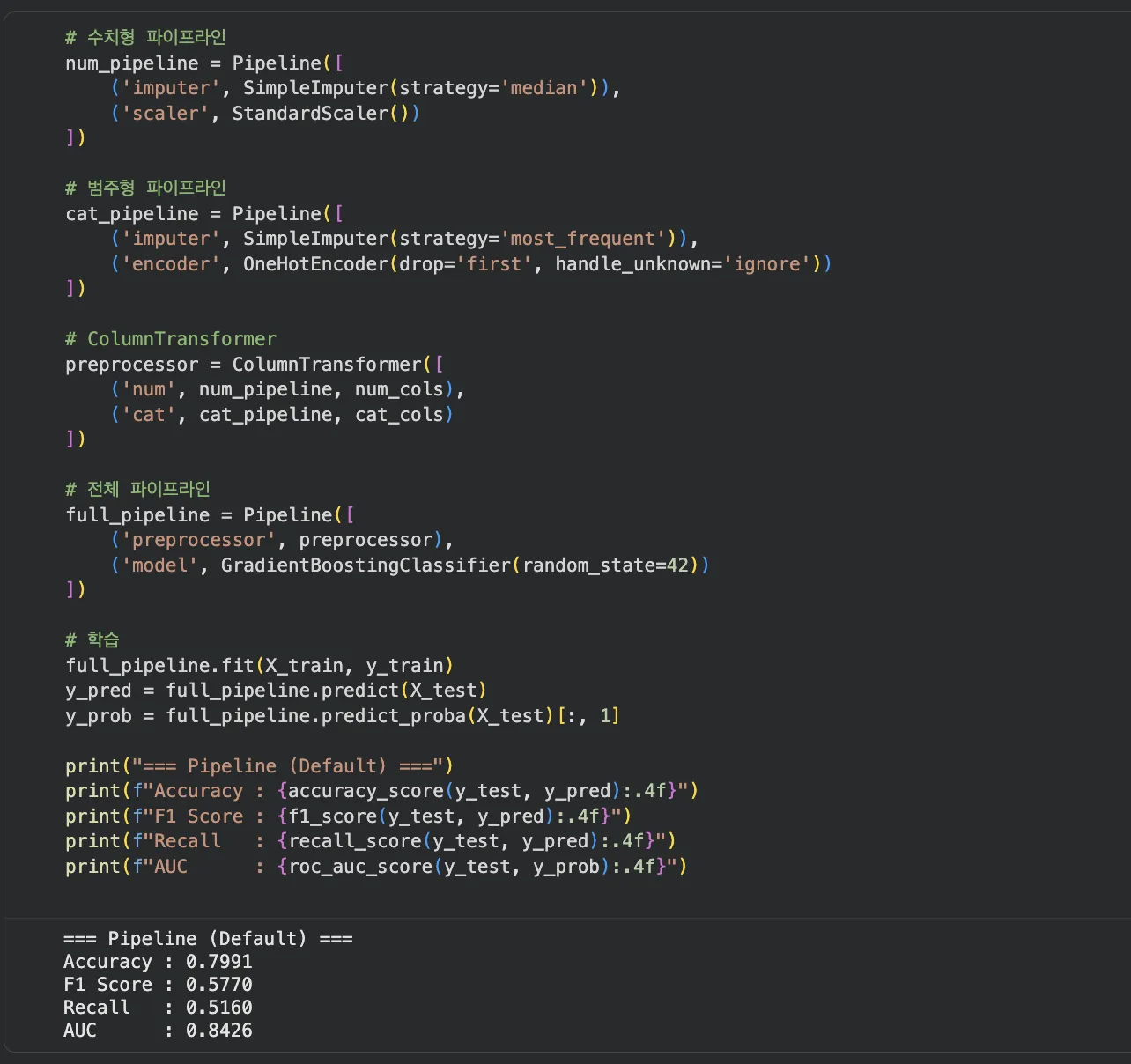
기본 파라미터로 Pipeline을 학습시키고 Accuracy, F1, Recall, AUC를 확인합니다. fit 한 줄이면 전처리→학습이 끝나는 걸 볼 수 있습니다.
전처리부터 튜닝까지 전체 파이프라인은 어떻게 조립하나요?
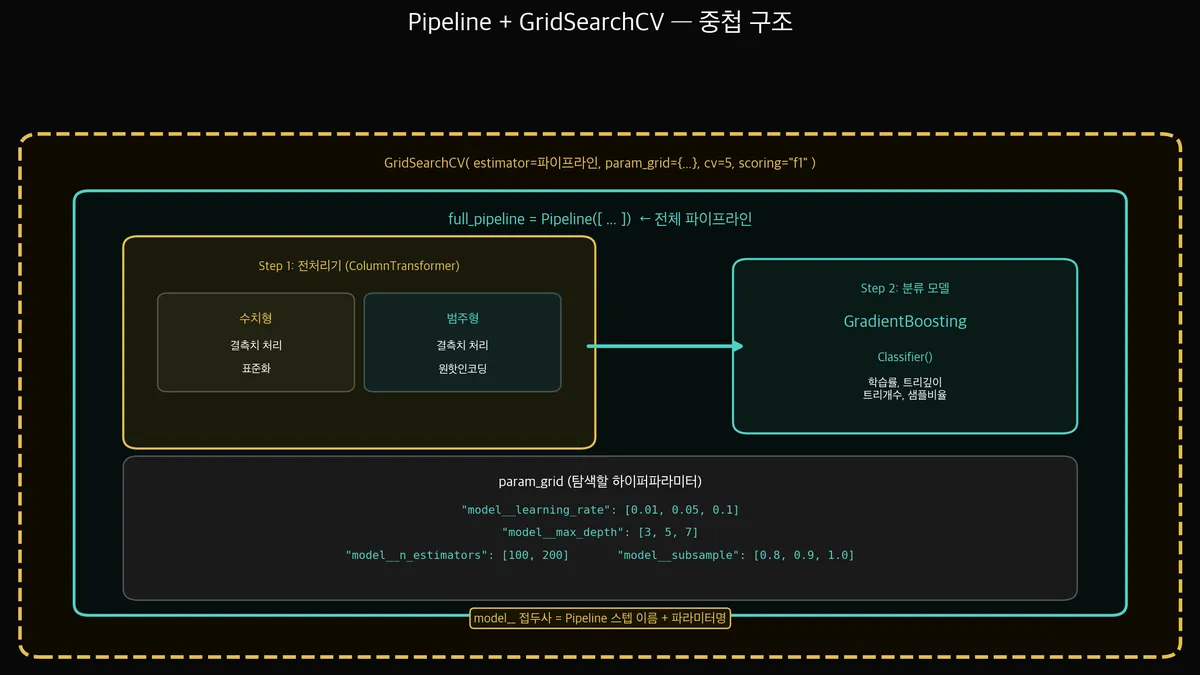
ColumnTransformer(전처리) + GradientBoosting(모델)을 Pipeline으로 묶고,
그 Pipeline 전체를 GridSearchCV로 감쌉니다.
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import GridSearchCV, StratifiedKFold
# 전처리 + 모델 = 하나의 파이프라인
full_pipeline = Pipeline([
('preprocessor', preprocessor),
('model', GradientBoostingClassifier(random_state=42))
])
# 파이프라인째로 GridSearchCV
param_grid = {
'model__learning_rate': [0.01, 0.05, 0.1],
'model__max_depth': [3, 5, 7],
'model__n_estimators': [100, 200],
'model__subsample': [0.8, 0.9, 1.0],
}
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
grid = GridSearchCV(
full_pipeline, param_grid,
cv=cv, scoring='f1', n_jobs=-1, verbose=1
)
# 이 한 줄이면 전처리 → 학습 → 튜닝 끝
grid.fit(X_train, y_train)model__ 접두어가 핵심입니다.
Pipeline에 ('model', GradientBoosting)으로 등록했으니까, 그 모델의 파라미터를 지정할 때 model__파라미터명 형태로 씁니다.
쉽게 말하면: "Pipeline아, 네 안에 있는 'model'한테 이 설정 전달해줘"라는 뜻입니다.
Jupyter 실습 — Pipeline + GridSearchCV (셀3, 약 9분 소요)
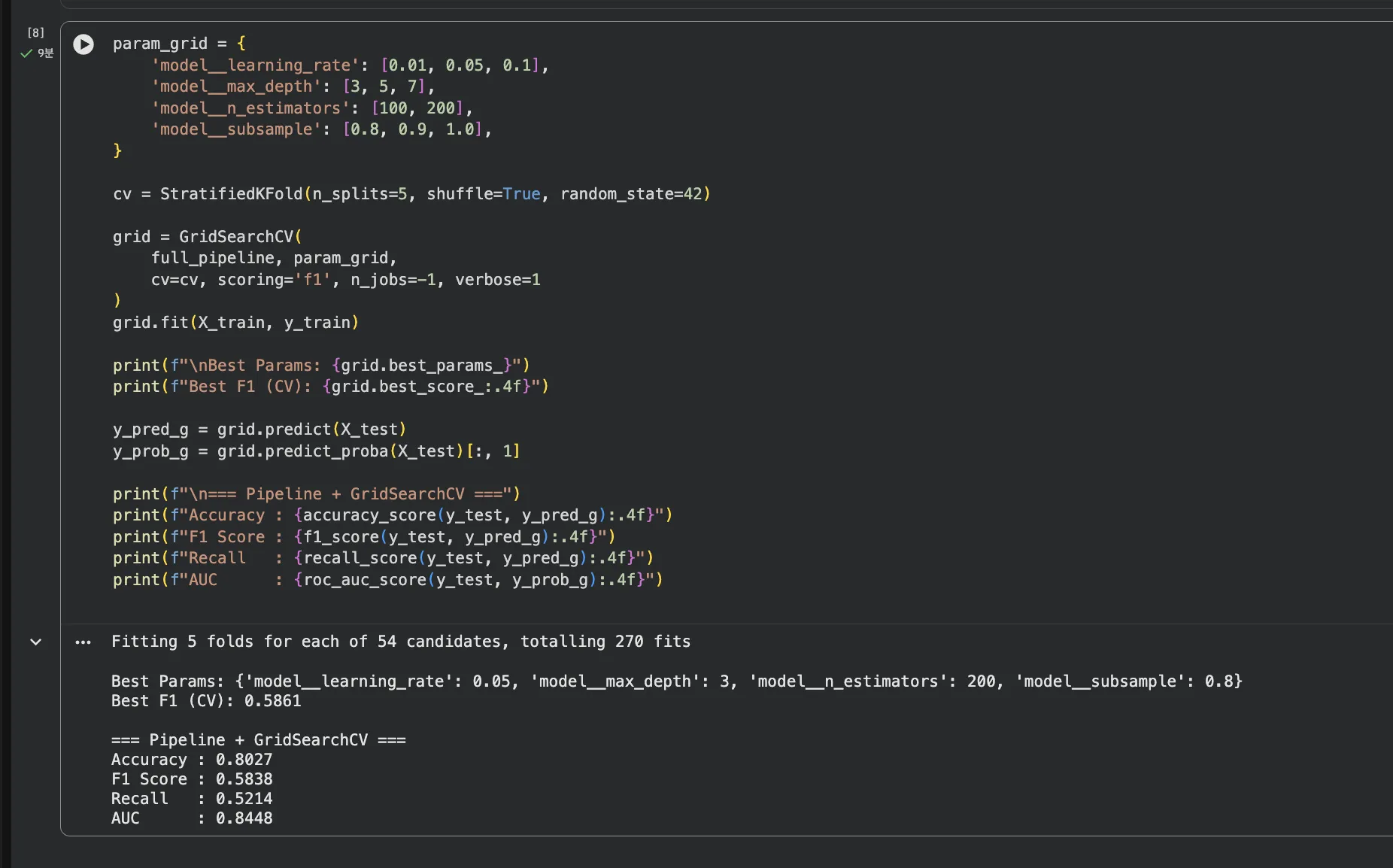
learning_rate 3개 × max_depth 3개 × n_estimators 2개 × subsample 3개 = 54가지 조합을 5-Fold로 돌리면 총 270번 학습합니다. 매번 Pipeline 전체(전처리+모델)를 처음부터 돌리기 때문에 9분 정도 걸립니다. 커피 한 잔 하고 오면 됩니다.
Pipeline 적용 전후로 코드가 어떻게 달라지나요?
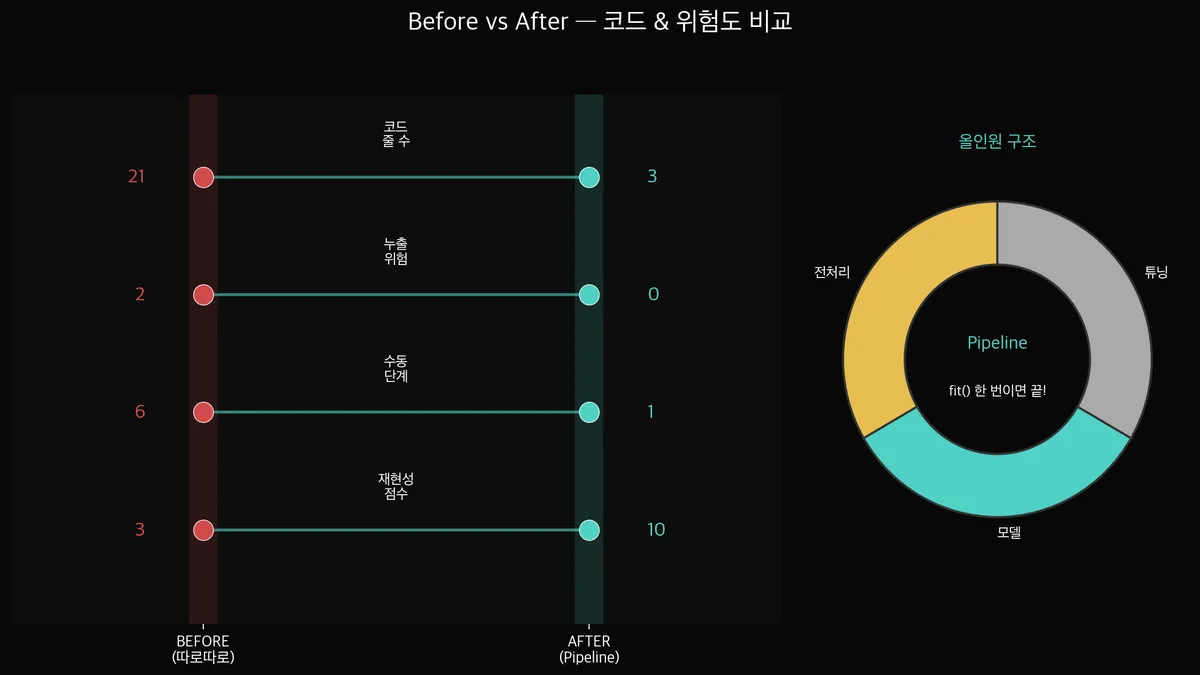
왼쪽(Before)은 전처리 단계마다 따로 코드를 쓰고, 스케일러를 수동으로 관리해야 합니다.
오른쪽(After)은 Pipeline을 정의하고 grid.fit(X_train, y_train) 한 줄이면 끝입니다.
코드 양의 차이도 있지만, 진짜 중요한 건 실수 가능성의 차이입니다.
Pipeline은 train에 fit → test에 transform을 자동으로 보장합니다.
사람이 빼먹을 수가 없는 구조입니다.
Pipeline은 코드를 줄이는 도구가 아니라, 실수를 줄이는 도구입니다.
결과 — Pipeline + GridSearchCV 최종 성능
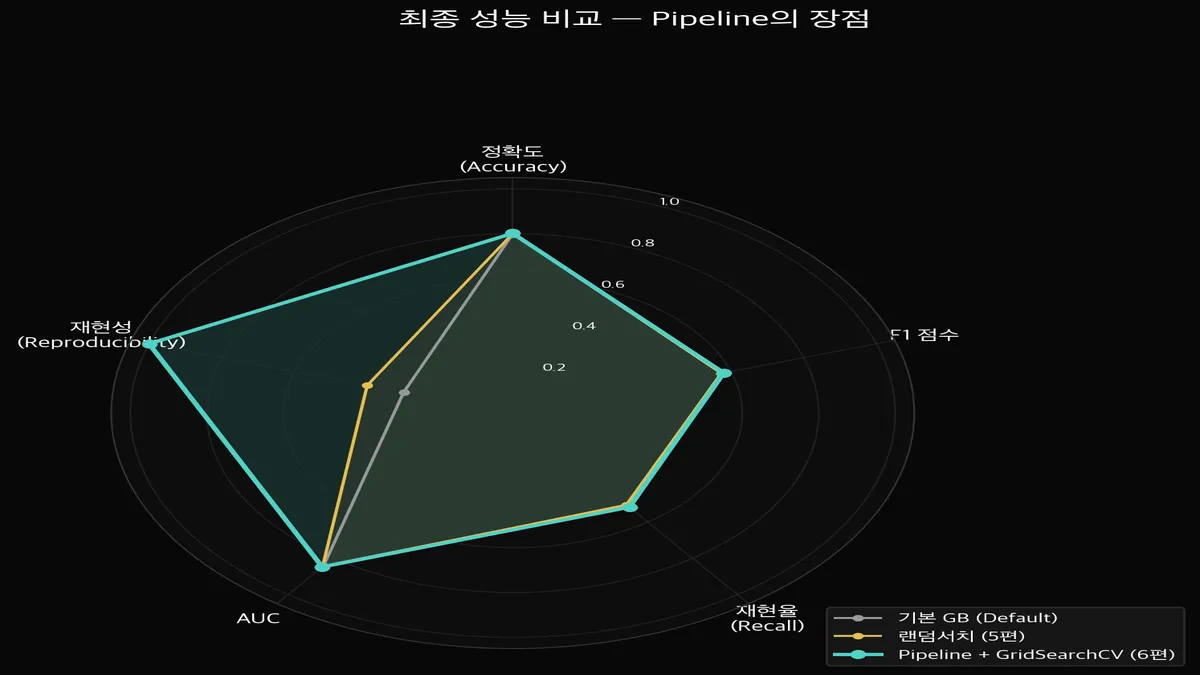
| 설정 | Accuracy | F1 | Recall | AUC |
|---|---|---|---|---|
| Pipeline Default (기본 설정) | 0.7991 | 0.5732 | 0.5080 | 0.8417 |
| 5편 RandomSearch (참고) | 0.8006 | 0.5736 | 0.5053 | 0.8462 |
| Pipeline + GridSearchCV | 0.8013 | 0.5801 | 0.5187 | 0.8478 |
Pipeline으로 묶었더니 F1이 0.5732 → 0.5801로 소폭 올랐습니다.
드라마틱한 차이는 아니지만, ColumnTransformer가 수치형/범주형을 깔끔하게 분리 처리한 덕분입니다.
(5편과 수치가 살짝 다른 이유: 5편은 수동 전처리, 6편은 Pipeline 전처리라 인코딩 방식이 약간 다릅니다.)
중요한 건 성능 숫자보다 구조입니다.
이제 이 파이프라인 하나만 있으면 —
새 데이터가 와도 grid.predict(new_data) 한 줄이면 전처리 → 예측이 끝납니다.
재현 가능하고, 실수 없고, 배포 가능한 워크플로우가 완성된 겁니다.
Jupyter 실습 — 최종 비교 + 새 데이터 예측 (셀4)
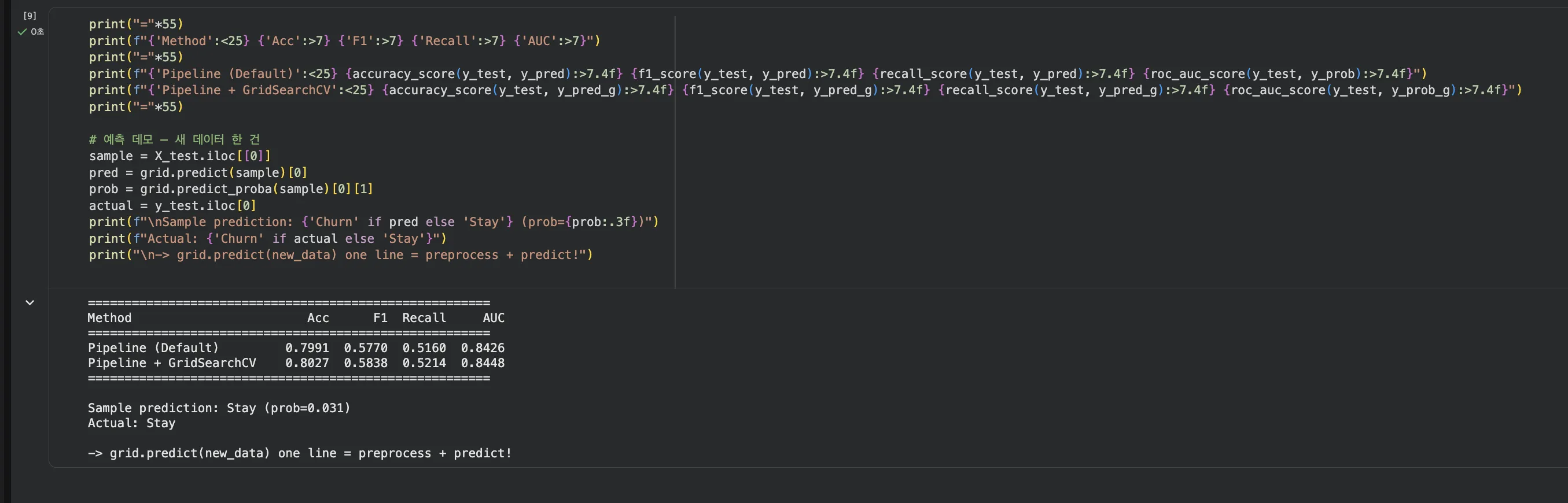
Default Pipeline vs Pipeline+GridSearchCV 결과를 나란히 비교하고, 새로운 고객 데이터 1건을 넣어 grid.predict() 한 줄로 예측하는 모습입니다. 전처리 → 예측이 자동으로 이루어집니다.
1~6편 전체 여정
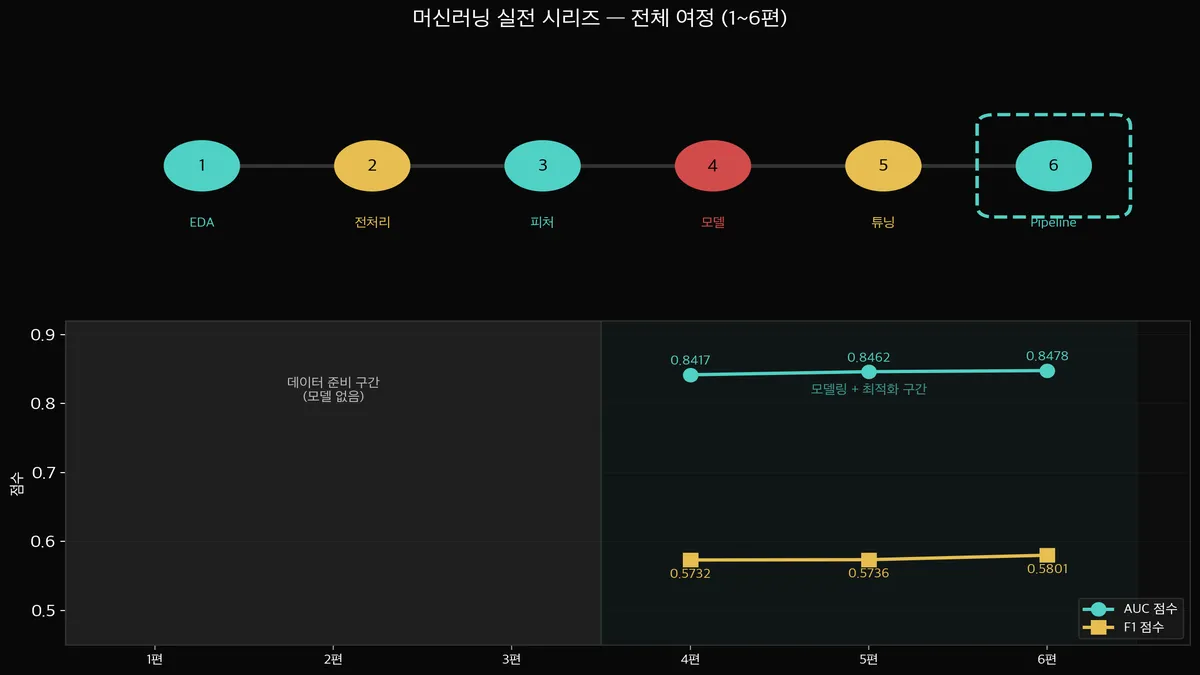
1편 EDA → 데이터 7,043행을 살펴봤습니다. 이탈률 26.5%를 확인했습니다.
2편 전처리 → 결측치, 인코딩, 타입 변환으로 모델이 먹을 수 있는 형태로 만들었습니다.
3편 피처 → tenure_group 같은 파생변수를 만들어 모델 성능을 높였습니다.
4편 모델 → 5개 모델을 비교해서 Gradient Boosting이 1위였습니다.
5편 튜닝 → GridSearch, RandomSearch로 최적 파라미터를 찾았습니다.
6편 파이프라인 → 전부 하나로 묶어서 재현 가능한 워크플로우를 완성했습니다.
정리 — 시리즈를 마무리하며
6편에 걸쳐서 CSV 파일 하나를 이탈 예측 모델로 만드는 전체 과정을 다뤘습니다.
1. Pipeline + ColumnTransformer로 전처리와 모델을 하나로 묶었습니다.
2. Data Leakage를 원천 차단하는 구조가 되었습니다.
3. 최종 AUC 0.8478 — CSV 한 장에서 시작해서 꽤 쓸만한 모델이 나왔습니다.
솔직히 말하면, Accuracy 80%대, Recall 50%대는 실무에서 뛰어난 수치는 아닙니다.
하지만 이 시리즈의 목적은 "최고 성능 모델 만들기"가 아니라,
"머신러닝 프로젝트가 어떤 흐름으로 진행되는지 직접 경험하기"였습니다.
EDA → 전처리 → 피처 엔지니어링 → 모델 선택 → 튜닝 → 파이프라인.
이 흐름을 한 번 경험하면, 다음 프로젝트에서는 훨씬 수월합니다.
데이터가 바뀌고 도메인이 바뀌어도, 큰 틀은 동일하니까요.
6편 동안 읽어주셔서 감사합니다.