
[벡터DB·지식그래프 RAG 4편] 벡터 × 그래프 — 하이브리드 검색
1편의 벡터 검색과 3편의 그래프 탐색을 한 검색으로 합칩니다. neo4j-graphrag의 VectorRetriever(진입점만)와 VectorCypherRetriever(진입 후 그래프 확장)를 실제로 돌려 비교하고, retrieval_query로 진입 노드에서 관계를 따라 관련 맥락을 모읍니다. 벡터로 진입하고 그래프로 넓히는 GraphRAG의 검색 엔진을 완성합니다. 진입+이웃 ego 그래프 실캡처 포함. 지식그래프 RAG 5부작 4편.
재료는 다 모였습니다 — 이제 합칠 차례
1편에서 벡터로 '비슷한 것'을 찾았고, 3편에서 그래프로 '연결된 것'을 따라갔습니다.
근데 둘을 따로 썼죠. 이번 4편에서는 이 둘을 한 검색으로 합칩니다.
방식은 간단해요. 벡터로 진입점(가장 비슷한 문서)을 찾고, 거기서 그래프로 주변 맥락을 넓힙니다.
이게 GraphRAG의 검색 엔진이고, 5편에서 여기에 LLM만 붙이면 끝입니다.
4편에서 하는 것: 왜 하이브리드인가 → neo4j-graphrag의 두 리트리버(VectorRetriever / VectorCypherRetriever) → 벡터 진입 + 그래프 확장을 실제로 돌려서 컨텍스트가 얼마나 풍부해지는지 비교. 2·3편의 Neo4j(벡터+관계)를 그대로 씁니다.

벡터와 그래프를 한 검색으로 잇는 하이브리드 — 두 쪽을 잇는 다리처럼. (사진: Wikimedia Commons, Public Domain)
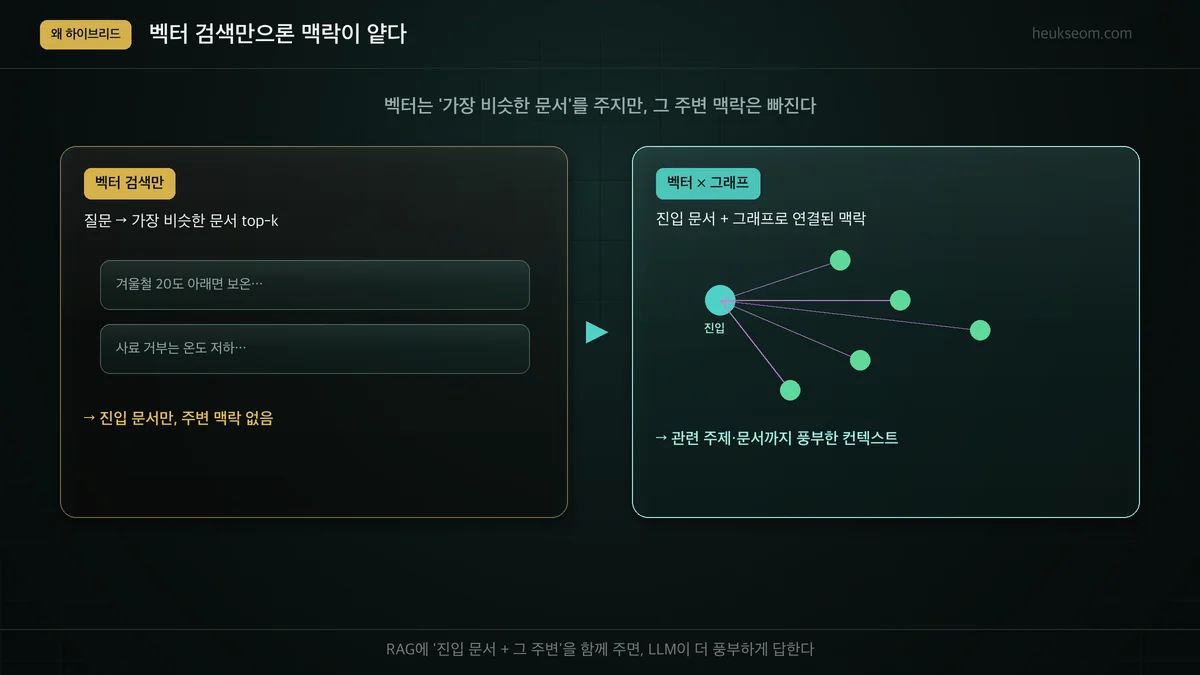
벡터 검색만으론 뭐가 아쉬운가요?
벡터 검색은 질문과 가장 비슷한 문서 몇 개를 주지만, 그 문서 주변의 관련 맥락은 빠집니다. RAG에서 LLM에게 진입 문서 본문만 주면 답이 얕아질 수 있습니다. 하이브리드는 진입 문서에 더해, 그래프로 연결된 관련 주제·문서까지 함께 모아 더 풍부한 컨텍스트를 만듭니다.
RAG의 답 품질은 결국 'LLM에게 어떤 맥락을 주느냐'로 갈립니다.
진입 문서 하나만 주는 것과, 그 문서 + 관련 맥락을 함께 주는 건 차이가 크죠.
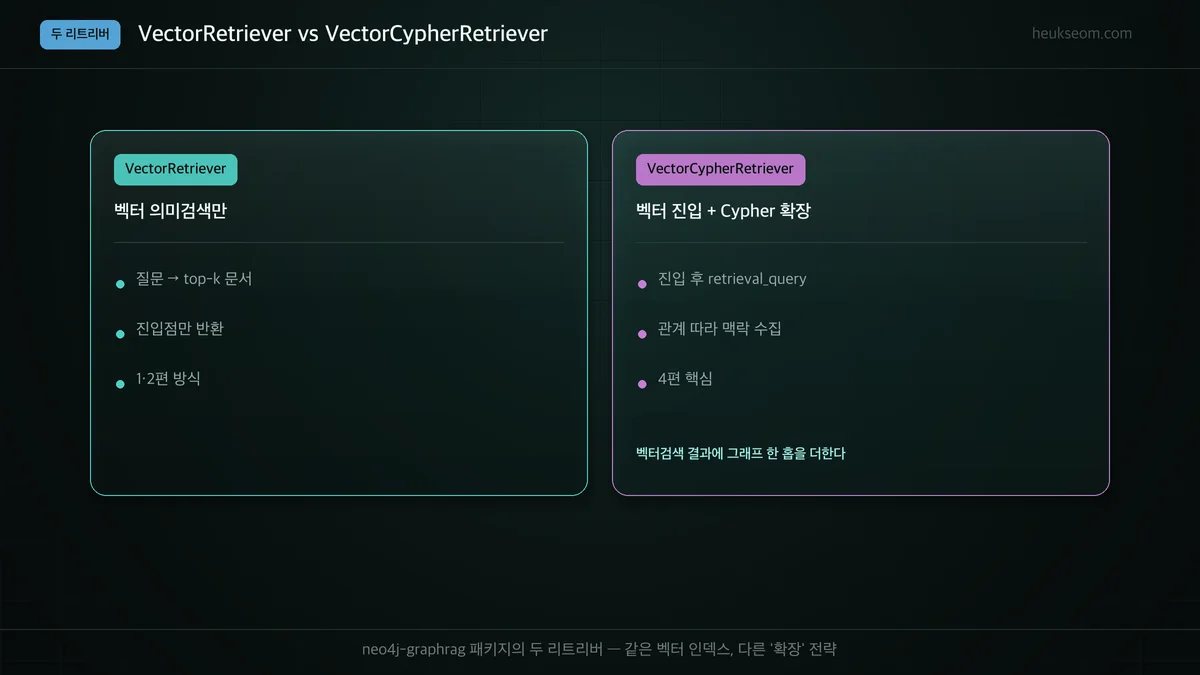
리트리버가 두 종류라고요?
neo4j-graphrag 패키지는 두 리트리버를 제공합니다. VectorRetriever는 벡터 인덱스로 가장 비슷한 노드(진입점)만 반환합니다. VectorCypherRetriever는 진입점을 찾은 뒤, 우리가 준 retrieval_query(Cypher)를 진입 노드에서 실행해 관계를 따라 주변 맥락까지 모아 반환합니다. 같은 벡터 인덱스를 쓰지만 '확장' 전략이 다릅니다.
실습 — 설치 + VectorRetriever (셀 1)
!pip install "neo4j-graphrag[sentence-transformers]" -q
from neo4j import GraphDatabase
from neo4j_graphrag.retrievers import VectorRetriever
from neo4j_graphrag.embeddings.sentence_transformers import SentenceTransformerEmbeddings
driver = GraphDatabase.driver("bolt://localhost:7687", auth=("neo4j", "***"))
embedder = SentenceTransformerEmbeddings(model="jhgan/ko-sroberta-multitask")
vr = VectorRetriever(driver, index_name="doc_embedding",
embedder=embedder, return_properties=["text"])
for item in vr.search(query_text="겨울에 너무 추울 때 어떻게 관리하죠?", top_k=2).items:
print(item.content)embedder는 2편과 같은 한국어 모델. VectorRetriever는 벡터 인덱스(doc_embedding)에서 진입 문서만 돌려줍니다.
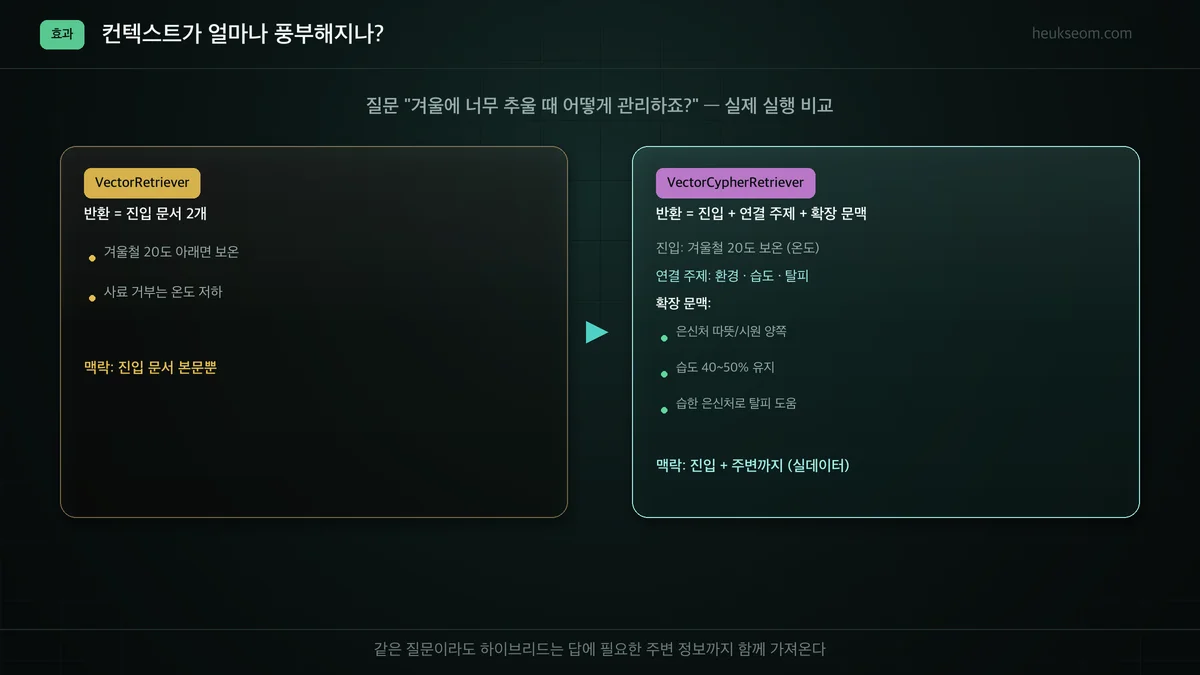
벡터로 진입해서 그래프로 넓히면?
VectorCypherRetriever에 retrieval_query를 주면, 벡터로 찾은 진입 노드(node)에서 시작하는 Cypher가 실행됩니다. 진입 노드의 ABOUT 주제와 SIMILAR_TO 이웃을 따라가며 관련 맥락을 모아 한 번에 반환합니다. 진입은 벡터가, 확장은 그래프가 담당하는 구조입니다.

같은 질문을 두 방식으로 돌리면 반환되는 컨텍스트가 이렇게 달라집니다.
'온도' 진입 문서들을 하나씩 풀어보면 더 구체적입니다. 같은 검색을 Neo4j Browser의 Table 뷰로 돌려, 진입 문서마다 어떤 주제·문맥이 딸려오는지 그대로 펼쳤습니다.

컬럼이 곧 GraphRAG가 모으는 재료입니다. 진입문서는 벡터로 잡은 시작점, 연결주제·확장문맥은 거기서 그래프로 번져 모은 것이죠. 진입 문서마다 딸려오는 주제가 다른 게 보입니다(맨 아래 "3 records ... 169 ms"가 실제 실행 흔적).
실습 — VectorCypherRetriever (셀 2)
from neo4j_graphrag.retrievers import VectorCypherRetriever
# 진입 노드(node)에서 그래프로 확장. 강하게 유사한(score>0.7) 이웃만.
retrieval_query = """
MATCH (node)-[:ABOUT]->(seedTopic:Topic)
OPTIONAL MATCH (node)-[s:SIMILAR_TO]-(nb:Doc)-[:ABOUT]->(nbTopic:Topic)
WHERE s.score > 0.7
RETURN node.text AS entry, seedTopic.name AS topic,
collect(DISTINCT nbTopic.name) AS linked_topics,
collect(DISTINCT nb.text)[0..3] AS expanded
"""
vcr = VectorCypherRetriever(driver, index_name="doc_embedding",
retrieval_query=retrieval_query, embedder=embedder)
print(vcr.search(query_text="겨울에 너무 추울 때 어떻게 관리하죠?", top_k=1).items[0].content)[A]는 진입 문서 2개뿐, [B]는 같은 진입 문서에 연결된 주제·문맥까지. LLM에 줄 재료가 확 풍부해졌죠.
사실 처음엔 SIMILAR_TO를 전부 확장했더니, 연결된 주제가 거의 모든 주제로 딸려 나오더라고요. ㅎㅎ
그래서 WHERE s.score > 0.7로 강하게 유사한 이웃만 남겼더니, 그제서야 '관련 맥락'다워졌습니다.
진입 노드에서 실제로 어떤 이웃이 딸려오는지 Neo4j Browser로 봤습니다.
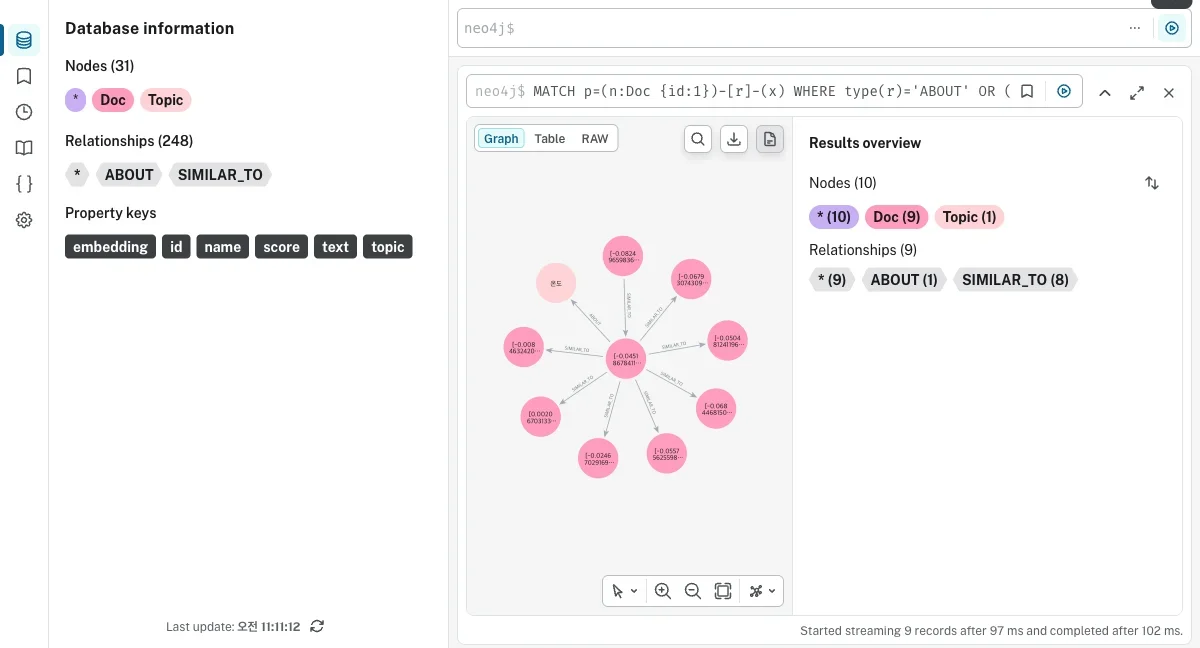
가운데가 벡터로 찾은 진입 문서고, 거기서 뻗어나간 게 그래프로 확장된 이웃들입니다.
벡터가 '어디서 시작할지'를, 그래프가 '거기서 무엇을 더 가져올지'를 정한 거예요.
정리
4편 핵심만 정리합니다.
- 벡터 검색만으론 진입 문서 본문만 얻습니다. 하이브리드는 주변 맥락까지 모읍니다.
- neo4j-graphrag의 VectorRetriever는 진입점만, VectorCypherRetriever는 진입 후 그래프 확장까지 합니다.
- retrieval_query에 진입 노드(node)에서 시작하는 Cypher를 주면 관계를 따라 맥락이 수집됩니다.
- SIMILAR_TO를 score로 거르면 '관련 있는' 맥락만 깔끔하게 확장됩니다.
- 벡터(진입) + 그래프(확장) = GraphRAG의 검색 엔진. 이제 LLM만 붙이면 됩니다.
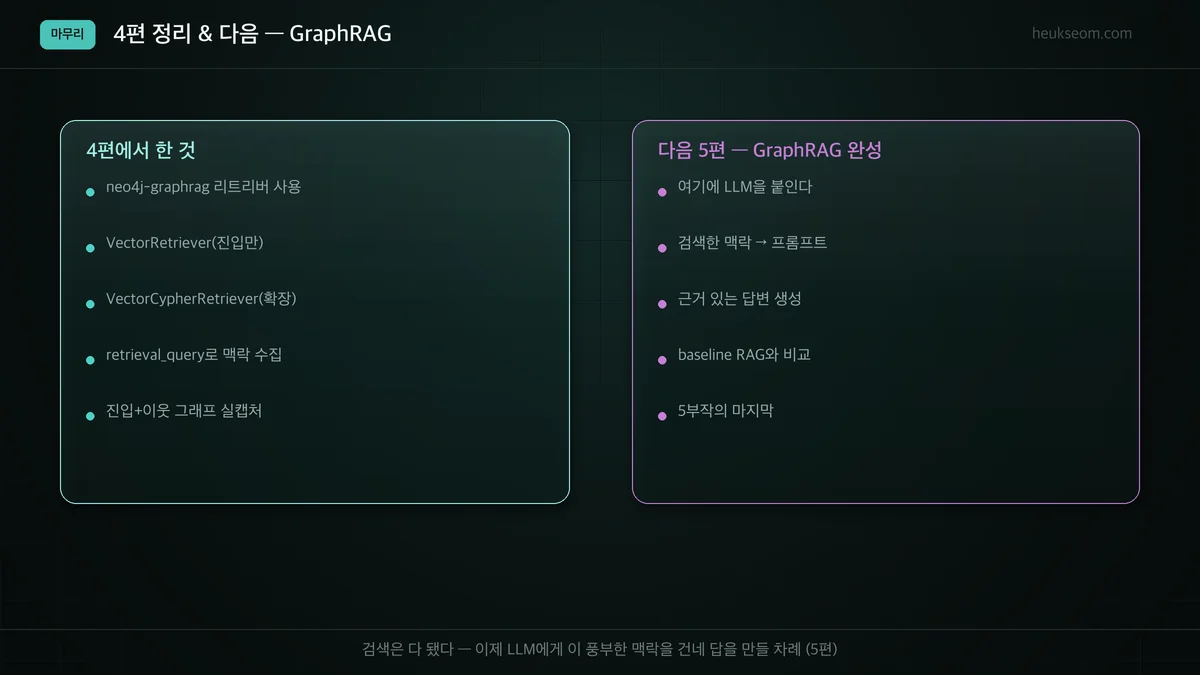
검색은 여기서 완성됐습니다. 벡터로 시작해 그래프로 넓히는, 꽤 강력한 엔진이 손에 들어왔어요.
마지막 5편에서는 이 풍부한 맥락을 LLM에게 건네 근거 있는 답변을 만들고, 평범한 RAG와 비교해봅니다. GraphRAG의 완성입니다.