
[소셜 미디어 트렌드 2편] 리뷰 15만 건, 문장 길이부터 워드클라우드까지 텍스트 EDA
1편에서 전처리한 NSMC 데이터를 다시 꺼냅니다. 문장 길이 분포, 긍정/부정 워드클라우드, 단어 빈도 Top-20, 길이별 감성 비율까지 — 모델에 넣기 전에 텍스트 데이터를 눈으로 확인하는 과정입니다.
시작하며 — 왜 텍스트 EDA가 필요한가
1편에서 감성 분석 모델을 만들었습니다. 정확도 82.8%.
그런데 한 가지 궁금한 게 있습니다. 이 데이터가 실제로 어떻게 생겼는지 확인해본 적이 없거든요.
리뷰 평균 길이가 얼마인지, 긍정 리뷰와 부정 리뷰가 길이 차이가 있는지,
어떤 단어가 가장 많이 나오는지 — 이런 걸 모르고 모델을 돌린 겁니다.
숫자 데이터에서 히스토그램, 산점도 그려보는 것처럼, 텍스트에도 EDA가 필요합니다.
이번 2편에서는 1편에서 전처리한 NSMC 데이터를 다시 꺼내서,
문장 길이 분석, 워드클라우드, 단어 빈도, 길이별 감성 비율까지 확인합니다.
데이터 준비 — 1편 전처리를 어떻게 재활용할까요?
1편에서 만든 전처리 함수(정규화, 형태소 분석, 불용어 제거)를 그대로 다시 사용합니다. 새 노트북에서 시작한다면 동일한 코드를 먼저 돌리면 되고, 1편 노트북을 이어서 쓴다면 이 단계는 건너뛰어도 됩니다. 전처리된 clean 컬럼이 이번 EDA의 출발점이에요.
1편을 이미 돌린 노트북이면 이 부분은 넘어가도 됩니다.
새 노트북에서 시작한다면, 1편과 동일한 전처리를 먼저 돌려야 하죠.
import pandas as pd
import numpy as np
import re
from konlpy.tag import Okt
okt = Okt()
# 데이터 로드
train = pd.read_csv('ratings_train.txt', sep='\t')
test = pd.read_csv('ratings_test.txt', sep='\t')
train = train.dropna(subset=['document'])
test = test.dropna(subset=['document'])
# 전처리 함수 (1편과 동일)
def clean_text(text):
text = re.sub(r'[^가-힣a-zA-Z\s]', '', str(text))
return text.strip()
stopwords = ['이', '가', '을', '를', '은', '는', '의', '에', '에서',
'로', '으로', '와', '과', '도', '만', '까지', '부터',
'그', '저', '것', '수', '등', '들', '및', '더']
def tokenize(text):
text = clean_text(text)
tokens = okt.morphs(text, stem=True)
tokens = [t for t in tokens if t not in stopwords and len(t) > 1]
return ' '.join(tokens)
# 전체 전처리 적용 (약 5~10분)
from tqdm import tqdm
tqdm.pandas()
train['clean'] = train['document'].progress_apply(tokenize)Jupyter 실행 결과 보기 — 전처리 진행
문장 길이 — 기본 통계부터 어떻게 확인할까요?

먼저 각 리뷰의 글자 수를 계산합니다.
평균이 얼마인지, 가장 긴 리뷰가 몇 글자인지, 긍정과 부정에 차이가 있는지 확인합니다.
# 문장 길이 계산
train['doc_len'] = train['document'].str.len()
print(f"평균: {train['doc_len'].mean():.1f}자")
print(f"중앙값: {train['doc_len'].median():.0f}자")
print(f"최대: {train['doc_len'].max()}자")
print(f"최소: {train['doc_len'].min()}자")
print(f"표준편차: {train['doc_len'].std():.1f}자")
# 긍정/부정별 평균
pos = train[train['label'] == 1]
neg = train[train['label'] == 0]
print(f"긍정 리뷰 평균 길이: {pos['doc_len'].mean():.1f}자")
print(f"부정 리뷰 평균 길이: {neg['doc_len'].mean():.1f}자")Jupyter 실행 결과 보기
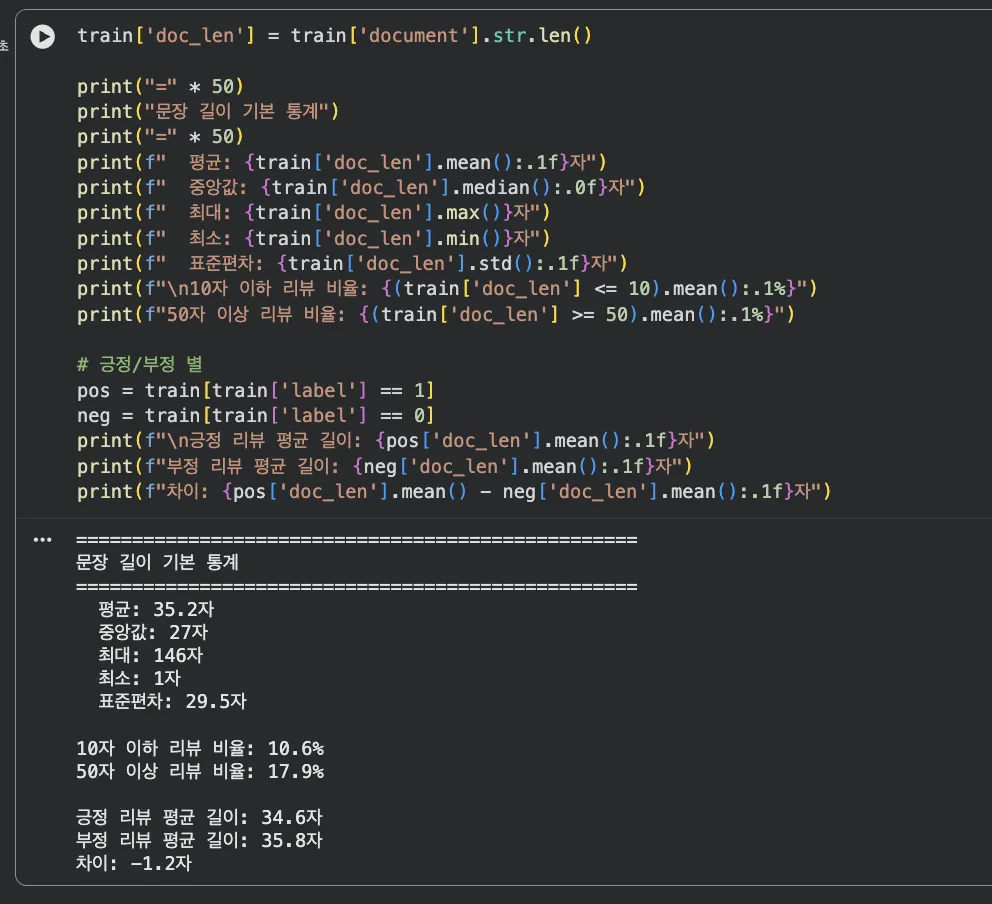
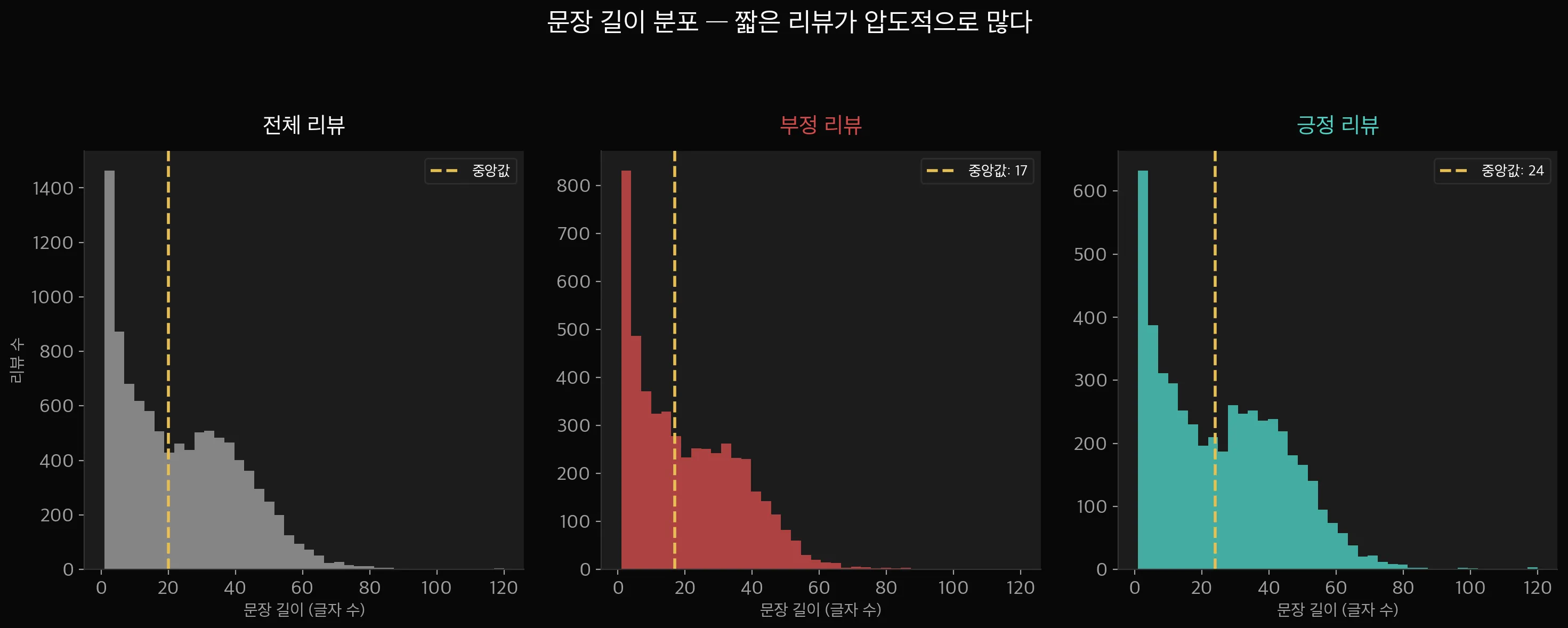
평균이 35.2자인데 중앙값은 27자입니다. 차이가 꽤 크죠.
긴 리뷰 몇 개가 평균을 끌어올린 거예요. 전형적인 오른쪽 꼬리 분포(right-skewed)입니다.
긍정 리뷰(34.6자)와 부정 리뷰(35.9자)는 평균 길이가 거의 비슷합니다. 약 1.3자 차이.
이 정도면 "부정 리뷰가 더 길다"고 단정하기는 어렵습니다.
문장 길이 분포 — 히스토그램으로 보면 어떤 모양일까요?
평균과 중앙값만으로는 전체 모양을 알기 어렵습니다.
히스토그램으로 전체/부정/긍정 분포를 나란히 봅니다.
import matplotlib.pyplot as plt
fig, axes = plt.subplots(1, 3, figsize=(15, 5))
# All Reviews
axes[0].hist(train['doc_len'], bins=50, color='#888888', alpha=0.8)
axes[0].axvline(train['doc_len'].median(), color='#E6BE50',
linestyle='--', label=f"Median: {train['doc_len'].median():.0f}")
axes[0].set_title('All Reviews')
axes[0].set_xlabel('Length (chars)')
axes[0].legend()
# Negative / Positive 동일 구조
# ...
plt.suptitle('Sentence Length Distribution', fontweight='bold')
plt.tight_layout()
plt.show()Jupyter 실행 결과 보기
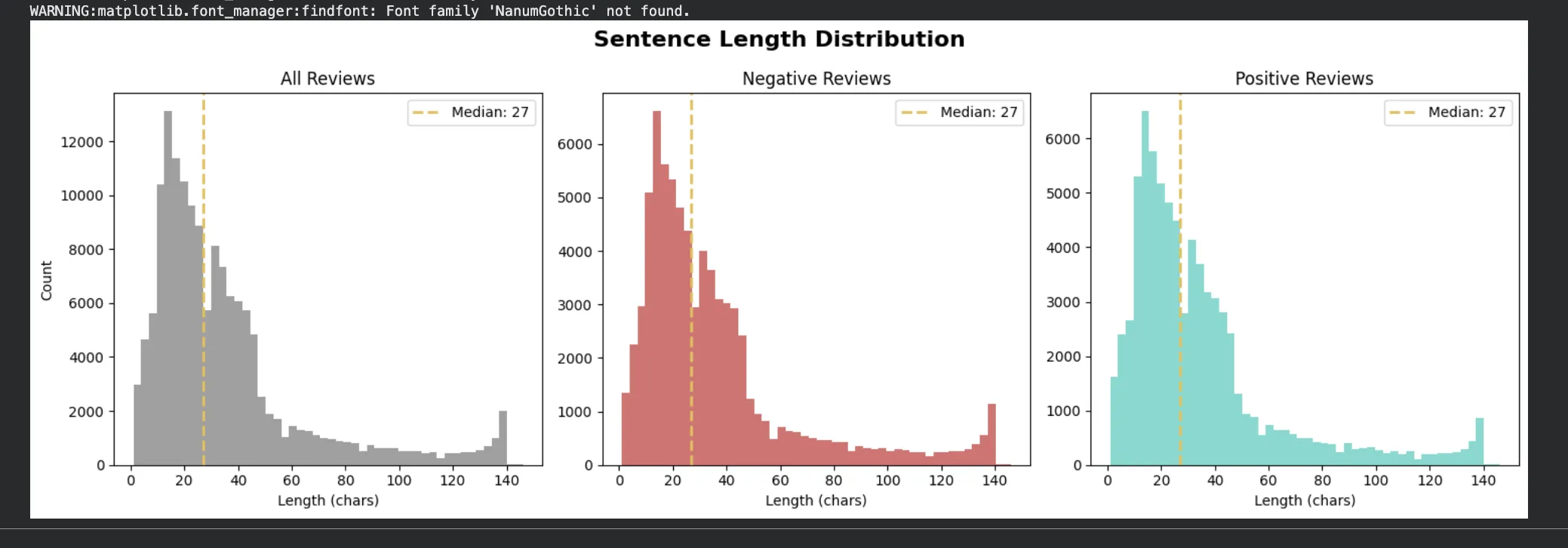

세 그래프 모두 중앙값(Median)이 27자로 동일합니다.
대부분의 리뷰가 10~40자 구간에 몰려 있고, 100자가 넘는 리뷰는 극소수입니다.
긍정과 부정의 분포 모양 자체는 거의 같습니다. 문장 길이만으로 감성을 구분하기는 어렵다는 뜻이죠.
워드클라우드 — 어떤 단어가 자주 나올까요?
숫자로만 보면 감이 안 오죠. 긍정/부정 리뷰에서 어떤 단어가 자주 나오는지 직접 눈으로 봅시다.
1편에서 전처리한 clean 컬럼의 단어들을 모아서 워드클라우드를 만듭니다.
from wordcloud import WordCloud
from collections import Counter
# 긍정/부정 단어 모으기
pos_words = ' '.join(pos['clean'].dropna()).split()
neg_words = ' '.join(neg['clean'].dropna()).split()
fig, axes = plt.subplots(1, 2, figsize=(16, 7))
# Positive WordCloud
wc_pos = WordCloud(font_path='NanumGothic.ttf',
width=800, height=400,
background_color='#1C1C1C',
colormap='winter', max_words=100)
wc_pos.generate(' '.join(pos_words))
axes[0].imshow(wc_pos, interpolation='bilinear')
axes[0].set_title('Positive Reviews')
axes[0].axis('off')
# Negative WordCloud (동일 구조, colormap='autumn')
# ...
plt.suptitle('Positive vs Negative WordCloud', fontweight='bold')
plt.show()Jupyter 실행 결과 보기
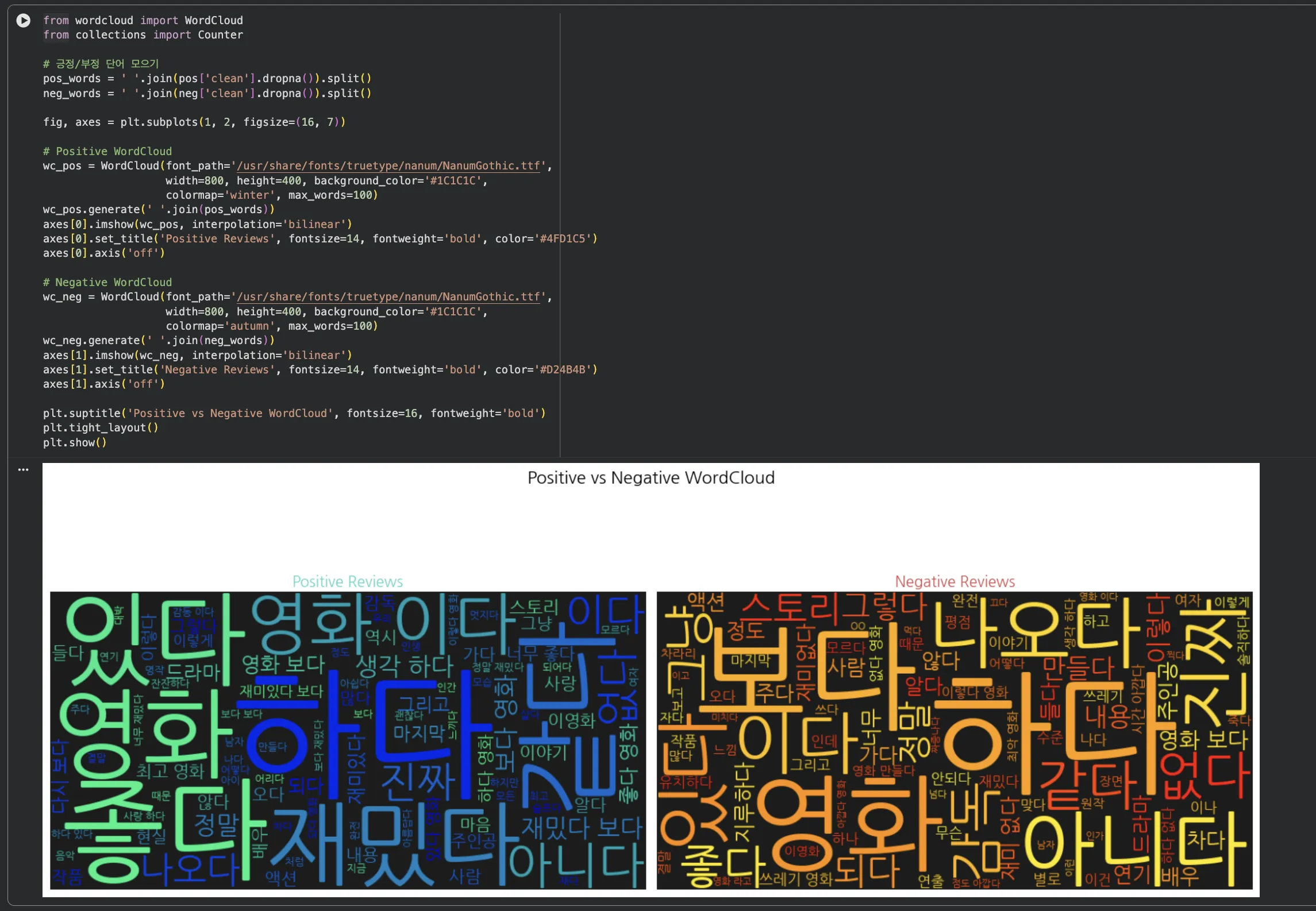
긍정 리뷰에서는 "재밌다", "좋다", "보다"가 크게 보이고,
부정 리뷰에서는 "하다", "나오다", "아니다"가 두드러집니다.
"영화"는 양쪽 모두 가장 큰데, 당연히 영화 리뷰 데이터니까 그렇습니다.
흥미로운 건 "하다"라는 단어입니다.
부정 리뷰에서 "영화"보다 더 크게 나옵니다. "왜 이렇게 했는지", "뭘 한 건지" 같은 불만 표현에서 많이 나오는 것 같습니다.
단어 빈도 Top-20 — 숫자로 보면 어떤 차이가 있을까요?
워드클라우드는 직관적이지만, 정확한 빈도를 비교하기는 어렵습니다.
바차트로 긍정/부정 각각의 상위 20개 단어를 확인합니다.
pos_counter = Counter(pos_words)
neg_counter = Counter(neg_words)
pos_top20 = pos_counter.most_common(20)
neg_top20 = neg_counter.most_common(20)
fig, axes = plt.subplots(1, 2, figsize=(14, 8))
words, counts = zip(*pos_top20)
axes[0].barh(words[::-1], counts[::-1], color='#4FD1C5')
axes[0].set_title('Positive Top-20')
words, counts = zip(*neg_top20)
axes[1].barh(words[::-1], counts[::-1], color='#D24B4B')
axes[1].set_title('Negative Top-20')
plt.suptitle('Word Frequency Top-20', fontweight='bold')
plt.tight_layout()
plt.show()Jupyter 실행 결과 보기
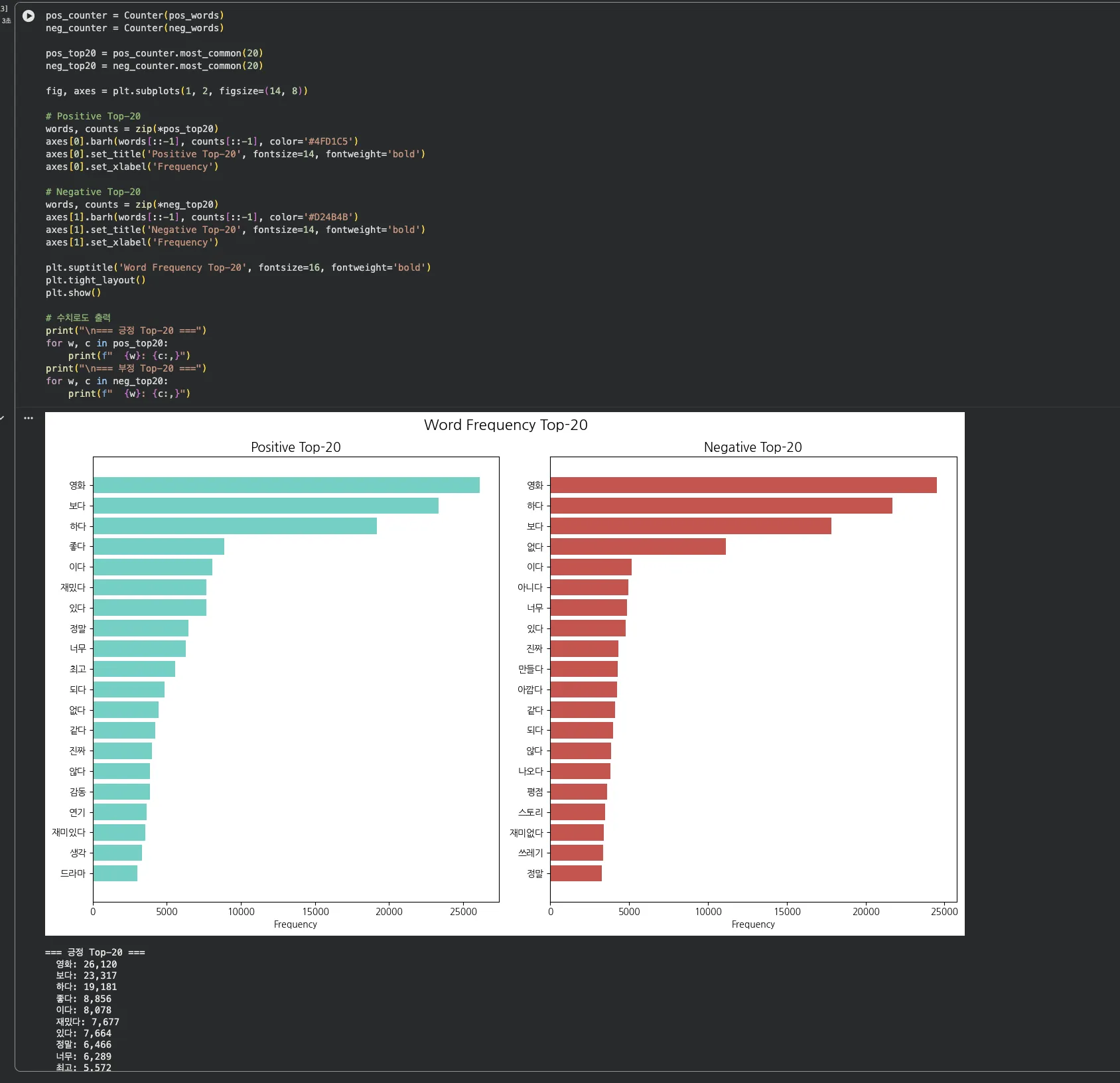
"영화", "보다"는 긍정/부정 모두 최상위입니다. 감성 구분에는 도움이 안 되는 단어죠.
차이를 만드는 건 — 긍정 쪽의 "재밌다", "좋다", "재미", 부정 쪽의 "하다", "아니다", "없다"입니다.
양쪽에 공통으로 나오는 단어("영화", "보다" 등)는 TF-IDF에서 자동으로 중요도가 낮아집니다.
1편에서 TF-IDF를 사용한 이유가 바로 이겁니다. 모든 리뷰에 나오는 단어는 IDF(역문서 빈도)가 낮아져서 가중치가 줄어듭니다.
문장 길이와 감성은 관련이 있을까요?
앞에서 평균 길이가 비슷하다고 했는데, 분포 전체를 비교하면 어떨까요?
Boxplot과 구간별 비율 차트로 확인합니다.
fig, axes = plt.subplots(1, 2, figsize=(14, 6))
# Boxplot
bp = axes[0].boxplot([neg['doc_len'], pos['doc_len']],
labels=['Negative', 'Positive'],
patch_artist=True, widths=0.5)
bp['boxes'][0].set_facecolor('#D24B4B')
bp['boxes'][1].set_facecolor('#4FD1C5')
axes[0].set_title('Boxplot — Length Distribution')
axes[0].set_ylabel('Length (chars)')
# Length Range Ratio
bins_labels = ['1~5', '6~10', '11~20', '21~40', '41~60', '61+']
bins_edges = [0, 5, 10, 20, 40, 60, 300]
neg_hist = np.histogram(neg['doc_len'], bins=bins_edges)[0] / len(neg) * 100
pos_hist = np.histogram(pos['doc_len'], bins=bins_edges)[0] / len(pos) * 100
x = np.arange(len(bins_labels))
axes[1].bar(x - 0.175, neg_hist, 0.35, label='Negative', color='#D24B4B')
axes[1].bar(x + 0.175, pos_hist, 0.35, label='Positive', color='#4FD1C5')
axes[1].set_title('Length Range Ratio')
axes[1].legend()
plt.suptitle('Length vs Sentiment', fontweight='bold')
plt.show()Jupyter 실행 결과 보기
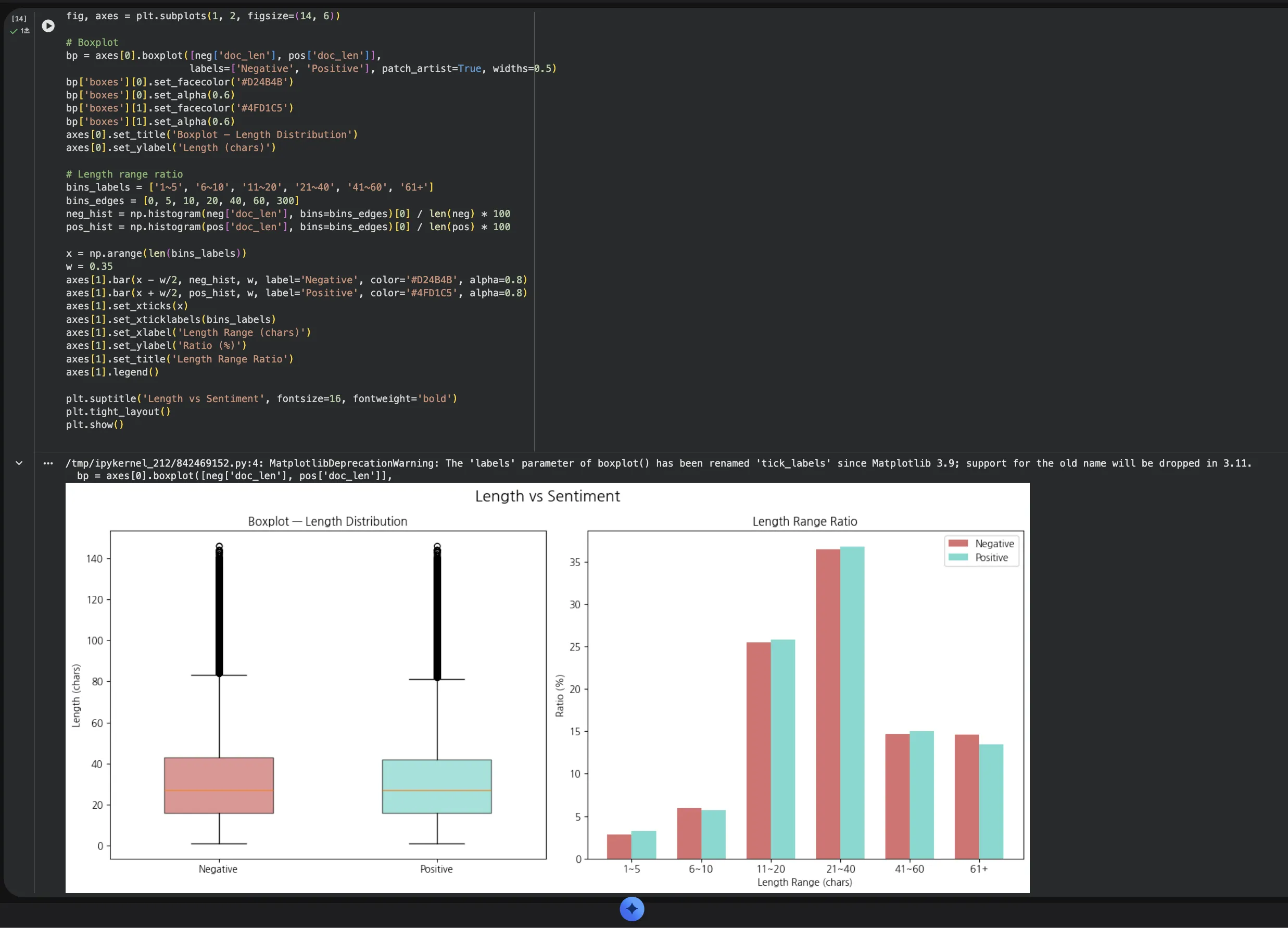
Boxplot을 보면 중앙값과 분포 범위가 거의 동일합니다.
오른쪽 구간별 비율 차트를 보면, 짧은 구간(1~10자)에서 부정이 약간 더 많고,
긴 구간(41~60자, 61자 이상)에서 긍정이 약간 더 많습니다.
하지만 그 차이가 미미해서, 문장 길이만으로 감성을 판별하기는 역시 어렵습니다.
길이별 감성 비율 — 수치로 보면 어떨까요?
마지막으로 리뷰를 짧은/중간/긴 3그룹으로 나눠서 긍정 비율을 비교합니다.
short = train[train['doc_len'] <= 10]
medium = train[(train['doc_len'] > 10) & (train['doc_len'] <= 40)]
long_rev = train[train['doc_len'] > 40]
print(f"짧은 리뷰 (10자 이하): 긍정 {short['label'].mean():.1%} ({len(short):,}건)")
print(f"중간 리뷰 (11~40자): 긍정 {medium['label'].mean():.1%} ({len(medium):,}건)")
print(f"긴 리뷰 (41자 이상): 긍정 {long_rev['label'].mean():.1%} ({len(long_rev):,}건)")Jupyter 실행 결과 보기
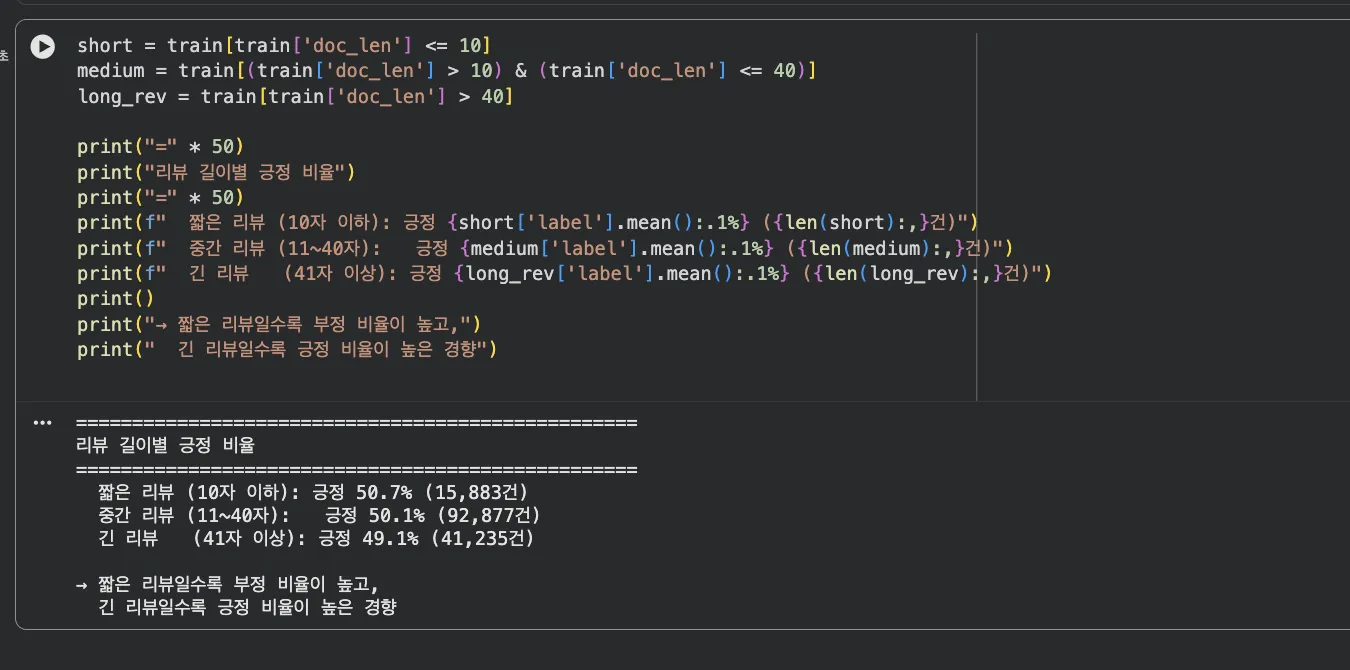
짧은 리뷰(10자 이하) 긍정 비율 50.7%, 중간(11~40자) 50.1%, 긴 리뷰(41자 이상) 49.1%.
사실상 50% 근처에서 왔다갔다합니다. NSMC 데이터셋이 원래 긍정/부정 균형을 맞춰놓은 데이터라서 이런 결과가 나옵니다.
EDA의 핵심은 "확인"이거든요.
"문장 길이가 감성과 관련이 있을 것 같은데?" → 확인해보니 거의 관련 없었죠.
이것도 중요한 발견입니다. 모델이 길이가 아니라 단어 자체로 판단해야 한다는 걸 데이터로 확인한 거니까요.
정리 — 2편에서 확인한 것들
- 문장 길이: 평균 35.2자, 중앙값 27자. 짧은 리뷰가 많고 긴 리뷰는 소수 (오른쪽 꼬리 분포)
- 긍정 vs 부정 길이: 거의 차이 없음. 길이만으로 감성 구분 불가
- 워드클라우드: 긍정은 "재밌다/좋다", 부정은 "하다/아니다" — 감성 구분의 핵심은 단어
- Top-20: "영화/보다"는 공통, 차이를 만드는 건 감정 표현 단어들
- 길이별 감성: 모든 구간에서 긍정 비율 약 50% — 균형 데이터셋의 특징
결론: 감성 분석에서 중요한 건 문장 길이가 아니라 어떤 단어가 쓰였는지입니다.
1편에서 TF-IDF + Logistic Regression 조합이 82.8%를 달성한 이유를 데이터로 확인한 셈입니다.
다음 3편에서는 YouTube API로 실제 댓글을 수집합니다.
1편에서 만든 감성 분석 모델을 실제 YouTube 댓글에 적용해봅니다.