
[소셜 미디어 트렌드 3편] YouTube API로 댓글 523건 수집하고 감성 분석까지
Google Cloud Console에서 API 키를 발급받고, YouTube Data API v3으로 댓글을 수집합니다. 키워드 검색 → 영상 10개 → 댓글 523건 수집 → 1편 감성 분석 모델 적용까지, 실제 데이터 파이프라인을 만드는 과정입니다.
시작하며 — 이제 진짜 데이터를 모을 차례
1편에서 감성 분석 모델을 만들었고, 2편에서 텍스트 EDA로 데이터 특성을 확인했습니다.
그런데 지금까지 쓴 데이터는 전부 NSMC(네이버 영화 리뷰) — 누군가 만들어놓은 공개 데이터셋이었죠.
이번 3편에서는 직접 데이터를 수집합니다.
YouTube Data API v3을 사용해서 키워드로 영상을 검색하고, 댓글을 수집하고,
1편에서 만든 모델로 감성 분석까지 적용해봅니다.
전체 흐름 — API 키부터 감성 분석까지 어떤 단계를 거칠까요?
YouTube 댓글 수집과 분석은 API 키 발급, 영상 검색, 댓글 수집, 데이터 정리, 감성 분석 이렇게 5단계로 진행됩니다. 핵심은 search().list()로 영상을 찾고 commentThreads().list()로 댓글을 가져오는 API 두 개만 이해하면 전체 파이프라인을 만들 수 있다는 거예요.
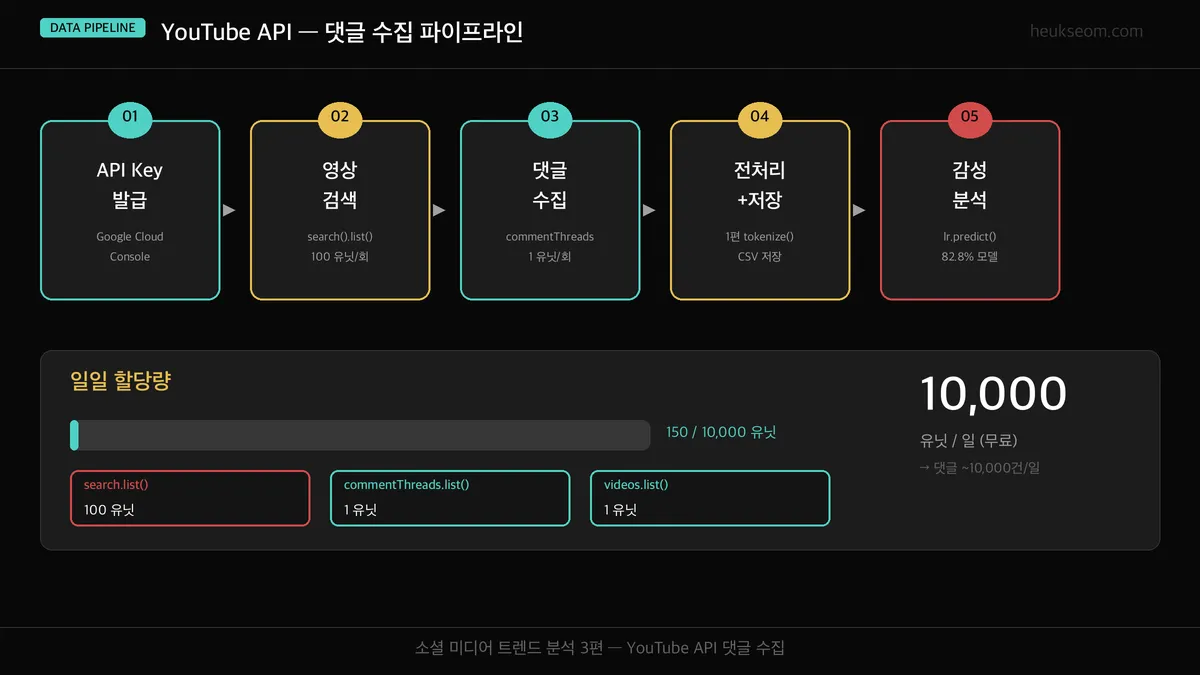
5단계로 진행됩니다. API 키 발급 → 영상 검색 → 댓글 수집 → 데이터 정리 → 감성 분석.
핵심은 API 두 개만 이해하면 됩니다.
- search().list(): 키워드로 영상 검색 (100 유닛/회)
- commentThreads().list(): 영상 댓글 조회 (1 유닛/회)
Step 1 — Google Cloud Console에서 API 키는 어떻게 발급할까요?

구글 계정만 있으면 5분이면 발급됩니다.
- Google Cloud Console 접속 (console.cloud.google.com)
- 새 프로젝트 생성 — 이름은 아무거나 (예: youtube-comments)
- YouTube Data API v3 활성화 — API 및 서비스 → 라이브러리 → 검색
- 사용자 인증 정보 → API 키 만들기
- 키 복사 → 코드에서 사용
API 키는 절대 공개 저장소에 올리면 안 됩니다.
.env 파일이나 환경변수로 숨겨두세요.
할당량 초과되면 429 에러가 나옵니다.
Step 2 — API 클라이언트 생성과 영상 검색은 어떻게 할까요?
from googleapiclient.discovery import build
import pandas as pd
import time
youtube = build('youtube', 'v3', developerKey=API_KEY)
print("YouTube API 클라이언트 생성 완료!")Jupyter 실행 결과 보기 — API 클라이언트 생성
이제 이 클라이언트로 키워드를 넣어서 영상을 검색합니다.
def search_videos(query, max_results=10):
request = youtube.search().list(
q=query,
type='video',
part='snippet',
maxResults=max_results,
order='relevance',
relevanceLanguage='ko'
)
response = request.execute()
videos = []
for item in response['items']:
videos.append({
'video_id': item['id']['videoId'],
'title': item['snippet']['title'],
'channel': item['snippet']['channelTitle'],
'published': item['snippet']['publishedAt'][:10],
})
return videos
query = "파이썬 머신러닝"
videos = search_videos(query, max_results=10)Jupyter 실행 결과 보기 — 영상 검색 결과
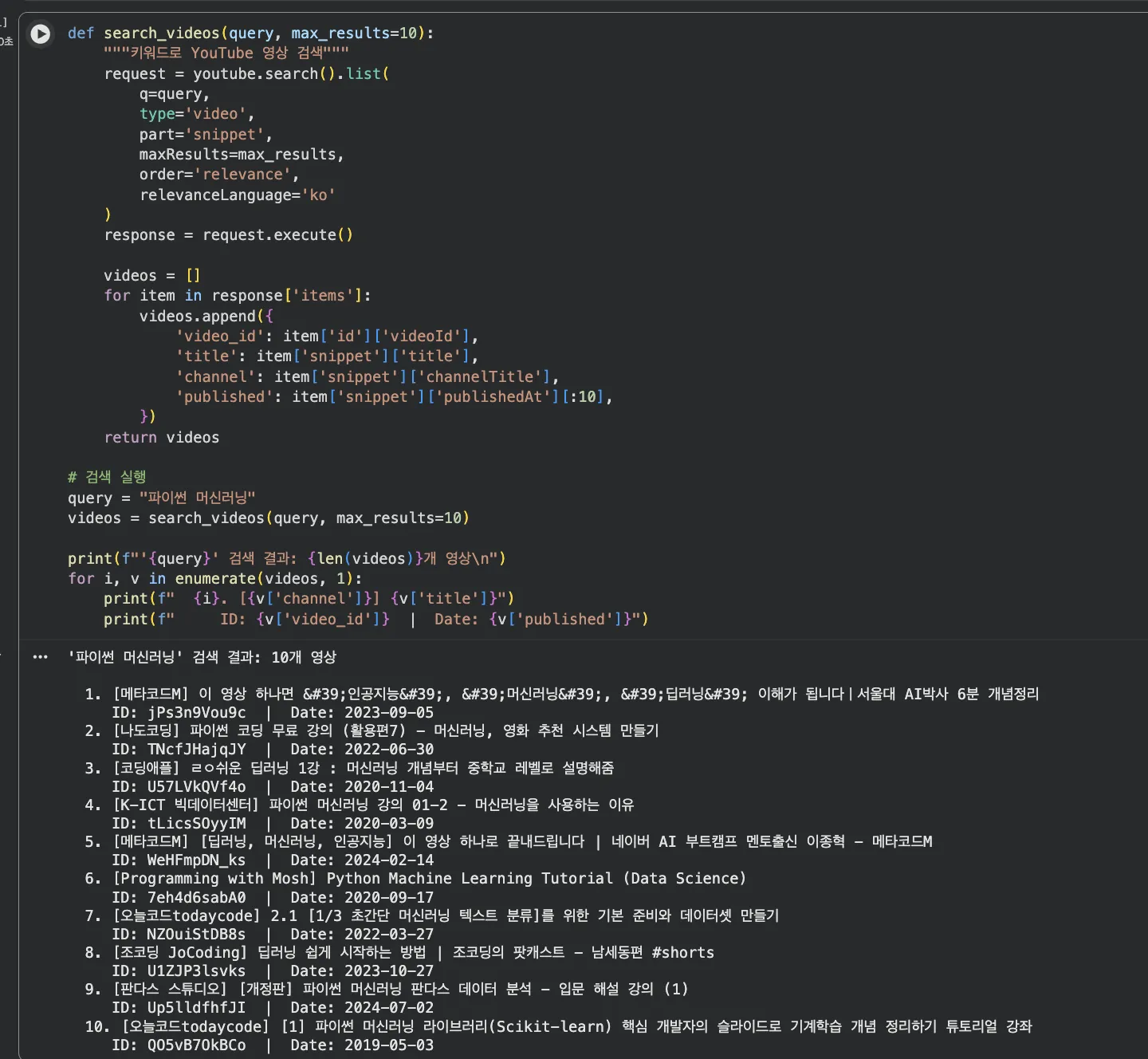
"파이썬 머신러닝"으로 검색하니 10개 영상이 나왔습니다.
search().list() 한번에 100 유닛이 소모됩니다. 일일 10,000 유닛이니까 하루에 100번 검색할 수 있는 셈이죠.
Step 3 — 댓글은 어떻게 수집할까요?
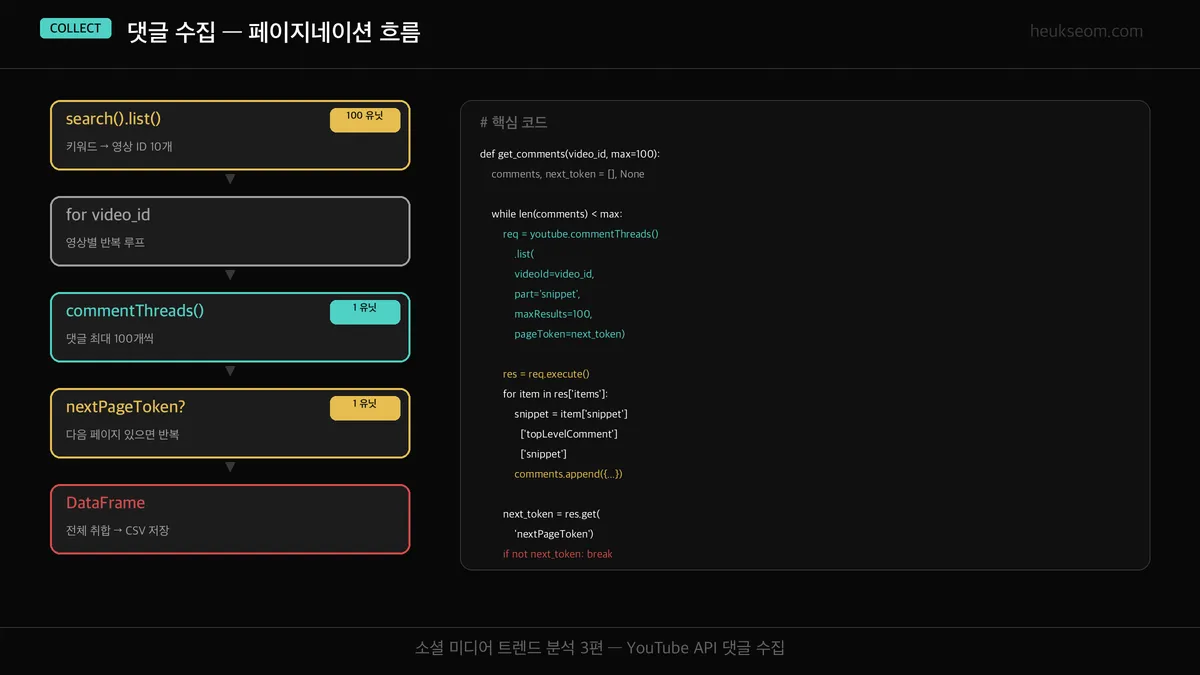
YouTube API는 한번에 최대 100개 댓글만 반환합니다.
댓글이 100개 넘는 영상이면 nextPageToken으로 다음 페이지를 반복 요청해야 합니다.
def get_comments(video_id, max_comments=100):
comments = []
next_token = None
while len(comments) < max_comments:
request = youtube.commentThreads().list(
videoId=video_id,
part='snippet',
maxResults=min(100, max_comments - len(comments)),
textFormat='plainText',
order='relevance',
pageToken=next_token
)
try:
response = request.execute()
except Exception as e:
print(f" Error: {e}")
break
for item in response['items']:
snippet = item['snippet']['topLevelComment']['snippet']
comments.append({
'video_id': video_id,
'author': snippet['authorDisplayName'],
'comment': snippet['textDisplay'],
'likes': snippet['likeCount'],
'date': snippet['publishedAt'][:10],
})
next_token = response.get('nextPageToken')
if not next_token:
break
return commentsJupyter 실행 결과 보기 — 단일 영상 댓글 테스트
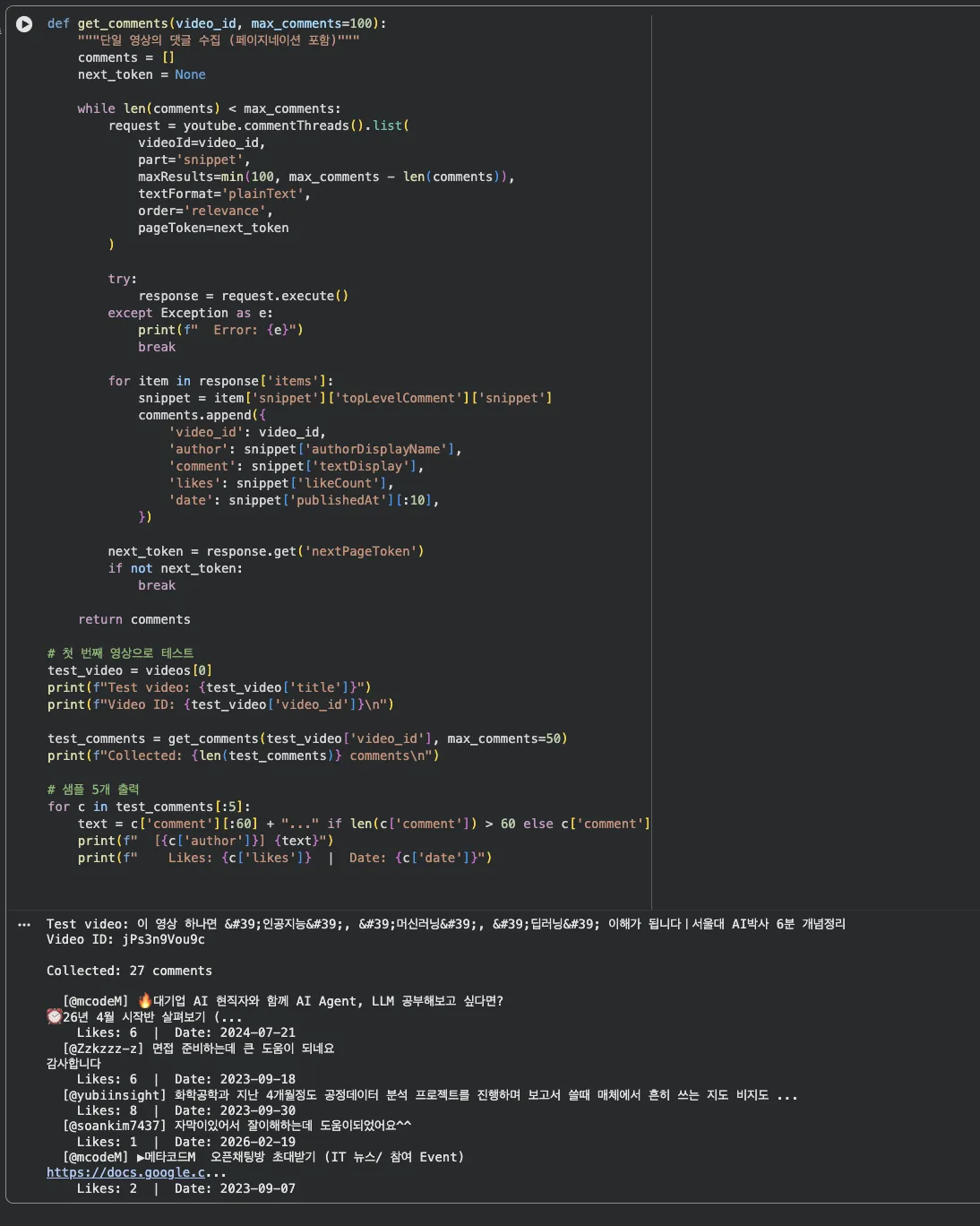
한 영상으로 테스트해보면 댓글이 잘 수집됩니다.
이제 10개 영상 전체를 반복합니다.
all_comments = []
for i, v in enumerate(videos, 1):
print(f" [{i}/{len(videos)}] {v['title'][:40]}...", end=" ")
comments = get_comments(v['video_id'], max_comments=200)
all_comments.extend(comments)
print(f"→ {len(comments)} comments")
time.sleep(1) # API 할당량 보호
df = pd.DataFrame(all_comments)Jupyter 실행 결과 보기 — 전체 영상 댓글 수집
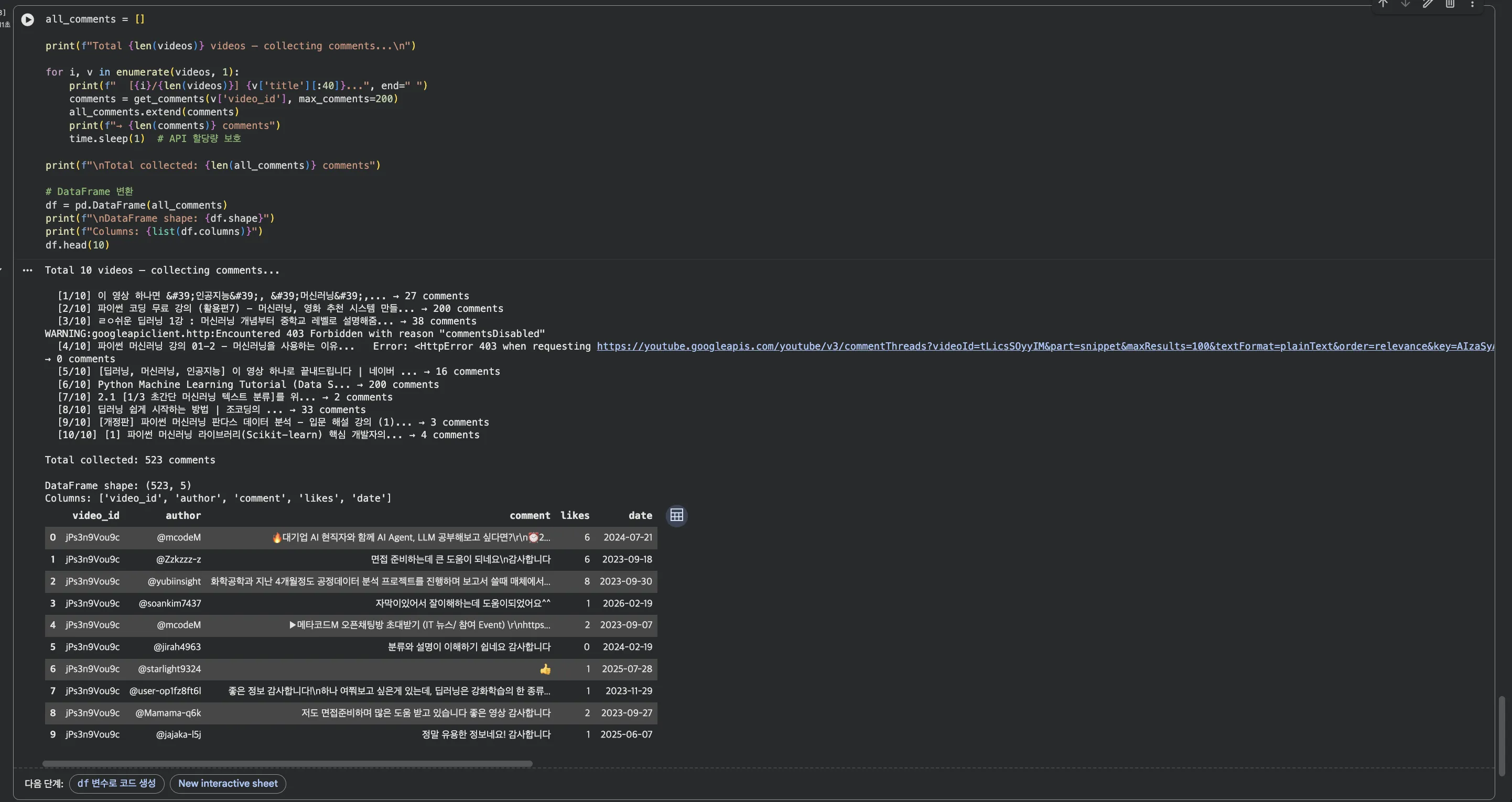
time.sleep(1)을 넣은 이유는 할당량 보호입니다.
너무 빠르게 요청하면 할당량을 순식간에 소진하거나, 429(Too Many Requests) 에러가 날 수 있습니다.
Step 4 — 수집한 데이터는 어떻게 확인하고 저장할까요?
print(f"Total comments: {len(df):,}")
print(f"Unique videos: {df['video_id'].nunique()}")
print(f"Avg comment length: {df['comment'].str.len().mean():.1f} chars")
df.to_csv('youtube_comments.csv', index=False, encoding='utf-8-sig')Jupyter 실행 결과 보기
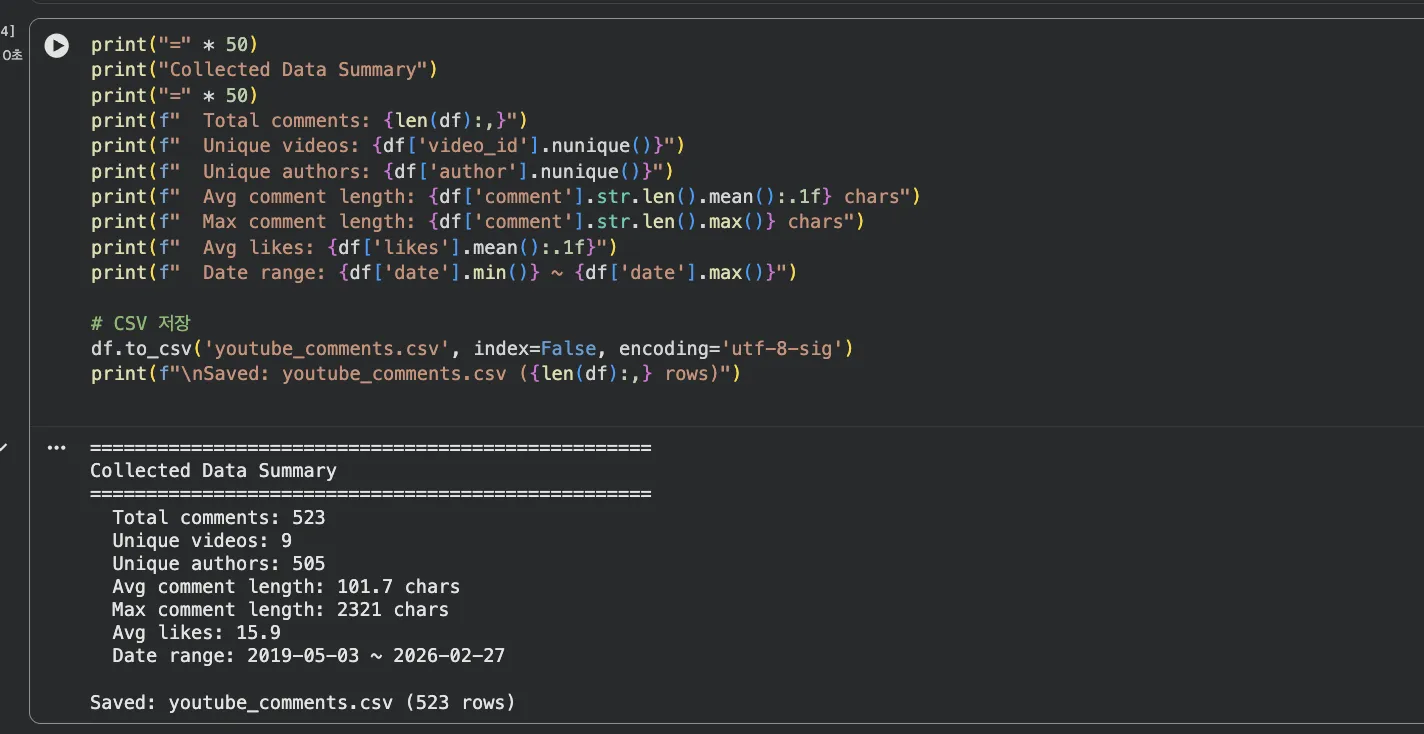
총 523건 수집, 영상 9개(댓글 비활성화 1개 제외), 작성자 505명.
재밌는 건 평균 댓글 길이가 101.7자라는 거예요. NSMC 영화 리뷰(평균 35자)보다 거의 3배 길죠.
YouTube 댓글은 한줄평보다 서술형이 많으니까 그런 것 같습니다.
Step 5 — 1편 감성 분석 모델을 YouTube 댓글에 적용하면 어떨까요?
드디어 1편에서 만든 모델을 실전에 적용합니다.
NSMC로 학습한 Logistic Regression(82.8%)을 YouTube 댓글에 바로 적용해봅니다.
# 1편 전처리 함수 + 모델 재학습
from konlpy.tag import Okt
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
# NSMC 데이터로 모델 학습 (1편과 동일)
train = pd.read_csv('ratings_train.txt', sep='\t')
train = train.dropna(subset=['document'])
train['clean'] = train['document'].progress_apply(tokenize)
tfidf = TfidfVectorizer(max_features=10000)
X_train = tfidf.fit_transform(train['clean'])
lr = LogisticRegression(max_iter=1000)
lr.fit(X_train, train['label'])Jupyter 실행 결과 보기 — 모델 학습
# YouTube 댓글에 감성 분석 적용
df['clean'] = df['comment'].apply(tokenize)
X_comments = tfidf.transform(df['clean'])
df['sentiment'] = lr.predict(X_comments)
df['confidence'] = lr.predict_proba(X_comments).max(axis=1)
pos_count = (df['sentiment'] == 1).sum()
neg_count = (df['sentiment'] == 0).sum()
print(f"Positive: {pos_count:,} ({pos_count/len(df):.1%})")
print(f"Negative: {neg_count:,} ({neg_count/len(df):.1%})")Jupyter 실행 결과 보기 — 감성 분석 결과
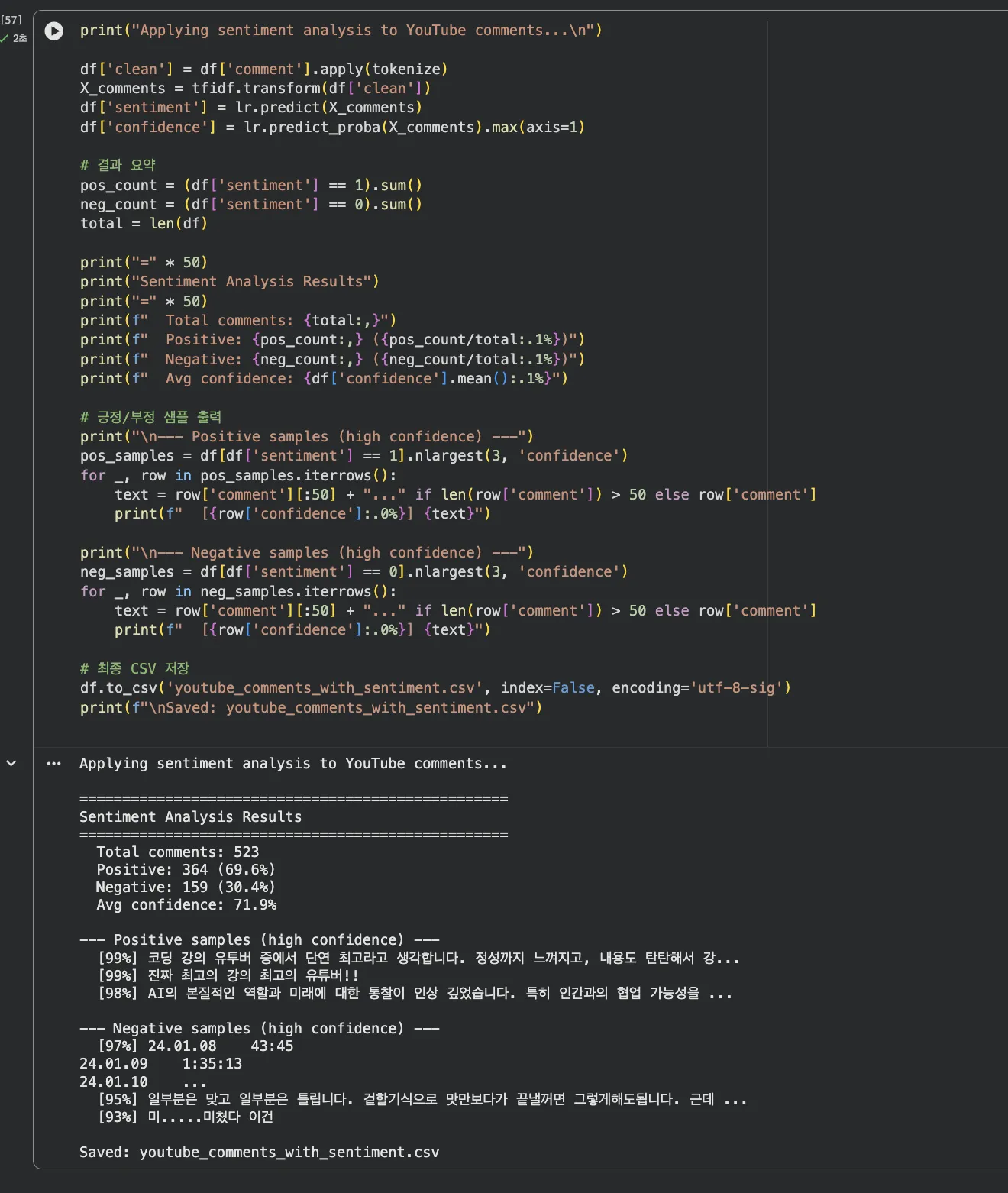
결과를 보면 긍정 69.6%, 부정 30.4%입니다.
"파이썬 머신러닝" 관련 영상이다 보니 "감사합니다", "유익해요" 같은 긍정 댓글이 많은 건 자연스럽습니다.
평균 신뢰도는 71.9%로, NSMC 영화 리뷰로 학습한 모델이 YouTube 댓글에서도 어느 정도 작동한다는 걸 확인했습니다.
신뢰도 71.9%가 낮은 건 아닌가?
NSMC는 "영화 리뷰" 데이터이고, YouTube 댓글은 주제와 문체가 다릅니다.
도메인이 다르면 성능이 떨어지는 건 당연합니다. 실무에서는 YouTube 댓글로 다시 학습(Fine-tuning)하는 과정이 필요합니다.
API 할당량 관리 — 무료로 얼마나 할 수 있을까요?
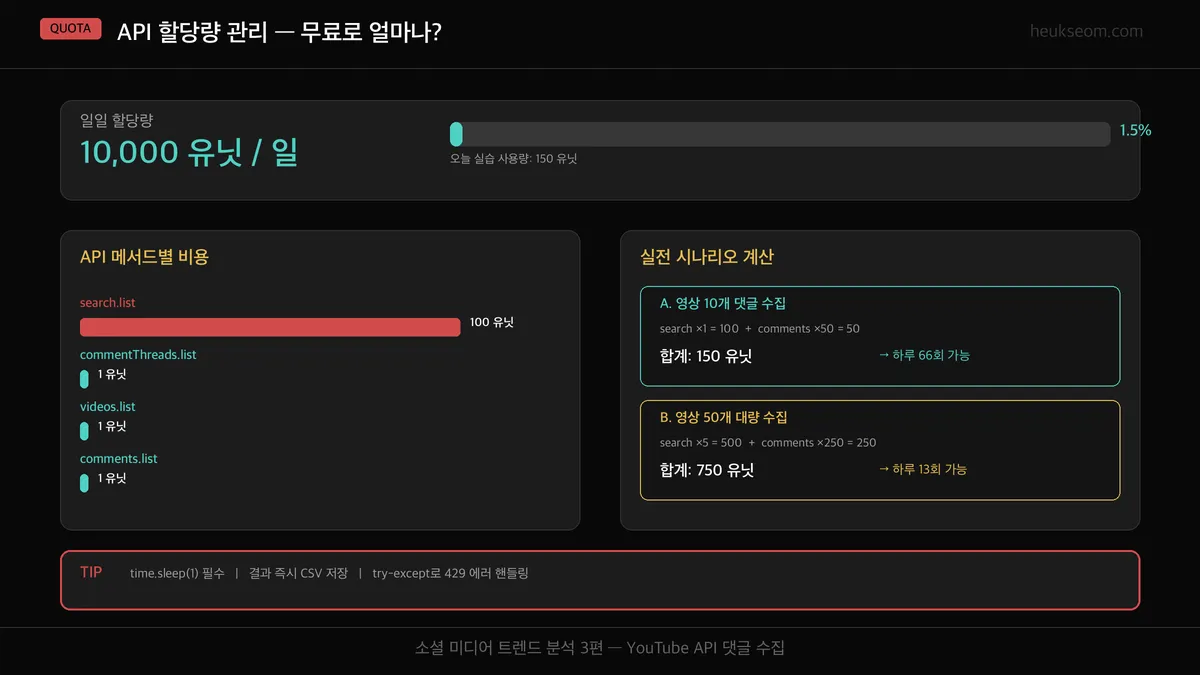
YouTube Data API v3은 일일 10,000 유닛이 무료입니다.
가장 비싼 건 search().list() — 1회에 100 유닛.
반면 commentThreads().list()는 1회에 1 유닛이라 거의 부담 없습니다.
오늘 실습에서 쓴 할당량을 계산해보면:
search 1회(100) + commentThreads 약 50회(50) = 약 150 유닛.
하루에 이런 작업을 66번은 할 수 있는 셈이니, 개인 프로젝트에는 충분합니다.
정리 — 3편에서 한 것들
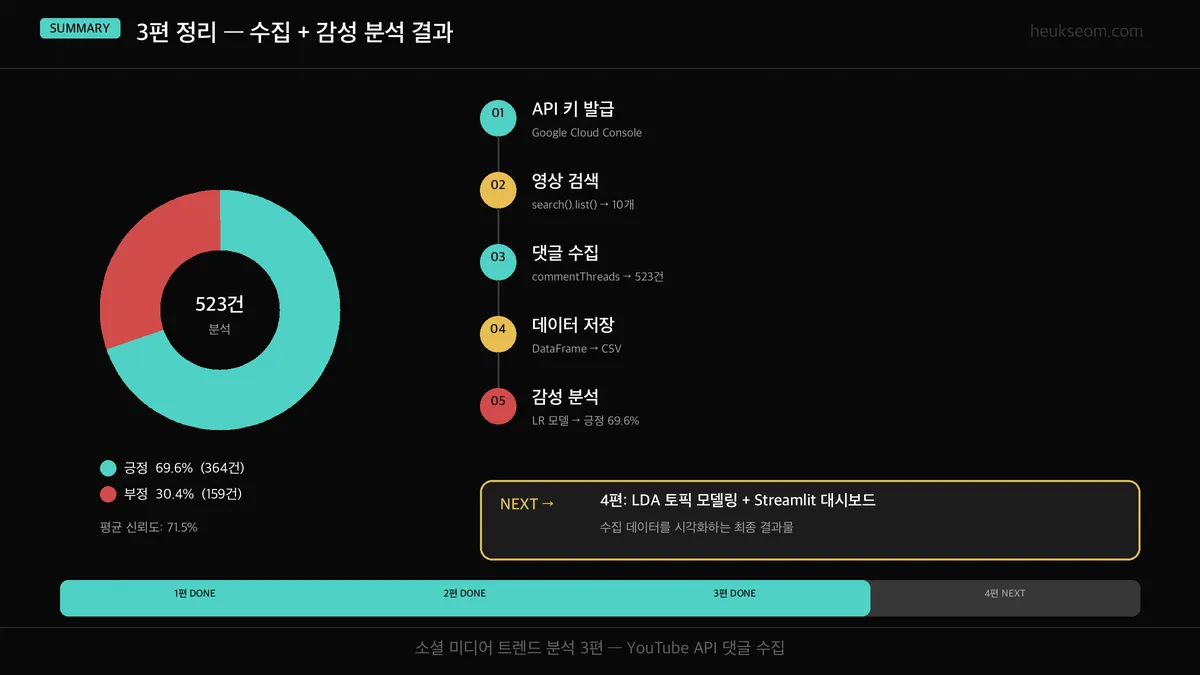
- API 키 발급: Google Cloud Console에서 YouTube Data API v3 활성화
- 영상 검색: search().list()로 "파이썬 머신러닝" 관련 영상 10개 탐색
- 댓글 수집: commentThreads().list() + 페이지네이션으로 523건 수집
- 데이터 정리: DataFrame 변환 + CSV 저장 (평균 101.7자, 505명)
- 감성 분석: 1편 모델 적용 → 긍정 69.6%, 부정 30.4% (신뢰도 71.9%)
다음 4편에서는 이 데이터를 LDA 토픽 모델링으로 주제별로 분류하고,
Streamlit 대시보드로 시각화해서 최종 결과물을 만듭니다.