
[알고리즘 기초 3편] 정렬 알고리즘 비교 — 버블·삽입·퀵·병합
버블, 삽입, 퀵, 병합 정렬을 직접 구현하고 성능을 비교합니다. O(n²)과 O(n log n)이 실제로 얼마나 차이나는지, 데이터 상황별로 어떤 정렬이 유리한지 숫자로 확인해봅니다.
시작하며 — 알고리즘, 어떤 걸 고르느냐에 따라 결과가 확 달라집니다
요즘 기술 업계는 트렌드가 정말 빠르게 바뀝니다.
그 속에서 지내다 보니 자연스럽게 느끼게 됐어요 — 기초가 탄탄한 사람이 결국 강하다고.
트렌드가 바뀌어도 변하지 않는 근본을 잡고 있으면, 새로운 걸 배우는 속도 자체가 달라지거든요.
그래서 한동안은 이런 기초 포스팅을 이어가려고 합니다. 초반엔 좀 지루할 수도 있겠지만 ㅎㅎ
차차 AI를 어떻게 다루고, 이용하고, 실제로 활용하는지도 같이 다룰 예정입니다.
알고리즘은 종류가 많습니다.
그리고 같은 문제라도 어떤 알고리즘을 선택하느냐에 따라 결과가 완전히 달라지죠.
적재적소에 맞는 걸 골라 써야 한다는 게, 이걸 공부하면서 점점 더 느껴지더라고요.
그래서 이번 편부터는 기초 개념 소개에서 한 발 나아가,
알고리즘을 직접 적용하고 비교하는 것을 같이 해보려 합니다.
n=10,000 기준으로 버블 정렬은 620ms, 퀵 정렬은 2.8ms — 약 221배 차이가 납니다.
1편(스택·큐·재귀)에서 배운 재귀가 퀵·병합 정렬의 핵심입니다.
2편(DFS·BFS)의 그래프 탐색도 정렬된 데이터 위에서 더 빠르게 동작합니다.
4가지 정렬을 직접 구현하고, 실제 성능 차이를 숫자로 확인해봅시다.
4가지 정렬 알고리즘, 어떤 차이가 있나요?
버블과 삽입 정렬은 O(n 제곱)으로 단순하지만 느리고, 퀵과 병합 정렬은 O(n log n)으로 데이터가 커질수록 압도적으로 빨라요. n이 10,000이면 버블 정렬은 620ms 걸리는데 퀵 정렬은 2.8ms면 끝납니다.
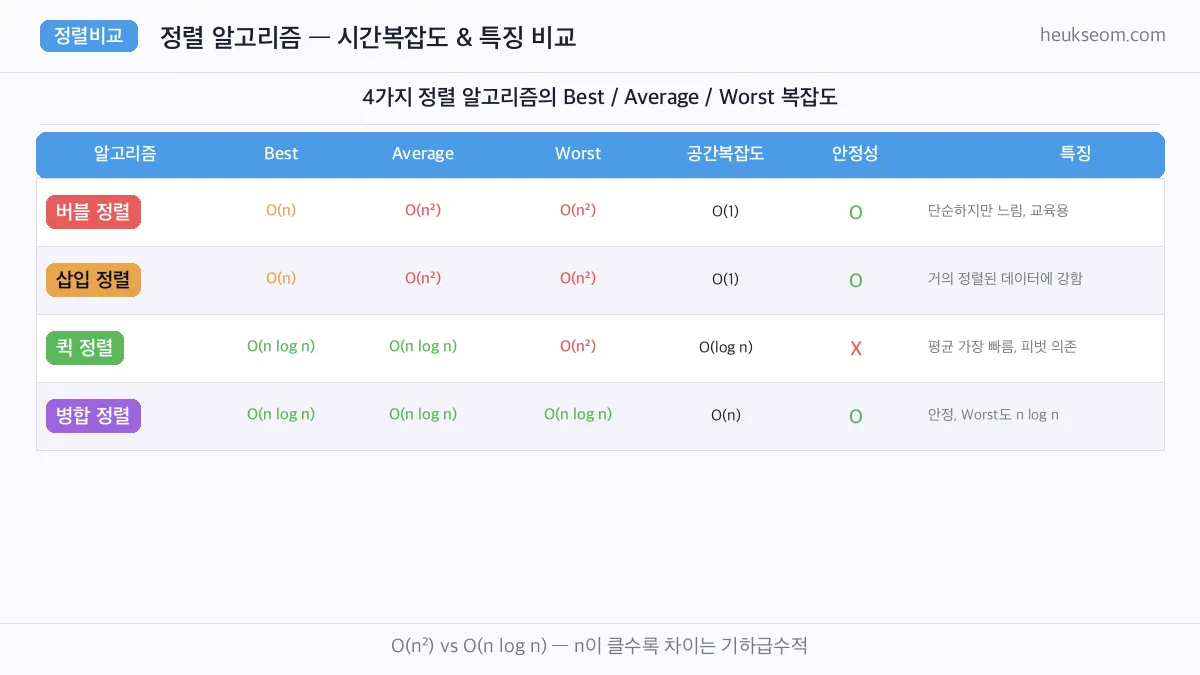
버블·삽입은 O(n²), 퀵·병합은 O(n log n)입니다.
O(n log n)은 n이 커질수록 압도적으로 유리합니다.
버블 정렬은 왜 가장 느린가요?
줄 서 있는 사람들이 옆 사람과 계속 자리를 바꾸는 과정을 생각해보세요.
키 큰 사람이 오른쪽으로 계속 밀려나면서 맨 끝부터 정렬됩니다.
접근법
인접한 두 원소 비교 → 큰 게 뒤로 → 1 pass마다 최댓값 확정 → 반복
def bubble_sort(arr):
n = len(arr)
for i in range(n):
swapped = False
for j in range(0, n - i - 1):
if arr[j] > arr[j + 1]:
arr[j], arr[j + 1] = arr[j + 1], arr[j]
swapped = True
if not swapped: # 교환 없으면 이미 정렬됨 → 조기 종료
break
return arr
# 테스트
arr = [64, 34, 25, 12, 22]
print(bubble_sort(arr))
# → [12, 22, 25, 34, 64]
매 pass마다 오른쪽부터 정렬이 확정됩니다.
swapped 플래그를 사용하면 이미 정렬된 경우 O(n)으로 조기 종료가 가능합니다.
삽입 정렬은 어떤 방식인가요?
손에 카드를 쥐고, 새 카드를 받을 때마다 맞는 위치에 끼워넣는 방식입니다.
왼쪽은 항상 정렬된 상태를 유지합니다.
접근법
정렬된 부분 + 미정렬 부분 → 미정렬 첫 원소를 정렬된 부분의 적절한 위치에 삽입
def insertion_sort(arr):
for i in range(1, len(arr)):
key = arr[i]
j = i - 1
while j >= 0 and arr[j] > key:
arr[j + 1] = arr[j] # 한 칸 오른쪽으로 밀기
j -= 1
arr[j + 1] = key # 올바른 위치에 삽입
return arr
# 테스트
arr = [12, 11, 13, 5, 6]
print(insertion_sort(arr))
# → [5, 6, 11, 12, 13]
거의 정렬된 데이터에서는 이동이 거의 없어 Best Case O(n)을 달성합니다.
소규모 배열이나 실시간 데이터 삽입에 유리합니다.
퀵 정렬은 왜 빠른가요?
기준점(피벗)을 하나 잡고, 작은 건 왼쪽 큰 건 오른쪽으로 분류합니다.
그 다음 각 파트에서 같은 작업을 재귀로 반복합니다.
접근법
피벗 선택 → 피벗 기준 분할 → 양쪽 재귀 → 합치기 (in-place)
def quick_sort(arr):
if len(arr) <= 1:
return arr
pivot = arr[len(arr) // 2] # 중간값을 피벗으로
left = [x for x in arr if x < pivot]
mid = [x for x in arr if x == pivot]
right = [x for x in arr if x > pivot]
return quick_sort(left) + mid + quick_sort(right)
# 테스트
arr = [3, 6, 8, 10, 1, 2, 1]
print(quick_sort(arr))
# → [1, 1, 2, 3, 6, 8, 10]
평균 O(n log n)으로 가장 빠릅니다. Python의 sorted()도 내부적으로 QuickSort 계열(Timsort)을 씁니다.
단, 이미 정렬된 배열에서 첫 번째 원소를 피벗으로 잡으면 Worst Case O(n²)이 됩니다.
병합 정렬은 왜 안정적인가요?
이전 코딩테스트 포스팅에서 분할 정복으로 이미 다뤘습니다.
핵심은 반으로 나눠 각각 정렬 후 합치는 것입니다.
접근법
반으로 분할 → 각각 재귀 정렬 → 두 배열 비교하며 합치기 (안정 정렬, Worst 없음)
def merge_sort(arr):
if len(arr) <= 1:
return arr
mid = len(arr) // 2
left = merge_sort(arr[:mid])
right = merge_sort(arr[mid:])
return merge(left, right)
def merge(left, right):
result = []
i = j = 0
while i < len(left) and j < len(right):
if left[i] <= right[j]:
result.append(left[i]); i += 1
else:
result.append(right[j]); j += 1
return result + left[i:] + right[j:]
# 테스트
arr = [38, 27, 43, 3, 9, 82, 10]
print(merge_sort(arr))
# → [3, 9, 10, 27, 38, 43, 82]
Worst Case도 O(n log n)으로 보장됩니다.
안정 정렬이라 같은 값의 순서가 유지되고, 연결 리스트 정렬에 최적입니다.
실제로 성능 차이가 얼마나 나나요?
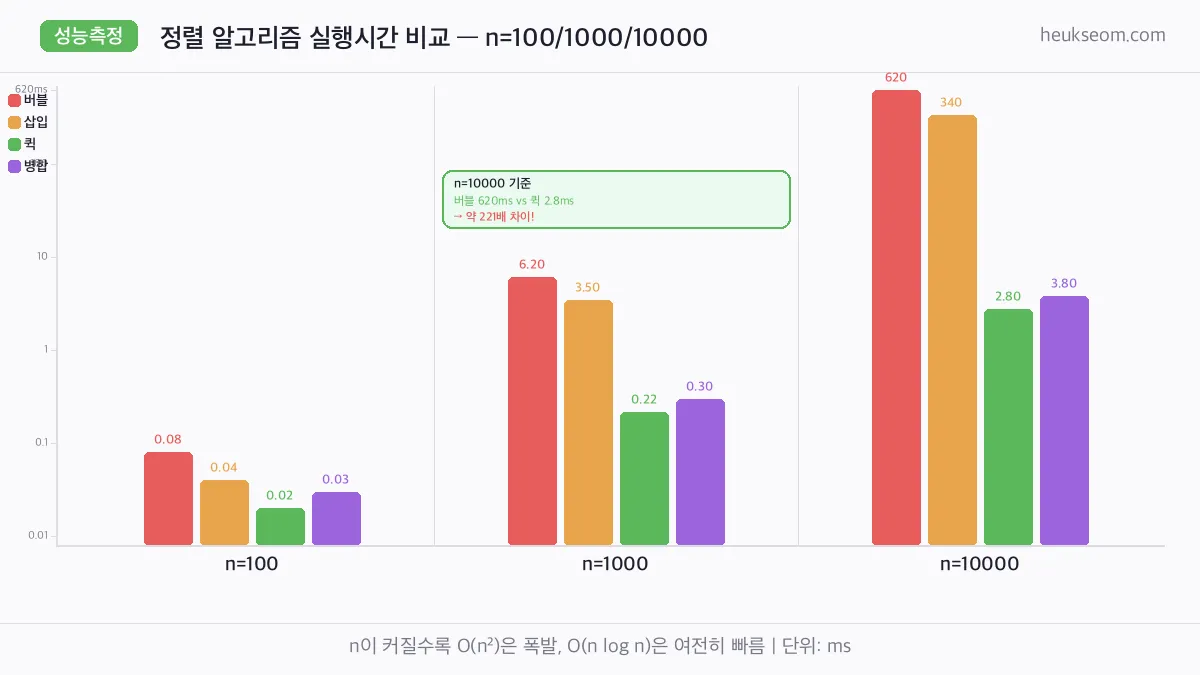
Python time 모듈로 직접 측정한 결과입니다.
n=100에서는 큰 차이가 없지만, n=10,000이 되면 버블 620ms vs 퀵 2.8ms로 벌어집니다.
import time
import random
def compare_sorting_algorithms(n):
arr = [random.randint(0, 10000) for _ in range(n)]
algos = {
"버블": bubble_sort,
"삽입": insertion_sort,
"퀵": quick_sort,
"병합": merge_sort,
}
print(f"\n--- n = {n} ---")
for name, fn in algos.items():
data = arr.copy()
start = time.time()
fn(data)
elapsed = (time.time() - start) * 1000
print(f"{name:4}: {elapsed:.2f} ms")
compare_sorting_algorithms(100)
compare_sorting_algorithms(1000)
compare_sorting_algorithms(10000)n=10,000 기준 결과:
- 버블 정렬: ~620ms
- 삽입 정렬: ~340ms
- 퀵 정렬: ~2.8ms
- 병합 정렬: ~3.8ms
상황별로 어떤 정렬을 써야 하나요?

상황에 따라 최적의 선택이 다릅니다.
실무에서는 대부분 퀵·병합 정렬 계열을 씁니다.
Python의 sorted()와 .sort()는 Timsort(삽입+병합 하이브리드)를 씁니다.
정리
- 버블 정렬 — O(n²), 가장 직관적, 학습 목적
- 삽입 정렬 — O(n²), 거의 정렬된 데이터엔 O(n)
- 퀵 정렬 — O(n log n) 평균, 실무에서 가장 빠름
- 병합 정렬 — O(n log n) 보장, 안정 정렬, Worst 없음