
[코딩테스트] 빈출 유형 4가지 — AI 시대에 코딩테스트가 웬말이냐
AI시대에 코딩과 코딩테스트가 웬말이냐는 생각도 있겠지만, 문제를 풀어보면서 접근 방식을 이해하면 AI에게 일을 더 잘 시킬 수 있을 거라고 생각합니다 ㅎㅎ 해시·그리디·분할정복·DP 빈출 유형 4가지를 같이 풀어봅니다.
시작하며 — AI가 다 해주는데 코딩테스트 왜 해요?
요즘 AI가 코드도 짜주고 버그도 잡아줍니다.
AI시대에 기업들은 왜 아직도 코딩테스트를 보고 있는걸까? 라고 생각하실 수도 있습니다.
그런데 코딩문제풀이나 테스트를 진행하다 보니 느낀 게 있습니다.
문제를 풀었느냐보다, 어떻게 접근했느냐가 나중에 일할 때나 다른 프로젝트할 때 요긴하게 쓰이는 것 같습니다.
물론 AI한테 "이 문제 풀어줘"라고 시킬 수도 있습니다.
그런데 "이 문제를 해시로 접근할지, DP로 접근할지" 판단하는 건
결국 제가 그 코드에 책임을 져야 하니까요.
문제를 풀어보면서 접근 방식을 이해하면 AI에게 일을 더 잘 시킬 수 있을 거라고
굳게 믿고 있습니다..ㅋㅋㅋ
그래서 이번 포스팅에서는 코딩테스트 빈출 4가지 유형을
접근법 중심으로 같이 풀어보려고 합니다.
* 알고리즘 1편(스택·큐·재귀), 2편(DFS·BFS)을 먼저 봤다면 더 빨리 감이 올 거예요.
해시 테이블에서 충돌이 나면 어떻게 하나요?
해시 테이블은 키를 해시 함수로 변환해서 빠르게 데이터를 저장하고 찾는 자료구조예요. 서로 다른 키가 같은 칸에 들어가는 충돌이 발생하면, 체이닝 방식으로 연결리스트를 이어붙여서 해결할 수 있습니다.
문제
크기가 5인 해시 테이블을 구현하세요.
키-값 쌍을 저장(set)하고 조회(get)할 수 있어야 하며,
해시 충돌이 발생할 경우 체이닝(Chaining) 방식으로 처리해야 합니다.
편의점 음료 냉장고를 떠올려보세요.
콜라는 A칸, 물은 B칸, 주스는 C칸 — 이렇게 칸을 정해두면 찾기가 빨라요.
해시 테이블도 똑같아요.
"키"를 넣으면 "칸 번호(인덱스)"가 나오는 함수가 있고,
그 칸에 값을 저장합니다.
그런데 문제가 하나 있어요.
서로 다른 키가 같은 칸에 들어가려고 하면?
이걸 "충돌(Collision)"이라고 하고, 해결 방법 중 하나가 체이닝(Chaining)입니다.
접근법 사고 과정
① 키를 해시 함수에 넣어서 인덱스를 얻는다
② 같은 인덱스에 이미 값이 있으면? → 연결리스트로 이어붙인다 (체이닝)
③ 검색할 때는 인덱스로 가서, 키를 비교해서 정확한 값을 찾는다
class HashTable:
def __init__(self, size=5):
self.size = size
self.buckets = [[] for _ in range(size)] # 체이닝용 리스트 배열
def _hash(self, key):
return sum(ord(c) for c in key) % self.size # 단순 해시 함수
def set(self, key, value):
idx = self._hash(key)
for pair in self.buckets[idx]:
if pair[0] == key:
pair[1] = value # 키가 이미 있으면 업데이트
return
self.buckets[idx].append([key, value]) # 없으면 추가 (체이닝!)
def get(self, key):
idx = self._hash(key)
for pair in self.buckets[idx]:
if pair[0] == key:
return pair[1]
return None
# 실행
ht = HashTable()
ht.set("apple", 3000) # 버킷 2
ht.set("mango", 2500) # 버킷 3
ht.set("banana", 1500) # 버킷 2 — 충돌! 체이닝으로 연결
print(ht.get("apple")) # 3000
print(ht.get("banana")) # 1500 — 체이닝 덕분에 정확히 찾음
"apple"과 "banana"가 같은 버킷 2에 들어갔지만,
체이닝 덕분에 둘 다 정확하게 찾을 수 있어요.
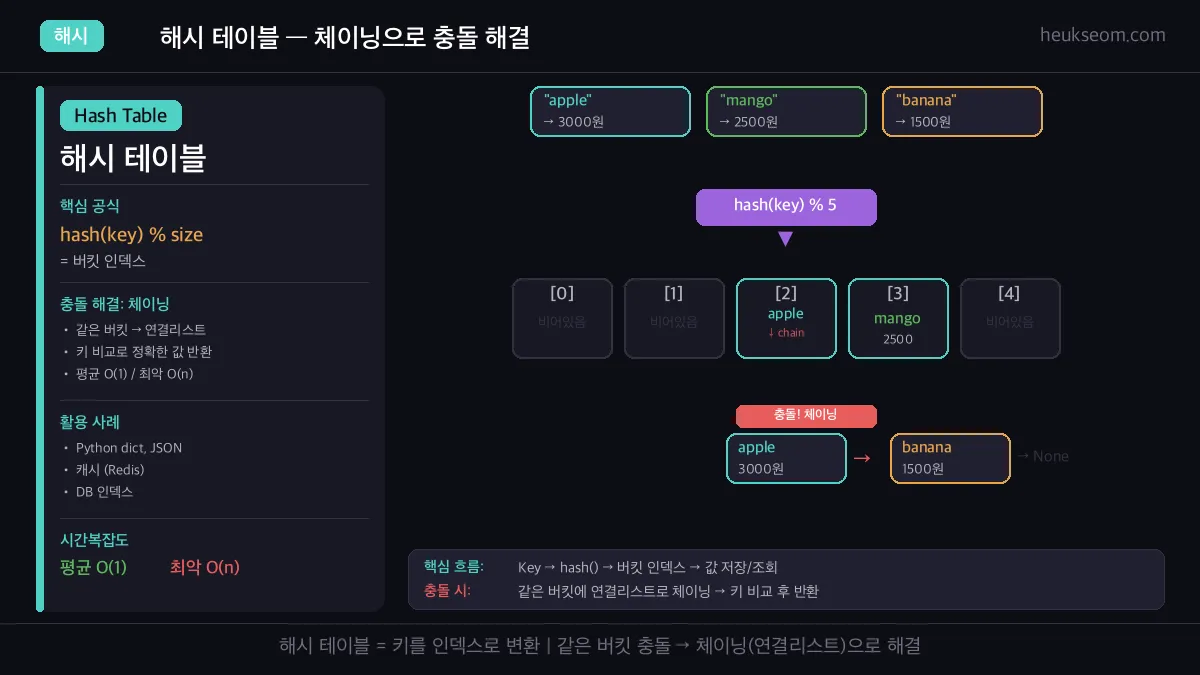
해시 함수 → 버킷 → 체이닝 과정. 같은 버킷에 들어간 apple과 banana가 연결리스트로 이어진다.
핵심 포인트: 해시 테이블은 평균 O(1)로 검색이 가능하지만,
충돌이 많아지면 O(n)까지 느려질 수 있어요.
좋은 해시 함수 + 적절한 테이블 크기가 중요합니다.
그리디 알고리즘으로 거스름돈을 어떻게 최소화하나요?
문제
거스름돈 amount원을 500원, 100원, 50원, 10원 동전으로 거슬러줄 때,
사용하는 동전의 수가 최소가 되도록 하세요.
각 동전별 사용 개수와 총 동전 수를 출력하세요.
편의점 알바를 한다고 상상해보세요.
손님한테 거스름돈 1,260원을 줘야 하는데,
동전 수를 최소로 하려면?
본능적으로 큰 동전부터 쓰시죠?
500원 → 100원 → 50원 → 10원 순서로.
이게 바로 그리디(Greedy) 알고리즘이에요.
"지금 당장 가장 좋아 보이는 선택"을 반복하는 거예요.
접근법 사고 과정
① 동전을 큰 것부터 정렬한다 (500, 100, 50, 10)
② 각 동전으로 가능한 만큼 최대한 사용한다
③ 남은 금액에 대해 다음 동전으로 반복한다
④ 남은 금액이 0이 되면 끝!
def coin_change_greedy(amount, coins=[500, 100, 50, 10]):
result = {}
for coin in coins:
count = amount // coin # 이 동전으로 몇 개 가능?
if count > 0:
result[coin] = count
amount -= coin * count # 남은 금액 갱신
print(f" {coin}원 x {count}개 | 남은 금액: {amount}원")
return result, sum(result.values())
# 실행
print("거스름돈: 1,260원")
coins_used, total = coin_change_greedy(1260)
# 출력:
# 500원 x 2개 | 남은 금액: 260원
# 100원 x 2개 | 남은 금액: 60원
# 50원 x 1개 | 남은 금액: 10원
# 10원 x 1개 | 남은 금액: 0원
print(f"총 동전 수: {total}개") # 6개
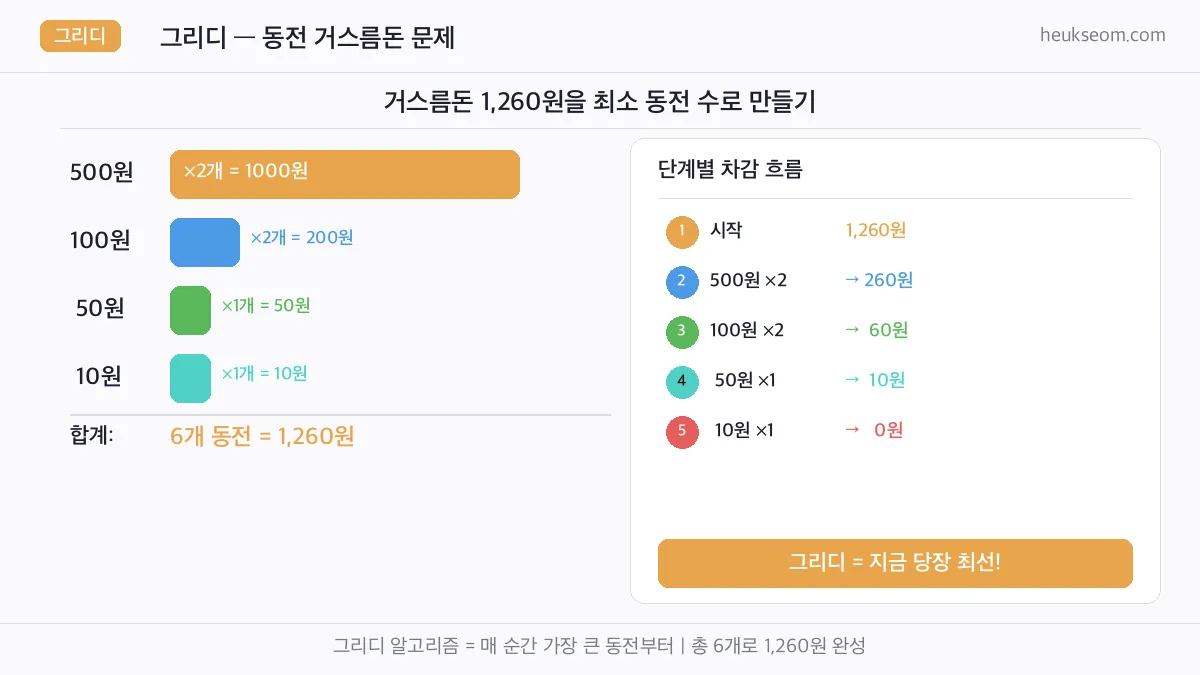
1,260원을 500원부터 차례로 — 매 순간 가장 큰 동전을 선택하는 그리디 전략.
주의할 점: 그리디가 항상 최적의 답을 주는 건 아니에요.
예를 들어 동전이 [500, 400, 100, 10]원이고 거스름돈이 800원이면,
그리디는 500+100+100+100 = 4개를 쓰지만, 실제 최적은 400+400 = 2개예요.
그리디는 "이 방법이 항상 최적인가?" 검증이 꼭 필요합니다.
분할 정복이란 어떤 접근법인가요?
문제
정수 배열 [38, 27, 43, 3, 9, 82, 10]이 주어졌을 때,
병합 정렬(Merge Sort)을 사용하여 오름차순으로 정렬하세요.
카드 52장을 정렬해야 한다고 해보세요.
한 번에 전부 정렬하면 머리가 아프죠?
그래서 이렇게 해요:
① 반으로 나누고 (26장씩)
② 각각 정렬한 다음 (재귀적으로 계속 반으로)
③ 정렬된 두 묶음을 합친다
이게 분할 정복(Divide & Conquer)이고,
대표적인 예가 병합 정렬(Merge Sort)이에요.
접근법 사고 과정
① Divide — 배열을 반으로 나눈다
② Conquer — 각 부분을 재귀적으로 정렬한다 (1개가 될 때까지)
③ Merge — 정렬된 두 배열을 비교하면서 합친다
def merge_sort(arr):
if len(arr) <= 1:
return arr # 원소 1개 = 이미 정렬됨
mid = len(arr) // 2 # ① 반으로 나누기
left = merge_sort(arr[:mid]) # ② 왼쪽 재귀 정렬
right = merge_sort(arr[mid:]) # ② 오른쪽 재귀 정렬
return merge(left, right) # ③ 합치기
def merge(left, right):
result = []
i = j = 0
while i < len(left) and j < len(right):
if left[i] <= right[j]: # 앞에서부터 비교해서 작은 것부터 넣기
result.append(left[i])
i += 1
else:
result.append(right[j])
j += 1
return result + left[i:] + right[j:] # 나머지 붙이기
# 실행
arr = [38, 27, 43, 3, 9, 82, 10]
print(f"원본: {arr}")
print(f"정렬됨: {merge_sort(arr)}")
# 출력: [3, 9, 10, 27, 38, 43, 82]
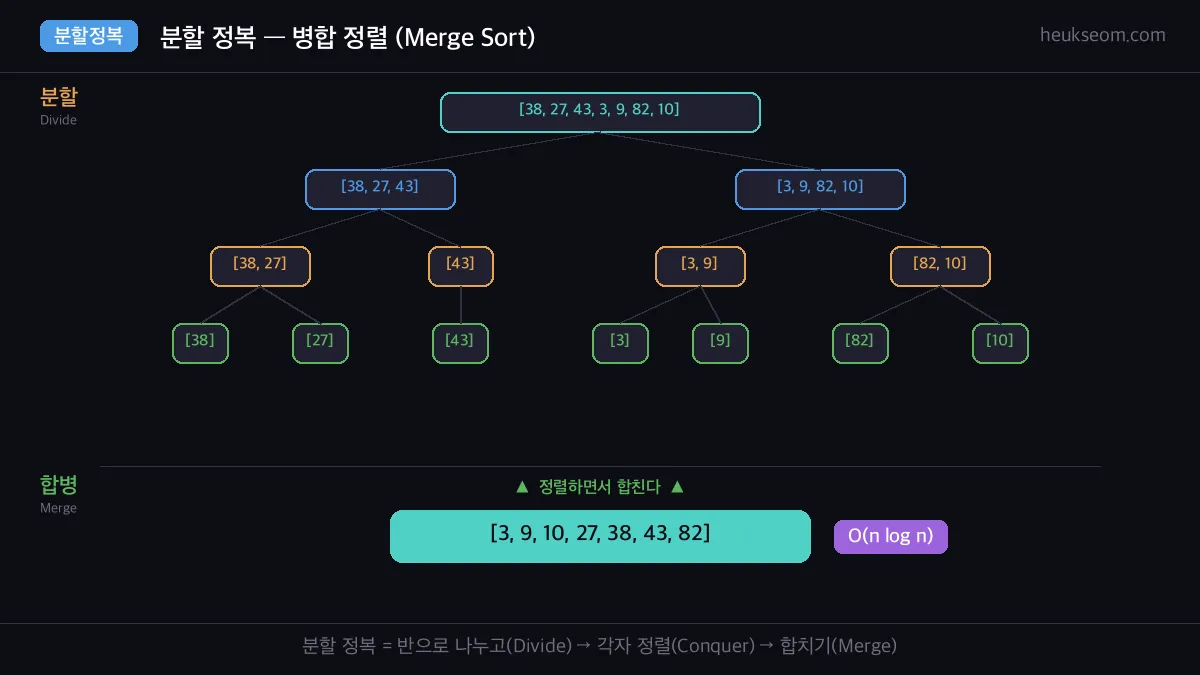
배열을 반으로 쪼개고(Divide), 각자 정렬한 뒤(Conquer), 합치면(Merge) 완성.
핵심 포인트: 병합 정렬의 시간 복잡도는 항상 O(n log n)이에요.
데이터가 이미 정렬돼 있든 완전히 뒤죽박죽이든 상관없이 안정적이에요.
다만 합치는 과정에서 추가 메모리(O(n))가 필요하다는 게 단점이에요.
다이나믹 프로그래밍은 뭐가 다른가요?
문제
피보나치 수열의 n번째 값을 구하세요.
단, 순수 재귀 방식과 DP(메모이제이션) 방식 두 가지로 구현하고,
n=35일 때 각각의 실행 시간을 비교하세요.
피보나치 수열 아시죠?
0, 1, 1, 2, 3, 5, 8, 13, 21 ...
앞의 두 수를 더하면 다음 수가 되는 규칙이에요.
재귀로 짜면 간단합니다. 그런데 문제가 하나 있어요.
fib(5)를 구하려면 fib(4) + fib(3)을 구해야 하고,
fib(4)를 구하려면 또 fib(3) + fib(2)를 구해야 해요.
같은 계산을 몇 번이나 반복하는 거예요!
다이나믹 프로그래밍(DP)은 이 문제를 해결합니다.
"이미 계산한 건 메모장에 적어두고 다시 안 푼다" — 이게 핵심이에요.
접근법 사고 과정
① 중복 계산이 있는지 확인한다 (fib(3)이 여러 번 호출됨!)
② 계산 결과를 메모(dict/배열)에 저장한다
③ 다음에 같은 값이 필요하면 메모에서 바로 꺼낸다
④ 기저 조건(fib(0)=0, fib(1)=1)을 설정한다
import time
# 방법 1: 순수 재귀 — 느림
def fib_recursive(n):
if n <= 1:
return n
return fib_recursive(n-1) + fib_recursive(n-2) # 중복 계산 폭발!
# 방법 2: DP 메모이제이션 — 빠름
def fib_dp(n, memo={}):
if n in memo:
return memo[n] # 저장된 값 바로 반환!
if n <= 1:
return n
memo[n] = fib_dp(n-1, memo) + fib_dp(n-2, memo) # 저장하면서 계산
return memo[n]
# 비교 실행
n = 35
t1 = time.time(); r1 = fib_recursive(n); t2 = time.time()
t3 = time.time(); r2 = fib_dp(n); t4 = time.time()
print(f"[재귀] fib({n}) = {r1} | 시간: {t2-t1:.4f}초")
print(f"[DP] fib({n}) = {r2} | 시간: {t4-t3:.6f}초")
# [재귀] fib(35) = 9227465 | 시간: 3.2초
# [DP] fib(35) = 9227465 | 시간: 0.0001초
같은 답인데 시간 차이가 어마어마하죠?
순수 재귀는 약 2,986만 번 계산하지만,
DP는 단 35번만 계산해요. 메모 하나로 이 차이가 나요.
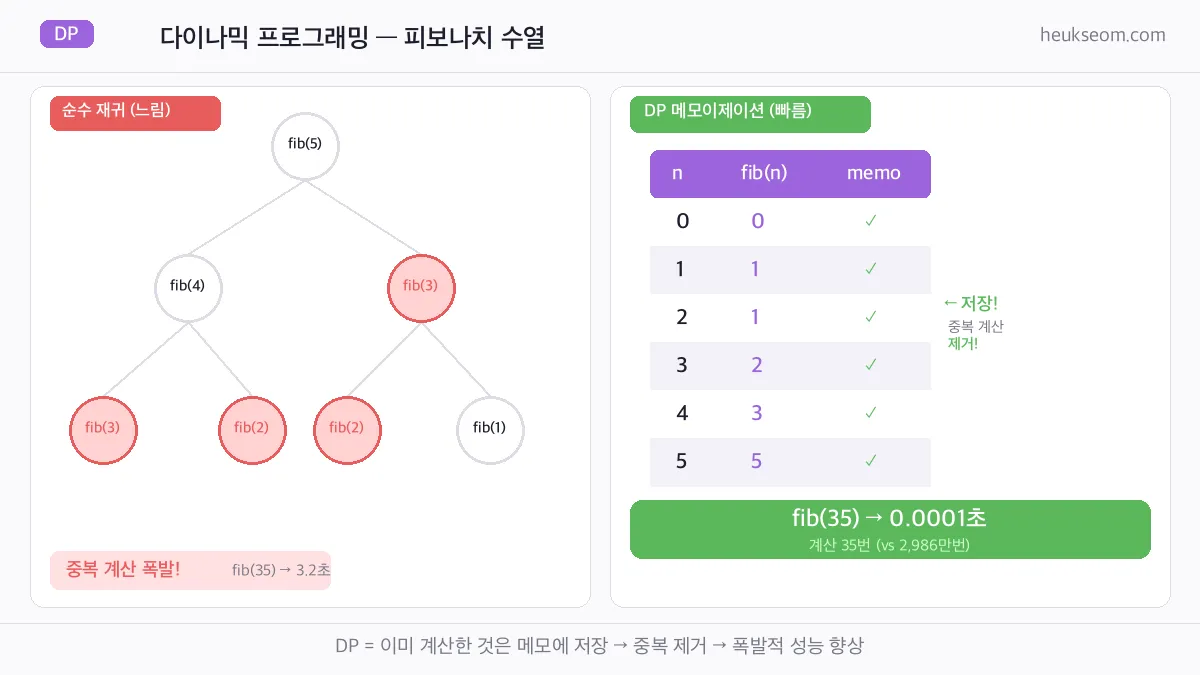
왼쪽: 순수 재귀 — 중복 계산 폭발(빨간색). 오른쪽: DP 메모 테이블 — 35번이면 끝.
정리 — 4가지 유형, 핵심 한 줄
- 해시 테이블: 키를 인덱스로 변환. 충돌나면 체이닝(연결리스트)으로 해결
- 그리디: 지금 당장 최선을 선택. 단, 항상 최적인지 검증 필요
- 분할 정복: 반으로 나누고 → 각자 해결 → 합치기. 병합 정렬이 대표
- DP: 이미 계산한 건 메모해두고 재활용. 중복 제거로 속도 폭발적 향상
코딩테스트 문제를 보면 제일 먼저 해야 할 건
"이 문제가 어떤 유형인지 파악하는 것"이에요.
유형을 알면 접근법이 보이고, 접근법이 보이면 코드는 따라옵니다.